Towards Vulnerability Analysis of Voice-Driven Interfaces and Countermeasures for Replay
Fake audio detection is expected to become an important research area in the field of smart speakers such as Google Home, Amazon Echo and chatbots developed for these platforms. This paper presents replay attack vulnerability of voice-driven interfaces and proposes a countermeasure to detect replay attack on these platforms. This paper presents a novel framework to model replay attack distortion, and then use a non-learning-based method for replay attack detection on smart speakers. The reply attack distortion is modeled as a higher-order nonlinearity in the replay attack audio. Higher-order spectral analysis (HOSA) is used to capture characteristics distortions in the replay audio. Effectiveness of the proposed countermeasure scheme is evaluated on original speech as well as corresponding replayed recordings. The replay attack recordings are successfully injected into the Google Home device via Amazon Alexa using the drop-in conferencing feature.
💡 Research Summary
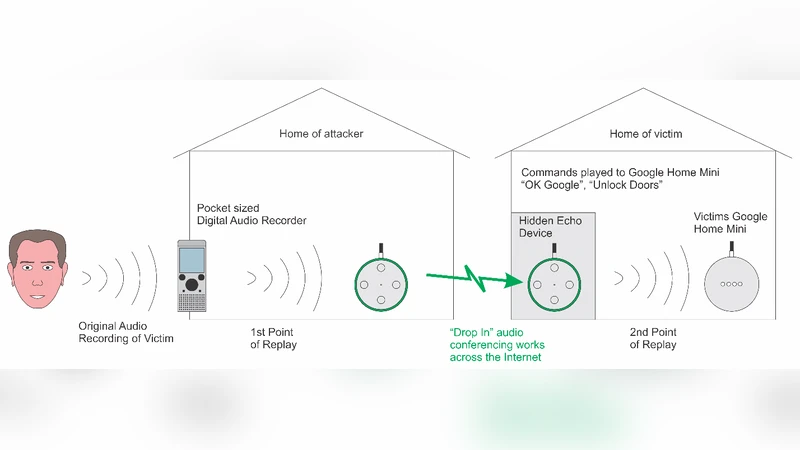
The paper investigates the security of voice‑driven smart speakers, focusing on replay (RA) attacks against the automatic speaker verification (ASV) components of Amazon Echo and Google Home. Through three practical experiments the authors demonstrate that both devices rely only on a wake‑word check (e.g., “Alexa” or “OK Google”) and do not perform speaker verification on subsequent commands. Consequently, a pre‑recorded command can be replayed to control IoT devices, make purchases, or retrieve personal information. In the first experiment, a replayed “Alexa, Who am I?” query on an Echo returns the owner’s name, showing that the device cannot distinguish a live voice from a recording. In the second experiment, a Google Home device accepts a recorded wake‑word followed by a different voice issuing a purchase request, confirming that only the wake‑word is verified. The third experiment exploits the Drop‑In audio‑conferencing feature of Amazon Alexa to remotely stream a replayed command to a Google Home, successfully turning lights on and off. These results expose a fundamental weakness in current commercial smart‑speaker ASV implementations.
To address this vulnerability, the authors propose a theoretical model of the replay chain as a microphone‑speaker‑microphone (MSM) system that introduces high‑order nonlinearities (beyond the 6th order). They argue that the physical processes of microphone and speaker distortion generate harmonic, inter‑modulation (IM), and difference‑frequency components that can be captured by higher‑order spectral analysis (HOSA). Specifically, they use the bispectrum (the 2‑D Fourier transform of the third‑order cumulant) and its normalized form, bicoherence, as the primary feature. Bicoherence reveals phase coupling between frequency components; in a nonlinear system, IM products cause elevated magnitude and characteristic phase values (near 0 or π/2) at specific frequency pairs.
The detection framework combines three statistical measures derived from HOSA: (1) Quadratic Phase Coupling (QPC) magnitude to quantify IM distortion, (2) Hinich’s Gaussianity test, which checks whether third‑order cumulants vanish (a zero bispectrum indicates Gaussianity), and (3) a linearity test that distinguishes constant‑nonzero bispectra (linear non‑Gaussian) from varying bispectra (non‑linear). By applying binary hypothesis testing (H0: bispectrum constant and non‑zero; H1: bispectrum non‑constant), the system can flag replayed audio without any machine‑learning training.
Experimental validation uses 12 original voice commands, each replayed twice (first‑order and second‑order replays) to generate 24 replay samples. Audio is segmented with 1024‑point FFT, 50 % overlap, and Rao‑Gabr windowing. The bispectrum magnitude and phase are estimated for each segment. Results show a consistent increase in bicoherence magnitude and a shift of phase toward 0/π/2 for replayed recordings compared with the original speech. Gaussianity and linearity tests also indicate non‑Gaussian, non‑linear characteristics in the replayed signals, confirming the efficacy of the proposed features.
The paper’s contributions are threefold: (i) empirical proof that commercial smart speakers are vulnerable to simple replay attacks, (ii) a novel high‑order nonlinearity model of the replay chain, and (iii) a non‑learning, HOSA‑based detection method that directly exploits physical distortion rather than statistical patterns learned from data. The approach avoids the need for large labeled datasets and can be implemented with relatively low computational overhead.
However, the study has limitations. The experiments are confined to specific hardware models and indoor acoustic conditions; broader testing across diverse microphones, speakers, and environmental noises is needed to assess generalizability. The high‑order model does not explicitly account for additional channel effects such as compression codecs, network latency, or adaptive filtering, which may alter the bispectral signatures. Moreover, while the method is robust against pure replay, it remains untested against hybrid attacks that combine synthesis (e.g., voice‑conversion) with replay, or against adversaries who could deliberately manipulate the nonlinear characteristics to evade detection.
In summary, the work highlights a critical security gap in voice‑controlled IoT ecosystems and introduces a physics‑driven, non‑machine‑learning countermeasure based on higher‑order spectral analysis. It provides a valuable foundation for future research on robust, real‑time replay‑attack detection and informs the design of more secure ASV modules for next‑generation smart speakers.
Comments & Academic Discussion
Loading comments...
Leave a Comment