Fog Computing Vs. Cloud Computing
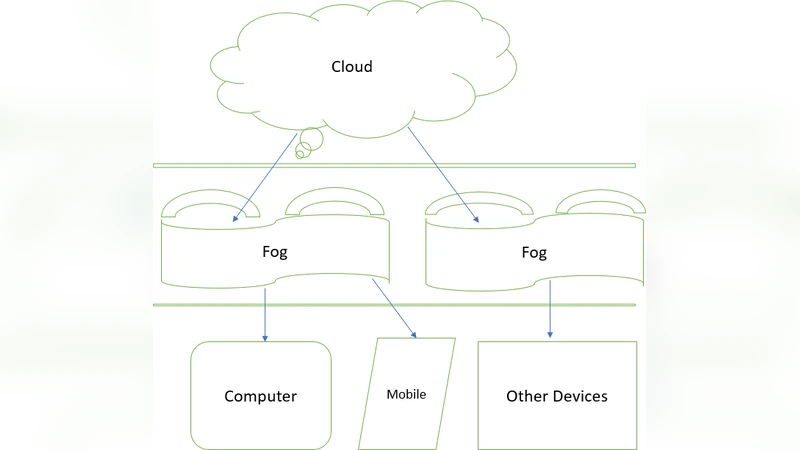
This article gives an overview of what Fog computing is, its uses and the comparison between Fog computing and Cloud computing. Cloud is performing well in todays World and boosting the ability to use the internet more than ever. Cloud computing gradually developed a method to use the benefits of it in most of the organizations. Fog computing can be apparent both in big data structures and large cloud systems, making reference to the growing complications in retrieving the data accurately. Fog computing is outspreading cloud computing by transporting computation on the advantage of network systems such as cell phone devices or fixed nodes with in-built data storage. Fog provides important points of improved abilities, strong security controls, and processes, establish data transmission capabilities carefully and in a flexible manner. This paper gives an overview of the connections and attributes for both Fog computing and cloud varies by outline, preparation, directions, and strategies for associations and clients. This also explains how Fog computing is flexible and provide better service for data processing by overwhelming low network bandwidth instead of moving whole data to the cloud platform.
💡 Research Summary
The paper provides a comprehensive overview of fog computing, positioning it as a distributed computing layer that resides between end‑devices and centralized cloud data centers. It begins by acknowledging the successes of cloud computing—massive scalability, virtually unlimited processing power, and global service delivery—but points out inherent drawbacks for latency‑sensitive, bandwidth‑constrained, and privacy‑critical applications. Because cloud resources are typically located far from data sources, transmitting raw sensor streams or high‑resolution video to a remote data center incurs significant round‑trip delays, saturates backbone links, and raises the risk of data exposure during transit.
Fog computing is introduced as a remedy to these limitations. By leveraging compute, storage, and networking capabilities embedded in routers, switches, gateways, smartphones, and dedicated edge servers, fog nodes can perform preprocessing, filtering, aggregation, and even lightweight analytics directly at the point of data generation. This “compute‑at‑the‑edge” approach yields three primary benefits:
- Latency Reduction – Processing occurs within milliseconds of data capture, enabling real‑time control loops for autonomous vehicles, industrial robotics, remote health monitoring, and augmented reality.
- Bandwidth Efficiency – Only salient events, compressed summaries, or model‑inferred insights are forwarded to the cloud, dramatically lowering upstream traffic and associated costs.
- Enhanced Security & Privacy – Sensitive information can be anonymized, encrypted, or retained locally, aligning with regional data‑sovereignty regulations (e.g., GDPR) and reducing the attack surface presented by long‑haul transmission.
The authors systematically compare fog and cloud across functional, security, cost, and management dimensions. Cloud excels in raw computational capacity, long‑term storage, and mature orchestration ecosystems, but suffers from higher latency and bandwidth dependence. Fog, conversely, offers rapid response and localized data handling at the expense of limited resources per node and increased operational complexity due to the sheer number of distributed devices.
Key application domains highlighted include:
- Internet of Things (IoT) – Massive sensor deployments generate continuous streams that benefit from edge‑side anomaly detection and rule‑based filtering.
- Smart Cities – Traffic signal optimization, air‑quality monitoring, and video analytics require near‑instantaneous feedback loops that fog can provide.
- Industry 4.0 – Manufacturing lines rely on deterministic latency for robotic coordination and predictive maintenance, both of which are supported by edge processing.
- Healthcare – Wearable and bedside monitors can alert clinicians in real time while keeping patient data within the hospital’s secure perimeter.
Implementation challenges are examined in depth. Managing thousands of heterogeneous fog nodes demands robust orchestration frameworks; the paper cites emerging extensions to Kubernetes and lightweight container runtimes as potential solutions. Standardization remains nascent—efforts by the OpenFog Consortium and ETSI’s Multi‑Access Edge Computing (MEC) group are shaping APIs and service models, yet true inter‑vendor interoperability is not yet achieved. Security concerns are amplified because edge devices are physically exposed; hardware‑rooted trust modules (TPM, Secure Enclave) and lightweight cryptographic protocols are recommended. Finally, resource scheduling must balance CPU, memory, storage, and power constraints, often offloading heavier workloads back to the cloud when local capacity is exceeded.
A hybrid architecture is proposed as the optimal deployment model. In this paradigm, raw data first undergoes edge‑side collection and preprocessing; time‑critical analytics remain on fog nodes, while aggregated or selected datasets are transmitted to the cloud for long‑term archiving, deep learning model training, and global service orchestration. This separation of concerns allows latency‑sensitive services to meet strict response requirements while still leveraging the cloud’s massive analytical capabilities.
In conclusion, the authors argue that fog computing is not a competitor but a complementary extension of cloud infrastructure, essential for the next wave of real‑time, data‑intensive applications. They emphasize that widespread adoption hinges on solving three interrelated problems: (1) developing mature, automated orchestration and lifecycle management tools for edge resources; (2) establishing open, vendor‑agnostic standards for communication, security, and service description; and (3) integrating robust security mechanisms that protect distributed nodes without imposing prohibitive overhead. Future research directions suggested include fog‑enabled AI inference at the edge, energy‑efficient hardware designs, multi‑cloud/multi‑edge service‑level agreement (SLA) frameworks, and dynamic workload migration strategies that seamlessly shift tasks between fog and cloud based on real‑time performance metrics. By addressing these challenges, fog computing can fulfill its promise of delivering low‑latency, bandwidth‑aware, and privacy‑preserving services at scale, thereby extending the reach of cloud computing into environments where traditional centralized models fall short.
Comments & Academic Discussion
Loading comments...
Leave a Comment