Short utterance compensation in speaker verification via cosine-based teacher-student learning of speaker embeddings
The short duration of an input utterance is one of the most critical threats that degrade the performance of speaker verification systems. This study aimed to develop an integrated text-independent speaker verification system that inputs utterances with short duration of 2 seconds or less. We propose an approach using a teacher-student learning framework for this goal, applied to short utterance compensation for the first time in our knowledge. The core concept of the proposed system is to conduct the compensation throughout the network that extracts the speaker embedding, mainly in phonetic-level, rather than compensating via a separate system after extracting the speaker embedding. In the proposed architecture, phonetic-level features where each feature represents a segment of 130 ms are extracted using convolutional layers. A layer of gated recurrent units extracts an utterance-level feature using phonetic-level features. The proposed approach also adopts a new objective function for teacher-student learning that considers both Kullback-Leibler divergence of output layers and cosine distance of speaker embeddings layers. Experiments were conducted using deep neural networks that take raw waveforms as input, and output speaker embeddings on VoxCeleb1 dataset. The proposed model could compensate approximately 65 % of the performance degradation due to the shortened duration.
💡 Research Summary
The paper addresses a critical problem in speaker verification: the severe degradation of performance when the input utterance is very short (≤ 2 seconds). While prior work has attempted to mitigate this issue by post‑processing i‑vectors or speaker embeddings after they have been extracted, such approaches are limited because they cannot recover phonetic information that was lost during the initial feature extraction stage.
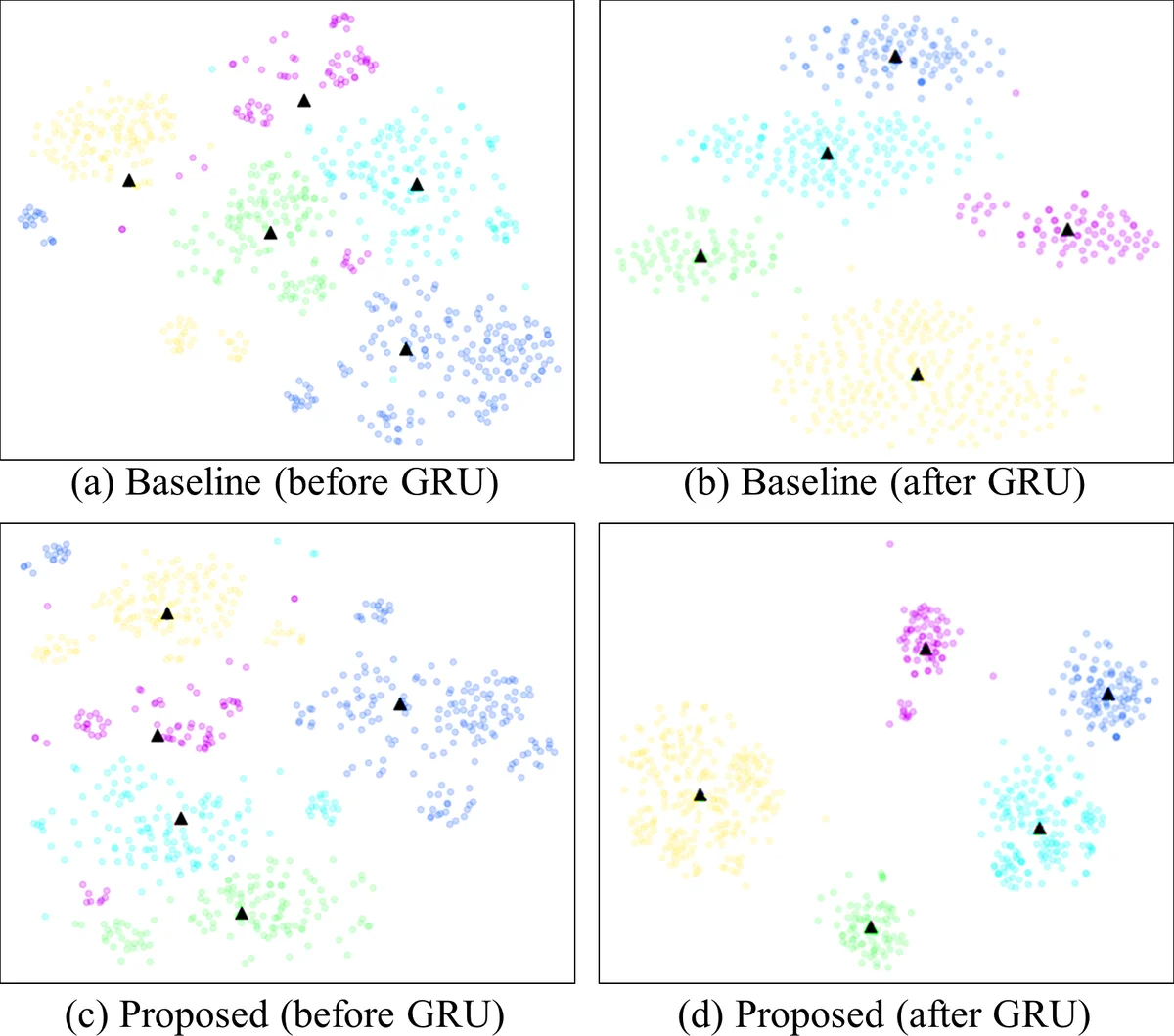
To overcome this limitation, the authors propose an end‑to‑end teacher‑student (TS) learning framework that performs compensation throughout the embedding network, focusing especially on the phonetic‑level representations. In their architecture, raw waveforms are fed into a convolutional‑GRU (CNN‑GRU) model. The convolutional blocks, equipped with residual connections and max‑pooling, produce a sequence of “phonetic‑level” features, each representing roughly 130 ms of speech – a duration traditionally considered sufficient to capture phonetic content. The number of such features depends on the utterance length (e.g., 27 for 3.59 s, 15 for 2.05 s). These features are then aggregated by a GRU layer to generate a fixed‑dimensional utterance‑level speaker embedding, which is finally passed through a fully‑connected layer with LReLU activation.
The teacher network is trained on long utterances (≈ 3.59 s) and its parameters are frozen. The student network, identical in architecture but receiving short utterances (≈ 2.05 s), is trained to mimic the teacher. Unlike conventional TS learning that only aligns the softmax output distributions via Kullback‑Leibler (KL) divergence, the proposed method adds a second term that directly aligns the speaker embeddings of teacher and student. The combined loss function is:
Loss = Σ_j Dist(e_T, e_S) – Σ_j Σ_i p_T(s_i|x_j^l) log p_S(s_i|x_j^sh)
where Dist(·,·) can be cosine distance or mean‑squared error, e_T and e_S are the teacher and student embeddings, and the KL term preserves discriminative power at the classification layer.
Experiments were conducted on the VoxCeleb1 dataset. Baseline performance with the raw CNN‑GRU model yields an equal error rate (EER) of 7.51 % on unrestricted utterances (average length 3–7 s). When the evaluation utterances are truncated to 2.05 s, the EER rises to 12.80 % – a 46 % relative degradation. Training the same model directly on short utterances improves the EER only modestly to about 12.08 % (≈ 5 % relative reduction).
Applying the proposed TS learning yields the following results: using only the embedding distance term (cosine or MSE) reduces the EER to roughly 10.8 %–10.98 %; incorporating both the embedding distance and the KL‑divergence term further reduces the EER to 8.72 %. This final figure corresponds to a recovery of more than 65 % of the performance loss caused by short utterances. The authors interpret this improvement as evidence that (1) aligning embeddings alone brings the short‑utterance representation closer to the long‑utterance counterpart, but without the KL term the discriminative structure of the embedding space may be distorted; (2) the KL term stabilizes the classifier’s decision boundaries, preserving speaker separability.
Key contributions of the work include:
- Introducing a phonetic‑level compensation strategy that operates inside the embedding network rather than as a post‑hoc transformation.
- Designing a dual‑objective loss that simultaneously minimizes embedding distance (cosine) and KL divergence of output logits, thereby balancing compensation and discriminative power.
- Demonstrating, on a large‑scale public dataset, that the method can recover a substantial portion of the degradation caused by utterances as short as 2 seconds.
The paper also discusses limitations and future directions. The experiments are confined to a single language and recording condition (VoxCeleb1), so cross‑language and far‑field robustness remain to be validated. Moreover, the current implementation uses GRU for temporal modeling; exploring Transformer‑based encoders or other sequence models could further improve performance. Finally, real‑time deployment scenarios with variable‑length streaming audio would benefit from additional studies on duration‑invariant training and inference strategies.
In summary, the proposed cosine‑based teacher‑student learning framework provides an effective, end‑to‑end solution for short‑utterance speaker verification, achieving notable performance gains by integrating phonetic‑level compensation directly into the deep embedding network.
Comments & Academic Discussion
Loading comments...
Leave a Comment