Consistency by Agreement in Zero-shot Neural Machine Translation
Generalization and reliability of multilingual translation often highly depend on the amount of available parallel data for each language pair of interest. In this paper, we focus on zero-shot generalization—a challenging setup that tests models on translation directions they have not been optimized for at training time. To solve the problem, we (i) reformulate multilingual translation as probabilistic inference, (ii) define the notion of zero-shot consistency and show why standard training often results in models unsuitable for zero-shot tasks, and (iii) introduce a consistent agreement-based training method that encourages the model to produce equivalent translations of parallel sentences in auxiliary languages. We test our multilingual NMT models on multiple public zero-shot translation benchmarks (IWSLT17, UN corpus, Europarl) and show that agreement-based learning often results in 2-3 BLEU zero-shot improvement over strong baselines without any loss in performance on supervised translation directions.
💡 Research Summary
The paper tackles the problem of zero‑shot translation in multilingual neural machine translation (NMT), where a model must translate between language pairs that were never seen together during training. The authors first formalize multilingual translation as a probabilistic inference problem: each language is a node in a directed graph, supervised translation pairs correspond to edges with parallel data, and zero‑shot pairs are edges without data. Standard multilingual NMT, exemplified by Johnson et al. (2016), optimizes a composite likelihood that only sums log‑probabilities over supervised edges. While this approach enables parameter sharing and yields some zero‑shot capability, it provides no statistical guarantee that low error on supervised edges translates into low error on unseen edges.
To address this gap, the authors introduce the notion of zero‑shot consistency: a model is zero‑shot consistent if a small supervised loss (ε) implies a small zero‑shot loss (κ(ε)), with κ(ε) → 0 as ε → 0. They then propose an agreement‑based training objective that explicitly couples the latent translations into auxiliary languages across opposite translation directions. Concretely, for a pair of languages (e.g., English–French) they introduce latent variables representing translations into two auxiliary languages (Spanish and Russian). The traditional composite likelihood treats the two directions independently; the agreement objective instead multiplies the joint probabilities of the auxiliary translations, encouraging the model to produce the same intermediate sentences regardless of the source language.
Because summing over all possible auxiliary sentences is intractable, the authors apply Jensen’s inequality to obtain a lower bound expressed as cross‑entropy terms. In practice they replace sampling with greedy, length‑controlled decoding, which makes the auxiliary sentences differentiable with respect to model parameters. The final loss combines the standard supervised log‑likelihood with the agreement term, weighted by a coefficient γ.
Theoretical analysis culminates in Theorem 2, which proves that if the expected agreement loss for two supervised edges (L₁↔L₂ and L₂↔L₃) is bounded, then the zero‑shot edge (L₁↔L₃) inherits a bounded cross‑entropy under mild assumptions about the true data distribution. Hence, maximizing the agreement‑based likelihood yields a model that is provably zero‑shot consistent.
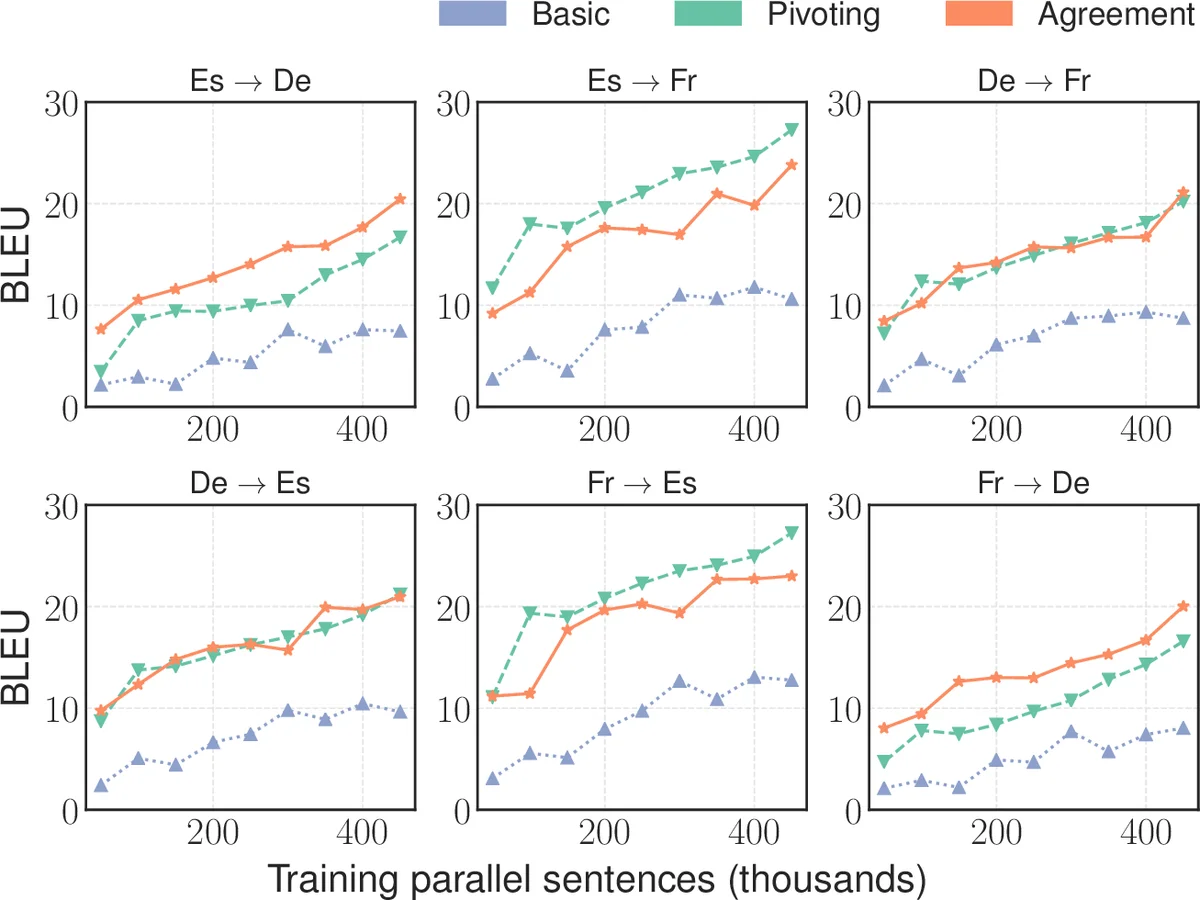
Empirically, the authors evaluate on three public benchmarks—IWSLT‑17, the UN corpus, and Europarl—systematically removing all “pivot” parallel data so that certain language pairs are truly zero‑shot. They compare three baselines: (1) the vanilla Johnson et al. multilingual model, (2) pivot‑based chain translation, and (3) recent methods such as pivot voting, dual‑learning fine‑tuning, and knowledge‑distillation approaches. The agreement‑based model consistently improves zero‑shot BLEU scores by 2–3 points over the vanilla baseline, matching or surpassing the more complex alternatives, while maintaining or slightly improving performance on supervised directions. Ablation studies show that the improvement scales with the agreement coefficient γ, but overly large γ can hurt supervised performance, confirming the need for a balanced trade‑off.
The paper’s contributions are threefold: (1) a clear probabilistic formulation of multilingual NMT and a formal definition of zero‑shot consistency; (2) an agreement‑based training objective that ties together translations through auxiliary languages and is provably consistent; (3) extensive experiments demonstrating that the method yields practical gains without additional inference overhead or separate models. The approach bridges ideas from composite likelihood, agreement‑based learning in statistical MT, and knowledge distillation, offering a simple yet theoretically grounded way to make multilingual NMT more robust in low‑resource, zero‑shot scenarios. Future work could explore dynamic selection of auxiliary languages, scaling to larger language sets, or integrating the method with unsupervised back‑translation techniques.
Comments & Academic Discussion
Loading comments...
Leave a Comment