No Permanent Friends or Enemies: Tracking Relationships between Nations from News
Understanding the dynamics of international politics is important yet challenging for civilians. In this work, we explore unsupervised neural models to infer relations between nations from news articles. We extend existing models by incorporating shallow linguistics information and propose a new automatic evaluation metric that aligns relationship dynamics with manually annotated key events. As understanding international relations requires carefully analyzing complex relationships, we conduct in-person human evaluations with three groups of participants. Overall, humans prefer the outputs of our model and give insightful feedback that suggests future directions for human-centered models. Furthermore, our model reveals interesting regional differences in news coverage. For instance, with respect to US-China relations, Singaporean media focus more on “strengthening” and “purchasing”, while US media focus more on “criticizing” and “denouncing”.
💡 Research Summary
The paper tackles the challenging problem of tracking the dynamics of international relations using news articles as the primary data source. Recognizing the limitations of supervised relation extraction—namely its reliance on predefined relation types and inability to capture emerging or nuanced interactions—the authors adopt an unsupervised neural approach, building upon the Relationship Modeling Network (RMN) introduced by Iyyer et al. (2016). Their central contribution is the Linguistically Aware Relationship Network (LARN), which enriches the original model with shallow linguistic cues: verbal predicates (verbs) that directly describe the interaction between two nations, and nouns/proper nouns that provide contextual background for those interactions.
Data are drawn from the NOW corpus, covering English‑language news from 20 countries between January 2016 and June 2018. The authors focus on twelve target nations (U.S., Russia, China, UK, Germany, Canada, France, India, Japan, Iran, Israel, Syria) and extract all sentences that mention any pair of these nations, yielding roughly 1.2 million sentences from 634 k articles. To capture linguistic information, they run spaCy’s dependency parser to identify predicates where both subject and object are present, and they collect accompanying nouns and proper nouns. On average each nation pair contributes about 21.6 k predicates and 201 k nouns.
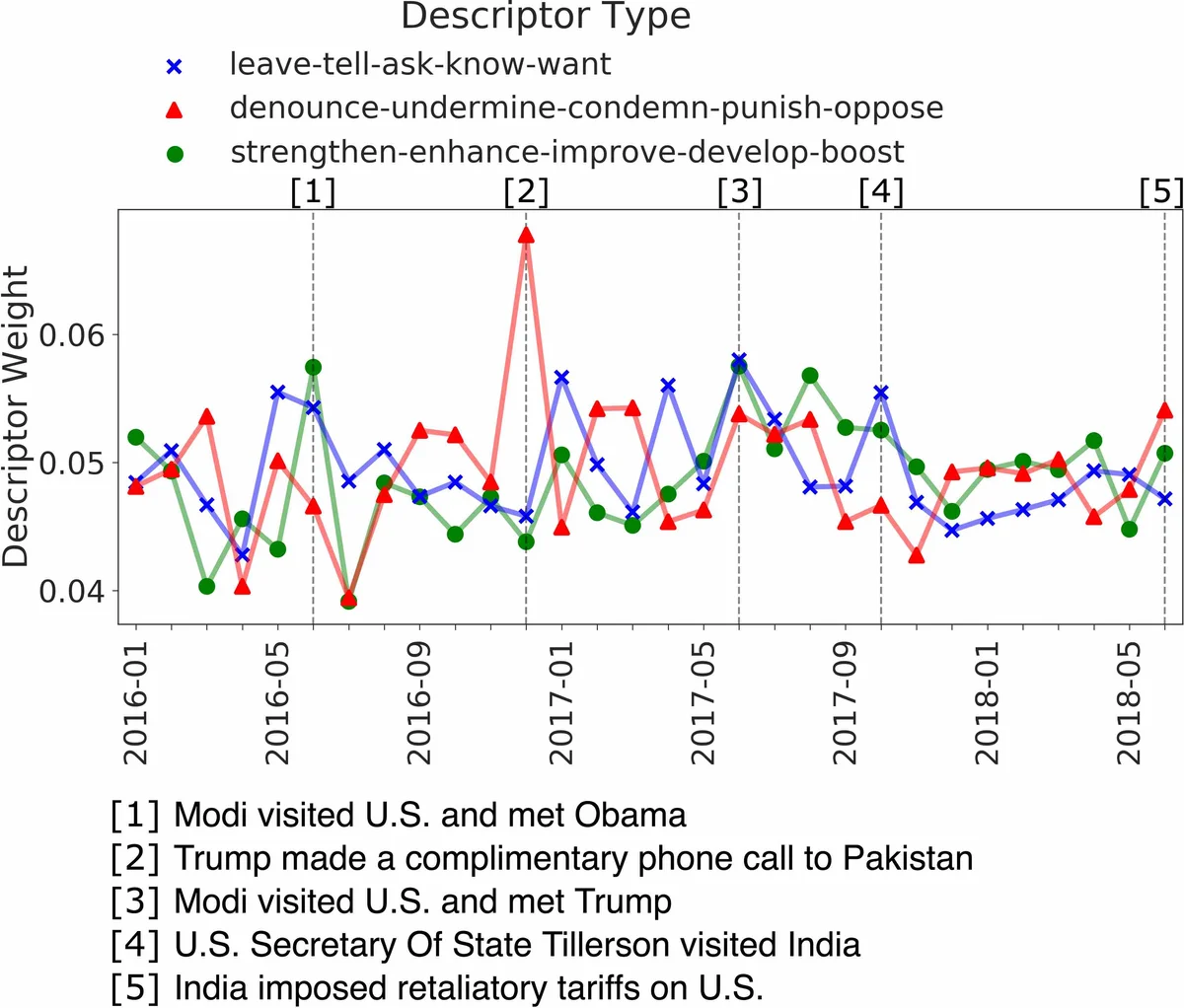
In addition to the large‑scale corpus, the authors manually annotate “key events” for eight of the most frequent nation pairs, identifying roughly five salient events per pair over the 30‑month period (e.g., Xi’s visit to the U.S. in April 2017 for US‑China). These annotations serve two purposes: they provide a grounding for a novel automatic evaluation metric that aligns model‑generated temporal relation trends with real‑world events, and they act as reference points during human user studies.
The LARN architecture proceeds as follows. Each extracted predicate and noun is represented by a static GloVe embedding. Predicate vectors for an article are summed (with a 0.5 dropout probability applied during training to prevent over‑reliance on any single verb). Noun vectors are first concatenated with a one‑hot month indicator, projected through a tanh‑activated linear layer, and then weighted by an attention mechanism. The attention query is a learned embedding specific to each nation pair, allowing the same noun to receive different importance scores depending on the countries involved. The resulting noun representation is a weighted sum of these transformed vectors.
A third component is the simple addition of the two nation embeddings, forming an entity‑pair vector. The three vectors—predicate sum, entity‑pair sum, and noun attention output—are concatenated, passed through a ReLU‑activated feed‑forward layer, and finally through a softmax to produce a distribution (d_a) over a fixed set of (K) relation embeddings (R). The article’s reconstructed representation (r_a = R^\top d_a) is then compared to the original predicate sum (v^{\text{label}}_a) using a contrastive max‑margin loss, supplemented by an auxiliary regularization term encouraging orthogonal relation embeddings. No explicit temporal dependencies (e.g., recurrent layers) are modeled; the authors argue that sudden shifts are more informative for international relations than smooth evolution.
For evaluation, the authors compare LARN against the original RMN. Both models are constrained to output 30 relation descriptors (the most probable relation types) per nation pair. Qualitatively, LARN’s top descriptors include semantically meaningful verbs such as “denounce”, “strengthen”, “negotiate”, whereas RMN’s top terms contain many function or content‑free words (“seem”, “thing”). Even the lowest‑weight descriptors from LARN remain interpretable, while RMN’s low‑weight terms are often noise.
Temporal trend visualizations further illustrate LARN’s superiority. For the US‑China pair, LARN captures a rise in “strengthen” during early 2017 (corresponding to trade talks) and a surge in “criticize”/“denounce” in late 2018 (reflecting trade tensions), aligning closely with the manually annotated key events. RMN’s trends are flatter and less aligned with real events.
Human evaluation involved three participant groups: NLP researchers, political‑science undergraduates, and linguistics undergraduates. In on‑site sessions, participants were shown relation descriptors and temporal plots, then asked to rate the usefulness and interpretability of each model’s output. Overall, 75.9 % of participants preferred LARN’s descriptors for describing international relations, and 85.5 % favored its temporal trends. Participants also provided qualitative feedback, noting that LARN’s attention‑based noun context helped disambiguate ambiguous predicates (e.g., “favor” in a tariff discussion).
The authors also conduct a regional analysis, demonstrating that Singaporean media emphasize “strengthening” and “purchasing” in US‑China coverage, whereas U.S. outlets focus more on “criticizing” and “denouncing”. This illustrates LARN’s capacity to surface subtle, geographically‑biased framing patterns in large news corpora.
Limitations acknowledged include the need to pre‑specify the number of relation embeddings (K) and their dimensionality, potential residual noise in noun attention (since many nouns are irrelevant to diplomatic relations), and the absence of explicit sequential modeling which might capture long‑term trends. The authors suggest future work incorporating multilingual news sources, social‑media streams, and interactive interfaces that allow users to inject or adjust key events, thereby creating a more collaborative human‑AI system for international‑relations analysis.
In summary, the paper presents a novel unsupervised neural framework that leverages shallow linguistic cues to produce more interpretable and temporally accurate representations of nation‑to‑nation relationships from news text. Through a combination of automatic alignment with annotated events and thorough human user studies, the authors demonstrate that LARN outperforms prior unsupervised baselines and offers actionable insights into how different media ecosystems frame global affairs.
Comments & Academic Discussion
Loading comments...
Leave a Comment