WaveCycleGAN2: Time-domain Neural Post-filter for Speech Waveform Generation
WaveCycleGAN has recently been proposed to bridge the gap between natural and synthesized speech waveforms in statistical parametric speech synthesis and provides fast inference with a moving average model rather than an autoregressive model and high…
Authors: Kou Tanaka, Hirokazu Kameoka, Takuhiro Kaneko
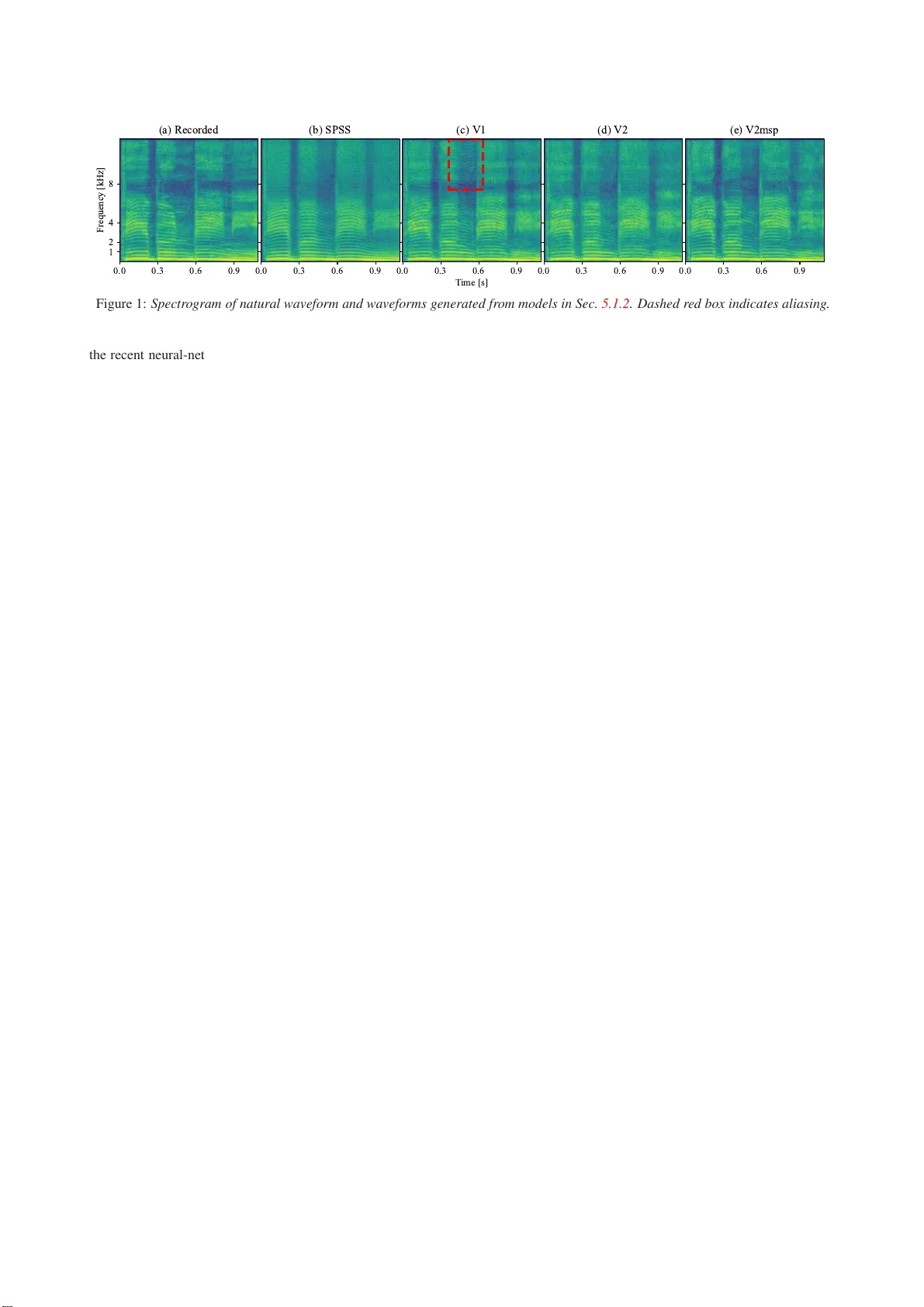
W a veCycleGAN2: Time-domain Neural Post-filter f or Speech W a vef orm Generation K ou T anaka, Hir okazu Kameoka, T akuhir o Kaneko, Nobukatsu Hojo NTT Communicati o n Science Laboratories, NTT Corporation, Japan { kou.tanaka.ef, hirokazu.kam eoka.uh, takuhiro.kane ko.tb, nobukatsu.hou jou.ae } @hco.ntt. co.jp Abstract W aveCycleGAN has recently been proposed to bridge the gap between natural and synthesized speech wav eforms in statisti- cal parametric speech syn thesis and provides fast inference with a moving averag e model rather than an autore gressiv e model and high-quality speech synthesis with the a dversarial t r ain- ing. Ho wev er , the human ear can still distinguish the processed speech wave forms f r om natural ones. One possible cause of this distinguishability is t he al i asing observed in the processed speech wa veform via do wn/up-sampling modules. T o solve the aliasing and prov ide higher quality speech synthesis, we propose W aveCycleGAN2, which 1) uses generators without do wn/up-sampling modules and 2) combines discriminators of the wav eform domain and acoustic parameter domain. The re- sults sho w that the proposed method 1 1) alle viates the alias- ing w el l , 2) i s useful for both speech wav eforms generated by analysis-and-syn thesis and statistical parametric speech synthe- sis, and 3) achiev es a mean opinion score comparable to those of natural speech and speech synthesized by W av eNet [ 1 ] (open W aveNet [ 2 ]) and W av eGlo w [ 3 ] w hil e processing speec h sam- ples at a rate of more than 150 kHz on an NVIDIA T esla P100. Index T erms : speech synthesis, generativ e models, deep learn- ing, vocoder , text-to-speech 1. Intr oduction Speech processing systems using classical parametric v ocoder frame works such as STRAIGHT [ 4 , 5 ] and WORLD [ 6 ] are popular frame works for v arious tasks such as statistical para- metric speech synthesis (SPS S ) [ 7 ] and st ati stical voice con ver- sion (VC) [ 8 ]. The key adv antage of using the classical para- metric vocoder frame works is that speech signals can be repre- sented by interpretable and compact acoustic parameters such as the fundamental f r equenc y ( F 0 ) and Mel-cepstrum rather than a short-term Fourier transform (STF T) spectrogram. On the other hand, the cri tical dra wback is that the generated speech can usually be distinguished from natural speech due to vocod- ing error [ 9 ], ev en through we only re-synthesize the speech wa veform from the analyzed acoustic parameter . Moreo ver , op- erating acoustic parameters and their statisti cs in SPSS and VC usually leads to an ov er-smoothing ef fect [ 9 ] and increases the differe nces between synthetic and natural speech. T o address these drawbacks , w e pre viously proposed a learning-based fil t er of the time-domain, called W aveCycle- GAN [ 10 ], which allows us to con vert a synthetic speech wave- form into a natural speech wav eform using cycle-consistent ad- versarial networks with a fully con volutional architecture. The difficu lties of the wa veform con version within the deep learn- ing approac hes are the dif ficulty of parallel data collection of speech waveform and the ambig uity of the phase information of speech wa veform. Notably , the phase ambiguity preven ts 1 Audio samples can be accessed on our web page: www .kecl.ntt.co .jp/people /tanaka.ko/projects/wa vecyclegan2/inde x. html proper learning of a mapping function from synthetic speech to natura l speech (e.g., when we ha ve t wo speech wav eforms with certain phase spectra and the re versed phase spectra in the training data of natural speech, minimizing the objective func- tion results in con verting to silence). The cyclic model makes it possible to address these difficulties of the operating wa ve- form. Moreove r , W av eCycleGAN is trained within the adver - sarial learning, so no explicit assumption against speech wav e- form is required. As a result, by applying W av eCycleGAN to SPSS trained for a Japanese dataset, the filtered speech has achie ved a mean op inion score higher than 4. Howe ver , there is still a gap between natural speech and filtered speech. In the preliminary experiment, by applying W aveCycleGAN to the speech wa veform synth esized from acoustic parameters of nat- ural speech, t he filtered speech was l o wer quality than the input of W av eCycleGAN. W e found that one possible reason for the differe nce and degradation in quality is the aliasing observed i n the fi ltered speech wav eform via down/up -sampling modules in model architectures. T o bridge the gap including the aliasing, we propose W ave- CycleGAN2, which is an improved variant of W av eCycleGAN that 1) uses generators without do wn/up-sampling modules and 2) combines discriminators of the wavefo rm domain and acous- tic parameter domain such as Mel-spectrogram, Mel-frequency cepstral coef ficients, and phase spectrum. W e analyzed the ef- fect of each t echnique on an internal Japanese speech dataset 2 and a public domain English speech dataset [ 12 ]. Experimental e valua tions sho wed t hat t he proposed method 1) alleviates the aliasing well, 2) is useful for both speech wa veforms generated by analysis-and-synthesis (AnaSyn) and SPSS , and 3) achie ves a mean opinion score comparable t o those of natural speech and speech synthesized by W aveNet [ 1 ] (open W aveNet [ 2 ]) and W aveGlo w [ 3 ] while processing audio samples at a rate of more than 150 kHz on an NV I DIA T esla P100. 2. Related W orks 2.1. V ocoder for W ave form Generation T o generate a speech wav eform from given acoustic param- eters, neural-netw ork-based wa veform models [ 1 , 3 , 13 , 14 ] hav e been proposed and hav e performed outstandingly at nu- merous t asks inv olving speech signal processing. There are two types of neural-network -based wa veform models: an au- toregressi ve (AR) model [ 1 , 13 ] and a moving -avera ge (MA) model [ 3 , 14 ] (a.k.a., non-AR model). As an AR model, al- though the W aveNet [ 1 ] synthesizes speech wi th high fidelity , its training procedure is complex 3 and its inference speed is quite slow because the AR process nev er allows us t o infer sev- eral wav eform sampling points i n parallel. 2 On our web page, we used an alternati ve spee ch dataset, the CMU Arctic database [ 11 ], which allows us to publish 3 Generat ed speech sometimes coll apses as report ed by Wu et al. [ 15 ]. For MA models that allo w us to parallelize the inference, distilled models [ 16 , 17 ] demanding complex training criteria hav e also been proposed. T o avo id t he complex training crite- ria, W av eGlo w [ 3 ] is a t heoretically po werful model that has the t ractability of the exact log-lik elihood. Although W av eG- lo w makes it possible t o train the t heoretically exact mapping function by using only one criterion, it requires large-scale com- putational r esources and long training time. T o mak e the infer- ence procedure interpretable, a neural source filter model [ 14 ] has also been propo sed as an MA model. All t hese models can work well i f the given acoustic parameters are close to natural ones seen i n the training data. Otherwise, the training procedure has to be seve ral steps rather than one step becau se it is com- bined with other training procedures such as fine-tuning [ 18 ] or methods described in the next subsection. In contrast, ev en if the giv en acoustic parameters are not close to natural ones in the training data, our approach, which i s a kind of the MA model, mak es it possible to directly train the mapping function from the generated speech wave form to the natural one in one step because it all o ws the use of a classical parametric vocoder that is not necessary to train. 2.2. Acoustic Parameter Generation/Modifi cation T o address the over-sm oothing ef fect [ 9 ], se veral techniques hav e been proposed [ 8 , 19 , 20 ] to restore the fine structure of acoustic parameters of natural speech 4 . In their respec- tiv e directions, these approaches have si gnificantly improv ed the naturalness of acoustic parameters generated by SPS S and VC. Howe ver , these approaches are sti l l insufficient to gener - ate natural-sounding speech because of the post-filter of acous- tic parameters on the heuristically limited compact space ev en in the generativ e adversarial nets (GAN) based approach [ 20 ]. Moreo ver , it is impossible t o address the vocod ing error [ 9 ] when we use the classical parametric vocoder to generate the speech wa veform. In contrast, our approa ch all ows us to ad- dress both the ov er-smoothing effect and vocoding error be- cause of the process ing aft er waveform generation processing. 3. Con ventional W av eCycleGAN W e briefly r evie w our pre vious work, W av eCycleGAN [ 10 ], which is a kind of cyclic model (a.k.a., dual learning [ 24 ]). Let us use one-dimensional vectors x and y to denote sequences belonging to sets of synthetic X and natural Y speech wav eforms, respecti vely . Inspired by CycleGAN [ 25 ], W aveCycleGAN uses three training criteria (adversarial loss L adv [ 26 ], cycle-consistency l oss L cyc [ 27 ], and i dentity- mapping loss L id [ 28 ]) to train a mapping function G X → Y that con verts the wav eform of synthetic speech into that of natural speech without relying on parallel data. The adversarial l oss is written as, L adv ( G X → Y ,D Y ) = E y ∼ P Y ( y ) [log D Y ( y )] + E x ∼ P X ( x ) [log(1 − D Y ( G X → Y ( x )))] , (1) where D Y indicates a discriminator trying to differentiate be- tween a real sample y and the samples G X → Y ( x ) con verted by the generator G X → Y while G X → Y is trained for conv ert- ing x to G X → Y ( x ) that can deceive D Y as y . This criterion focuses on only whether i t can deceiv e D Y or not, so x might be con verted into samples that have dif ferent linguistic infor- mation. T o retain the linguistic information of the input x , the 4 Of course, accurate modeling approaches have also been proposed, such as gene rati ve adversari al netw ork-based text-t o-speech [ 21 , 22 ] and voic e conv ersion [ 23 ]. cycle-con sistency and identity-mapping losses are used: L cyc = E x ∼ P X ( x ) [ || G Y → X ( G X → Y ( x )) − x || 1 ] + E y ∼ P Y ( y ) [ || G X → Y ( G Y → X ( y )) − y || 1 ] , (2) L id = E y ∼ P Y ( y ) [ || G X → Y ( y ) − y || 1 ] + E x ∼ P X ( x ) [ || G Y → X ( x )) − x || 1 ] , (3) where G Y → X indicates another generator that has t he r everse direction to G X → Y . Note that to guide the learning direction, L id is usually used only in the early stage of the training. Finally , the full objectiv e f unction can be written as L full = L adv ( G X → Y , D Y ) + L adv ( G Y → X , D X ) + λ cyc L cyc + λ id L id , (4) where λ cyc and λ id indicate hyperparameters controlling the cycle-con sistency and identity-mapping losses. 4. Pr oposed W a veCycleGAN2 4.1. Aliasing Issue of C onv entional W av eCycleGAN Many model architectures using con volutional neural net- works inv olve down/up-samp ling modules as t he de facto stan- dard [ 29 – 32 ] because it has a significant advantage in terms of the computation amount. W e also adopted conv olution with strides to W aveCycleGAN because of its compu tational adv an- tage. As a result, we achie ved a mean opinion score higher than 4 in terms of the naturalness. Howe ver , we found that aliasing is observ ed i n the processed speech w ave form, as sho wn in Fig. 1 (c). This phenomen on has also been r eported in sev eral other tasks such as i mage classifi cation [ 33 ] and deep speech pro- cessing [ 34 ]. T he aliasing occurs when the Nyqu ist-Shannon sampling theorem [ 35 ] is not satisfied, so it follows that the classical con volution with strides i s not guaranteed to satisfy the sampling theorem. This is reasonab le because the cl assi- cal con volution with strides i s not guaranteed to hav e an anti- aliasing mechanism while we ne ver perform down-sam pling without anti-aliasing processing in the pure signal proce ssing. Note that in acoustic parameter trajectory smoothing [ 36 ], the acoustic parameter differen ces in high modulation frequency 5 are hardly perceiv ed by huma ns. T herefore, e ven if the aliasing occurs on the acoustic parameter sequence, we wi l l not notice it. The aliasing issue is a problem specific to the wav eform con ver- sion. T o generate more natu ral-sounding speech, t his aliasing issue remains to be solv ed. 4.2. Impro ved Generator: Ad dressing Ali asin g Issue T o allev iate the aliasing described in Sec. 4.1 , we hav e t wo op- tions. One is to explicitly add anti-aliasing processing into t he model architecture. F ollowing this concept, a linear pooling with Gaussian weights has been proposed [ 37 ]. T his pooling operation i s equiv alent to the do wn-sampling after Gaussian fi l- tering. W e can regard the Gaussian filteri ng as the approx ima- tion of low-pass filtering using the cardinal sine function (a.k.a., sinc function) so that the aliasing will be all e viated well . How- e ver , there is a fundame ntal trade-off between the performance and the combination of shift inv ariance and anti- al i asing. Another option is to use a dilated con volution [ 38 ], which is introduced to the deep learning for semantic image segmen- tation, rather than the classical con volu tion with strides. This is a technique to reduce the number of model parameters and obtain the computation al efficiency while maintaining a large recepti ve field to cater for long-range dependencies. Note that 5 Modulat ion frequenc y is the frequen cy of modulati on spectra, which are the power spectra of a giv en acoustic parameter sequence. 0.0 0.3 0.6 0.9 1 2 4 8 F re q ue nc y [kH z ] ( a ) R e c o r d e d 0.0 0.3 0.6 0.9 ( b ) S P S S 0.0 0.3 0.6 0.9 T i m e [s ] ( c ) V 1 0.0 0.3 0.6 0.9 ( d ) V 2 0.0 0.3 0.6 0.9 ( e ) V 2 m sp Figure 1: Spectr ogra m of natural waveform and waveforms g enerated f r om models in Sec. 5.1.2 . Dashed red box indicates aliasing. the recent neural-network-based vocod er such as W aveNet has also adopted t he dilated con volution. T o ward a high-quality neural post-filter for speech wavefo rm generation, assuming that do wn/up-sampling modules are not suitable for the speech wa veform con version unlike acoustic parameter con version, we replace the classical conv olution wi t h the dilated con volution i n the architecture of W aveCyc leGAN. 4.3. Impro ved Discriminator: Multip le Domains In the preliminary experiment, although using the dilated con- volution instead of the con volution with strides made it possible to alleviate the aliasing, the processed speech somehow became noisy speech, as shown in F ig. 1 (d). Theoretically , the gen- erator should imitate a p.d.f . of the real data if the training succeeds. Howe ver , in practice, the gradient of the generator v anishes when the discriminator successfully rejects generated samples with high confidence. For this reason, we used the dis- criminators that have small model parameters, bu t this insuf fi- cient capability of the discriminator might make the decision boundaries non-optimal. T o find t he best decision bounda ries while avoiding the v an- ishing gradient prob lem of the generator , we propose discrim- inators combining multiple domains such as the wav eform do- main D Y wav e and Mel spectrogram doma in D Y msp as follows: L adv ( G X → Y , D Y ) = E y ∼ P Y ( y ) [log D Y wav e ( y )] + E y ∼ P Y ( y ) [log D Y msp ( F ( y ))] + E x ∼ P X ( x ) [log(1 − D Y wav e ( G X → Y ( x )))] + E x ∼ P X ( x ) [log(1 − D Y msp ( F ( G X → Y ( x ))))] . (5) where F indicates a linear mapping function described as a con- volution of the Hanning wi ndo w , followed by a fast Fourier transform (FFT) matrix and Mel-filter bank. Unlike the L1 and L 2 losses on spectra [ 14 , 16 , 39 ], we use the adversarial losses for the multiple domains, so the objecti ve function re- lated to the generator still does not depend directly on y at all and our approach mak es this objectiv e function resistant to the ov er-smoothing problems [ 9 ] the same as con ventiona l W av e- CycleGAN. 5. Experiments 5.1. SPSS using Internal Japanese Dataset 5.1.1. Dataset W e used a Japanese speech dataset consisting of utterances by one professional female narrator . T o train the models, we used about 6,500 sentenc es f or a baseline system and 400 sentences (speech sections of 1.2 hours) each for W av eCycleGAN and W aveCycleGAN2. T o ev aluate the performance, we used 30 sentences (speech sections of 5.3 minutes). The sampling rate of the speech si gnals wa s 22.05 kHz. 5.1.2. Systems W e used a deep neural network (DNN)-based SPSS [ 7 ] and W aveCycleGAN [ 10 ] as a baseline system ( S P SS ) and a con- vention al system ( V 1 ). As a proposed system, V2 indicates W aveCycleGAN2, which has only the speech wa veform do- main’ s discrimi nators. V2+ i ndicates W aveCyc leGAN2 i ncor- porating the discriminators of the acoustic parameter domain s such as the Mel spectrogram ( V2msp ), Mel-frequency cep- strum coefficients ( V2mfcc ), and phase spectrogram ( V2ph ). The architecture of the generator was a linear projection (# of channel, kernel, dilation: 64, 15, 1) followed by a residual block (128, 15, 2), fiv e residual blocks (128, 15, 4), and a li near pro- jection (1, 15, 1). W e app lied the con ventional and proposed systems t o the speech wav eform SP SS . W e used the same learn- ing r ate for the first 80k i terations and linearly decayed to 0 ov er the next 80k iterations. The other conditions are the same as in our prev ious work [ 10 ]. 5.1.3. Objective Evaluation T o ev aluate t he capability of addressing the ov er-smoothing ef- fect caused by the SPS S , we calculated modulation spectrum differe nces (MSD) for the Mel cepstral coefficient of natural speech ( Recorded ). Although the modulation spectrum is tra- ditionally defined as a v alue calculated using t he Fourier trans- form of the parameter sequence [ 40 ], this paper defines the modulation spectrum as its l ogarithmic power spectrum. W e used 8,192 FFT points. Figure 2 sho wed that SP S S significantly suffered from the over -smoothing effect. Although V1 alleviated its ov er- smoothing effect, there w as still a gap. On the other hand, V2+ restored the modulation spectrum of Recorded well. Note that as described in Sec. 4.3 , the speech generated by V2 was more differe nt from natural speech than that generated by the combi- nation methods V2+ . 5.1.4. Subjective Evaluation W e conducted a li stening test with a 5-scale mean opinion score regarding naturalness. On each system, 200 speech samples (10 participants × 20 randomly selected speech samples) were e val- uated. Figure 3 showed t hat V1 significantly impro ved the natu- ralness of the generated speech compared with SP S S . V2msp and V2mfcc were closer to natural speech, and there is no sta- tistical difference fr om natural speech because p v alues of two- sided Mann-Whitney tests are more than 0.05. In contrast, V2 suf fered from noisy speech. Note that the score of V2ph was significantly degraded because t he silence sections someho w became quite noisy . These results suggest that it is better to combine the wav eform domain discriminator and the amplitude 5 10 15 20 25 30 35 40 M e l -c e ps t ra l c oe ffi c i e nt i nde x 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 M S D S P S S V 1 V 2 V 2m fc c V 2ph V 2m s p Figure 2: Modulation spectrum differ ences against for Mel cep- stral coeffic ient of natur al speec h. 1 2 3 4 5 V2msp V2mfcc V1 V2 V2ph SPSS 4.43 4.29 4.26 4.13 4.00 2.93 1.86 Mean opinion score Systems Figure 3: Subjective 5-scale mean opinion scor es r egar ding nat- uralne ss, with 95% confid ence intervals. Dash ed line indicates r esults of r ecord ed natur al speech. spectrum domain discriminator . 5.2. Analysis and Syn t h esis usin g LJS p eech Dataset [ 12 ] 5.2.1. Dataset W e used a public domain English speech dataset [ 12 ] containing 13,100 utterances. T o ev aluate the performance, we used 40 sentences disjoint from the training data. The sampling rate of the speech signals was 22.05 kHz. 5.2.2. Systems W e used WORLD [ 6 ] and Griffin-Lim [ 41 ] vo coders as the parametric and phase vocoder , respectiv ely . For the neural- network-b ased vocod er , we used open W aveNet [ 2 ] employ - ing a mixture of logistics distri bution [ 42 ] and of fi cial W ave- Glow [ 3 ]. The audio samples of open W av eNet and official W aveGlo w were brough t f rom a public folder 6 of R. V alle who is a co-author of W av eGlow [ 3 ]. For t he proposed method, we used W av eCycleGAN2 incorporating the Mel spectrum do- main discriminator V2msp . Note that our proposed method work ed in both the parallel-data condition V2msp (paired) and non-parallel-data condition V2msp (un paired) where the mini- batches of natural speech differed from those of synthesized speech in ev ery iteration. 5.2.3. Objective and Subjective Evaluations T o ev aluate t he capability of W aveCycleGAN2 for an analysis- and-synthesis task, we calculated log spectral distortions ( L SD) and conducted a listening test with 5-scale mean opinion scores regarding naturalness. On each system, 210 speech samples (14 participants × 15 randomly selected speech samples) were e val- uated subjectiv ely . 6 Speech s amples can be accessed in a public folder of Google Dri ve: http://bit.ly/ 2JTDetX T able 1: L og spectr al distortions (LSD) and subjective 5-scale mean opinion scor es r e gar ding naturalness (Naturalness), wit h 95% confidence intervals. Mcep indicates Mel cepstral coeffi- cient. System LSD [dB] Naturalness Recorded [ 12 ] — 4.590 ± 0.082 WORLD [ 6 ] + mcep 4.414 ± 0.022 3 .124 ± 0.150 Griffin-Lim [ 41 ] 1.546 ± 0.016 3 .300 ± 0.143 open W av eNet (MoL) [ 2 ] 4.971 ± 0.041 3 .657 ± 0.162 W aveGlo w [ 3 ] 4.540 ± 0.036 3 .443 ± 0.164 V2msp (paired) 4.318 ± 0.019 4 .023 ± 0.124 V2msp (unpaired) 4.339 ± 0.020 3 .833 ± 0.127 The results of LSD, as shown in T ab . 1 , sho w that Griffin- Lim has the lowest dist orti on. On the other hand, WORLD had higher the distortion because of the parametric vocode r . In the comparison of open W av eNet and W av eGlow , open W av eNet has l arger distortion. One possible reason is that open W av eNet might generate speech w avefo rms that hav e different amplitude spectra from the giv en acoustic parameter when the previous outputs are captured more strongly than the giv en acoustic pa- rameters. In contrast, V2msp has smaller distortion than W av e- Glow . This might be because W aveCycleGAN2 has the advan- tage of the speech wavefo rm con version where the input and output domains are closer than t hose of W av eGlow . In the results of the listening test, there is no stati st ical differe nce in the only two pairs of WORLD - Griffin-Lim and open W av eNet - V2msp (unpaired) because p v alues of two- sided Mann-Whitney tests are more than 0.05. Remarkably , V2msp (paired) outperformed open W av eNet and W av eGlow . Unlike W a veGlo w , our prop osed method is specified to work on only speech signals whereas W av eGlow theoretically works on not only speech signals but also audio signals such as mu- sic. Moreo ver , open W av eNet is not an official i mplementa- tion, so this might not be the best result of W aveNet [ 1 ]. Ho w- e ver , these results are impressiv e, and we also had the foll owing feedback from the participants: 1) W av eGlow sometimes had artifacts like Griffin-L im , 2) open W av eNet sometimes had artifacts li ke the collapsed speech samples reported by W u et al. [ 15 ], and 3) V2msp sometimes had artifacts caused by the un voiced/v oiced detection error of the WORLD vocoder . Note that the tendenc y of the results compared with Recorded differs from the tendency described in Sec. 5.1.4 because the LJSpeech dataset [ 12 ] suffers from reverb . 6. Conclusions W e propose d a time-domain neural post-filter for speech wa ve- form generation, W ave CycleGAN2. Experimental results demonstrated that the proposed method 1) outperformed the con ventional W av eCycleGAN, 2) is useful for both speech wa veforms gen erated by analysis-and-synthesis and statistical parametric speech synthesis, and 3) generated speech wav e- forms comparable to those of natural speech and speech synthe- sized by W aveNet [ 1 ] (open W av eNet [ 2 ]) and W aveGlo w [ 3 ]. 7. Ackno wledgements This work was supported by a grant from the Japan Society for the P romotion of Science (JSPS KAKE NHI 17H01763). The authors thank Ryuichi Y amamoto and the authors of W aveGlo w . 8. Refer ences [1] A. v . d. Oord, S. Diel eman, H. Zen, K. Simony an, O. V inyal s, A. Gra ves, N. Kalchbrenner , A. Senior , and K. Kavu kcuoglu, “W av eNet: A generati ve model for ra w audio, ” arX iv pre print arXiv:1609.03499 , 2016. 1 , 4 [2] R. Y amamoto, “W av eNet vocoder , ” in https:// doi.or g/ 10.5281/ zenodo.1472609 . 1 , 4 [3] R. Prenger , R. V alle, and B. Cata nzaro, “W aveGlo w: A flow- based genera ti ve netw ork for speech synthesis, ” arXiv preprint arXiv:1811.00002 , 2018. 1 , 2 , 4 [4] H. Kaw ahara, I. Masuda-Katsuse, and A. De Chev eigne, “Re- structuri ng s peech representat ions using a pitch -adapti ve time- frequenc y smoothing and an instantane ous-frequenc y-based F0 ext raction: Possible role of a repetiti ve structure in sounds, ” Speec h communi cation , vol. 27, no. 3, pp. 187–207, 1999. 1 [5] H. Kaw ahara, J. Estill, and O. Fujimura, “ Aperiodic ity ext raction and control using mixed mode excit ation and group delay manip- ulati on for a high quali ty speech analysis, modification and syn- thesis system ST RAIGHT, ” in Second International W orkshop on Models and Analysis of V ocal E missions for Biomedical Applica- tions , 2001. 1 [6] M. Morise, F . Y okomori, and K. Ozaw a, “WORLD: a vocoder - based high-quality speech synthe sis system for real-time appli- catio ns, ” IEICE TRANSACTIONS on Information and Systems , vol. 99, no. 7, pp. 1877–1884, 2016. 1 , 4 [7] H. Zen, A. Senior , and M. Schuster , “Statist ical parametric speech synthesis using deep neural netw orks, ” in Acoustics, Speec h and Signal Proc essing (ICASSP), 2013 IEEE International Confer- ence on . IEEE, 2013, pp. 7962–7966. 1 , 3 [8] T . T oda, A. W . Black, and K. T okuda, “V oice con version based on maximum-lik elihood estimation of spectral parameter trajec tory , ” IEEE T ransactions on Audio, Speech , and Language Proce ssing , vol. 15, no. 8, pp. 2222–2235, 2007. 1 , 2 [9] H. Zen, K. T okuda, and A. W . Black, “Statistica l parametri c speech synthesis, ” Speec h Communication , vol . 51, no. 11, pp. 1039–1064, 2009. 1 , 2 , 3 [10] K. T anaka, T . Kaneko, N. Hojo, and H. Kameoka, “W av e- CycleGAN: Syntheti c-to-natu ral speech wa veform con version using cycl e-consiste nt adversari al netwo rks, ” arXiv preprint arXiv:1809.10288 , 2018. 1 , 2 , 3 [11] J. Ko minek and A. W . Black, “The CMU Arctic speech databa ses, ” in F ifth ISCA workshop on speec h synthesis , 2004. 1 [12] K. Ito, “The LJ speech dataset, ” https:/ /keit hito.com/LJ- Speech- Dataset/ , 2017. 1 , 4 [13] N. Kalchbrenner , E. Elsen, K. Simonyan, S. Noury , N. Casagrande, E. L ockhart , F . Stimber g, A. v . d. Oord, S. Dieleman, and K. Kavukcuo glu, “ Effici ent neural audio synthesis, ” arX iv pre print arXiv:1802.08435 , 2018. 1 [14] X. W ang, S. T akaki, and J. Y amagishi, “Neural source-filter - based wa veform model for statisti cal par ametric speech synthe- sis, ” arXiv pre print arXiv:1810.11946 , 2018. 1 , 2 , 3 [15] Y .-C. Wu, K. K obayashi, T . Hayashi, P . L. T obing, and T . T oda, “Colla psed speech segment detectio n and suppression for wa venet voco der , ” arXiv preprint , 2018. 1 , 4 [16] A. v . d. Oord, Y . Li, I. Babuschki n, K. Simon yan, O. V inyals, K. Ka vukcuoglu, G. v . d. Driessche, E. Lockhart, L. C. Cobo, F . Stimberg et al. , “P aralle l W av eNet: Fast high-fidelit y speech synthesis, ” arX iv pre print arXiv:1711.10433 , 2017. 2 , 3 [17] W . Ping, K. Peng, and J. Chen, “ClariNet: Paral lel wa ve generat ion in end-to-end text -to-speech , ” arXiv preprin t arXiv:1807.07281 , 2018. 2 [18] P . L. T obing, Y .-C . Wu, T . Hayashi , K. Kobaya shi, and T . T oda, “V o ice con version with cyclic rec urrent neural network and fine- tuned W ave Net vocoder , ” in ICASSP2019 , 2019. 2 [19] S. T akamichi, T . T oda, G. Neubig, S. Sakti, and S. Nakamura, “ A postfilter to modify the modulati on spectrum in HMM-based speech synthesis, ” in Acoustic s, Speec h and Signal Proce ssing (ICASSP), 2014 IEEE Internation al Conferen ce on . IEEE, 2014, pp. 290–294. 2 [20] T . Kaneko, H. Kameoka, N. Hojo, Y . Ijima, K. Hiramatsu, and K. Kashin o, “Generati ve adversa rial network- based postfilter for statisti cal parametric speech synthesis, ” in Proc. 2017 IEEE Inter- national Confer ence on Acoustics, Speech and Signal Proc essing (ICASSP2017) , 2017, pp. 4910–4914. 2 [21] Y . Saito, S. T akamichi, H. Saruwatari, Y . Saito, S. T akamichi, and H. Saruwata ri, “Statisti cal parametri c speech synthesis inc orpo- rating generat i ve adv ersarial networks, ” IE EE/ACM T ransactions on Audio, Speec h and Language Proce ssing (TASLP) , vo l. 26, no. 1, pp. 84–96, 2018. 2 [22] S. Ma, D. Mcduff, and Y . Song, “ A generati ve adve rsarial network for style modeling in a text-t o-speech system, ” in Internationa l Confer ence on Learning Represe ntations , 2019. 2 [23] H. Kameoka, T . Kaneko, K. T anaka, and N. Hojo, “StarGAN-VC: Non-paral lel many-to-man y voice con version with star generati ve adve rsarial networ ks, ” arXiv preprint , 2018. 2 [24] D. He, Y . Xia, T . Qin, L. W ang, N. Y u, T . Liu, and W .-Y . Ma, “Dual learning for mach ine translation, ” in Advances in Neural Informatio n Proce ssing Systems , 2016, pp. 820–828. 2 [25] J.-Y . Zhu, T . Park, P . Isola, and A. A. Efros, “Unpa ired image- to-image translation using cycl e-consiste nt adversarial networks, ” arXiv prep rint arX iv:1703.10593 , 2017. 2 [26] I. Goodfello w , J. Pouget-Abadie, M. Mirza, B. Xu, D. W arde- Farle y , S. Ozair , A. Courvill e, and Y . Bengio, “Generati ve adver - sarial net s, ” in Advances in neur al information pr ocessing sys- tems , 2014, pp. 2672–2680. 2 [27] T . Zhou, P . Krahenbuhl, M. Aubry , Q. Huang, and A. A. Efros, “Learning dense correspondence via 3D-guide d cycle consis- tenc y , ” in Pr oceedi ngs of the IEEE Confer ence on Comput er V i- sion and P attern R ecog nition , 2016, pp. 117–126. 2 [28] Y . T aigman, A. Polyak, and L. W olf, “Unsupervi sed cross-domain image generati on, ” arX iv preprint arXiv:1611.022 00 , 2016. 2 [29] K. He, X. Z hang, S. Ren, and J. Sun, “Deep resi dual learni ng for image recognition, ” in Proce edings of the IEEE confer ence on computer vision and pattern reco gnition , 2016, pp. 770–778. 2 [30] C. Ledig, L. Theis, F . Husz ´ ar , J. Caballero, A. Cunningham, A. Acosta, A. Aitk en, A. T ejani, J. T otz, Z. W ang et al. , “Phot o- realist ic single image super-resolut ion using a generat i ve adv er- sarial network, ” arX iv pre print , 2016. 2 [31] S. Sun, J. Pa ng, J. Shi, S. Y i, and W . Ouyang, “FishNet: A ver- satile backb one for image, re gion, and pixel le vel pred iction, ” in Advances in Neu ral Informat ion Pr ocessing Syst ems , 2018, pp. 762–772. 2 [32] M. Rav anelli and Y . Bengio, “Speak er recognit ion from raw wa ve- form with S incNet, ” arXiv preprint arXiv:1808.001 58 , 2018. 2 [33] M. D. Zeil er and R. F ergus, “V isualizin g and understanding con- volu tional networks, ” in Europ ean confer ence on computer vision . Springer , 2014, pp. 818–833. 2 [34] Y . Gong and C. Poellaba uer , “Impact of aliasing on deep CNN- based end-to-end acoustic models, ” P r oc. Inter speech 2018 , pp. 2698–2702, 2018. 2 [35] C. E. Shannon, “Communicati on in the presence of noise, ” Pro- ceedi ngs of the IEEE , vol. 86, no. 2, pp. 447–457, 1998. 2 [36] S. T akamichi, K. Kobaya shi, K. T anaka, T . T oda, and S. Naka- mura, “The NAIST text-to-sp eech system for the blizzar d chal- lenge 2015, ” in Proc . Blizzard Challenge workshop , 2015. 2 [37] J. Mairal, P . Koniusz , Z. Harchaoui, and C. Schmid, “Con volu- tional kernel networks, ” in Advances in neural informati on pro- cessing systems , 2014, pp. 2627–2635. 2 [38] L.-C. Chen, G. Papandreo u, I. K okkinos, K. Murphy , and A. L. Y uille, “Semanti c image seg mentation with deep con volutiona l nets and fully conne cted crf s, ” arXiv preprint , 2014. 2 [39] S. T akaki, T . N akashika, X. W ang, and J. Y amagishi, “STFT s pec- tral loss for trai ning a neural speech wav eform model, ” arXiv pre print arXiv:1810.11945 , 2018. 3 [40] L. Atl as and S. A. Shamma, “Joint acoustic and modula tion fre- quenc y , ” EU R ASIP Journal on Advance s in Signal Pr ocessing , vol. 2003, no. 7, p. 310290, June 2003. 3 [41] D. Griffin and J. Lim, “Signal estimatio n from modified short- time Fourier transform, ” IEE E T ransaction s on Acoustics, Speech, and Signal P r ocessing , vol . 32, no. 2, pp. 236–243, 1984. 4 [42] T . Salimans, A. Karpat hy , X. Chen, and D. P . Kingma, “Pix- elCNN++: Improvi ng the pixe lcnn with discretized logi stic mixture likeli hood and other modificat ions, ” arXiv preprin t arXiv:1701.05517 , 2017. 4
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment