VAE-based regularization for deep speaker embedding
Deep speaker embedding has achieved state-of-the-art performance in speaker recognition. A potential problem of these embedded vectors (called `x-vectors') are not Gaussian, causing performance degradation with the famous PLDA back-end scoring. In th…
Authors: Yang Zhang, Lantian Li, Dong Wang
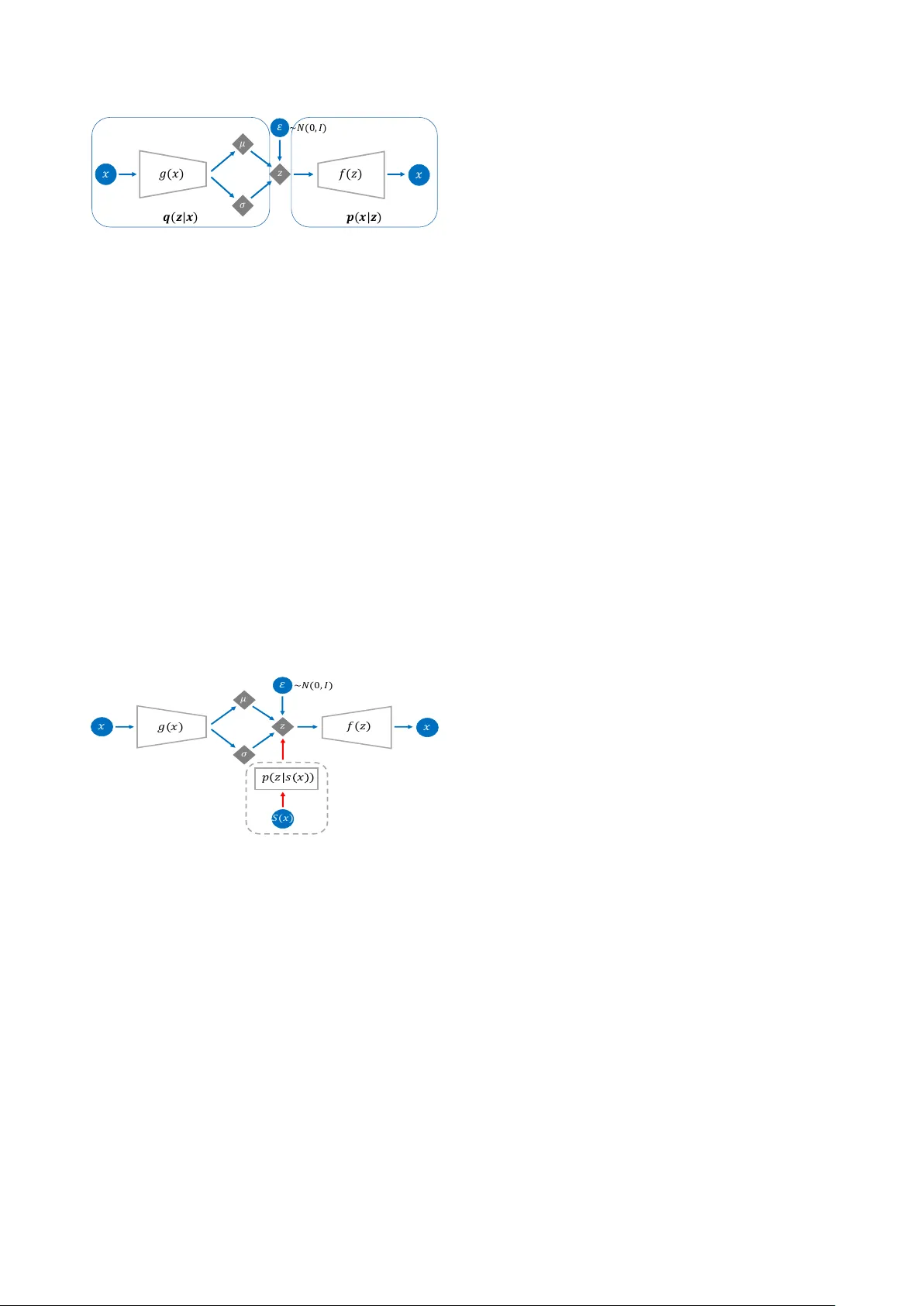
V AE-based r egularization f or deep speaker embedding Y ang Zhang 1 , 2 , Lantian Li 1 , Dong W ang 1 ∗ 1 Center for Speech and Language T echnologies, Tsinghua Uni versity , China 2 Beijing Uni versity of Posts and T elecommunications, China { zhangyang,lilt } @cslt.org; wangdong99@mails.tsinghua.edu.cn Abstract Deep speaker embedding has achiev ed state-of-the-art per- formance in speaker recognition. A potential problem of these embedded vectors (called ‘x-v ectors’) are not Gaussian, caus- ing performance degradation with the famous PLDA back-end scoring. In this paper , we propose a regularization approach based on V ariational Auto-Encoder (V AE). This model trans- forms x-v ectors to a latent space where mapped latent codes are more Gaussian, hence more suitable for PLD A scoring. Index T erms : V ariational Auto-Encoder, deep speaker embed- ding 1. Introduction Automatic speaker verification (ASV) has found a broad range of applications. Con ventional ASV methods are based on sta- tistical models [1, 2, 3]. Perhaps the most famous statistical model in ASV is the Gaussian mixture model-univ ersal back- ground model (GMM-UBM) [1]. This model represents the ‘main’ variance of speech signals by a set of global Gaussian components (UBM), and the speaker characters are represented as the ‘shift’ of speaker-dependent GMMs over each Gaussian component of the UBM, denoted by a ‘speaker supervector’. The GMM-UBM architecture was later enhanced by subspace models, which assume that a speaker supervector can be fac- torized into a speaker vector (usually low-dimensional) and a residual that represents intra-speaker variation. The joint factor analysis [2, 4] was the most successful subspace model in early days, though the follo wing i-vector model obtained more atten- tion [3]. Besides the simple structure and the superior perfor- mance, the i-v ector approach firstly demonstrated that a speaker can be represented by a low-dimensional vector , which is the precursor of the important concept of speaker embedding . It should be emphasized, howe ver , that the i-vector model is purely unsupervised and the embeddings (i-vectors) contain a multitude of variations more than speaker information. There- fore, it heavily relies on a powerful back-end scoring model to achieve reasonable performance. Among various back-end models, the PLD A model [5, 6] has been very po werful, in par- ticular with a simple whitening and length normalization [7]. In the nut shell, PLD A assumes the ‘true’ speaker codes within an i-vector is low dimensional and follows a simple Gaussian prior , and the residual is a full-rank Gaussian, formally written by: φ su = m + U y s + su , (1) where φ su is the i-vector of utterance u of speaker s , y s ∼ N (0 , I ) and su ∼ N (0 , W ) are speaker codes and residual respectiv ely , m is the global shift and U is the speaker loading matrix. Under this assumption, the speaker prior p ( y s ) , the con- ditional p ( φ | y s ) and the marginal p ( φ ) are all Gaussian. Fortu- nately , i-v ectors match these conditions pretty well, due to the linear Gaussian structure of the i-vector model. P artly for this reason, the i-vector/PLD A frame work remains a strong baseline on many ASV tasks. Recently , neural-based ASV models have shown great po- tential [8, 9, 10, 11]. These models utilize the power of deep neural netw orks (DNNs) to learn strong speaker -dependent fea- tures, ideally from a large amount of speaker-labelled data. The present research can be categorized into frame-based learn- ing [8, 10] and utterance-based learning [9, 11, 12, 13]. The frame-based learning intends to learn short-time speaker fea- tures, thus more generally useful for speaker -related tasks, while the utterance-based learning focuses on a whole-utterance speaker representation and/or classification, hence more suit- able for the ASV task. A popular utterance-based learning ap- proach is the x-vector model proposed by Snyder et al. [11], where the first- and second-order statistics of frame-lev el fea- tures are collected and projected to a low-dimensional rep- resentation called x-vector , with the objective of discriminat- ing the speakers in the training dataset. The x-vector model has achie ved good performance in various speaker recogni- tion tasks, as well as related tasks such as language identifi- cation [14]. Essentially , the x-vector model can be regarded as a deep and discriminative counterpart of the i-vector model, and is often called deep speaker embedding . Interestingly , experiments show that the x-vector system also heavily relies on a strong back-end scoring model, in par- ticular PLDA. Since the x-vector have been sufficiently discrim- inativ e, the role of PLD A here is regularization rather than dis- crimination (as in the i-vector paradigm): it (globally) discov- ers the underlying speech codes that are intrinsically Gaussian, so that the ASV scoring based on these codes tends to be com- parable across speakers. A potential problem, howe ver , is that x-vectors inferred from DNNs are unconstrained, which means that the speaker distribution and the speaker conditional could be in any form. These unconstrained distributions may cause great dif ficulty for PLD A to discover the underlying speaker codes that are assumed to be Gaussian. Some researchers have noticed this problem and proposed some remedies that encour- age speaker conditionals more Gaussian [15, 16], but none of them constrain the prior, thus produced x-vectors are still not suitable for PLD A modeling. In this paper , we inv estigate an explicit regularization model for unconstrained x-vectors. This model is inspired by the variational auto-encoder (V AE) architecture, which is capa- ble of projecting an unconstrained distribution to a simple Gaus- sian distribution. This can be used to constrain the marginal distribution of x-vectors. Moreover , a cohesive loss is added to the V AE objective. This follows the same spirit of [15, 16] and can constrain the speaker conditionals. Experiments showed that with this V AE-based regularization, performance of cosine scoring is largely impro ved, ev en comparable with PLD A. This indicates that V AE plays a similar role as PLDA, or , in other words, PLD A works as a regularizer rather than a discriminator in the x-vector scoring. Furthermore, the V AE-based speaker codes achiev ed the state-of-the-art performance when scoring with PLDA, demonstrating that (1) V AE-based speaker codes are more regularized and suitable for PLDA modeling, and (2) V AE-based regularization and PLDA scoring are complemen- tary . The organization of this paper is as follows. Section 2 presents the V AE-based regularization model, and the exper - iments are reported in Section 3. The paper is concluded in Section 4. 2. V AE-based speaker regularization 2.1. Revisit PLDA The principle of PLD A is to model the marginal distrib ution of speaker embeddings (i-vector or x-vector), by factoring the total variation of the embeddings into between-speaker variation and within-speaker v ariation. Based on this factorization, the ASV decision can be cast to a hypothesis test [5, 6], formulated by: s ( φ 1 , φ 2 ) = P ( φ 1 = φ 2 | Λ) P ( φ 1 6 = φ 2 | Λ) = R p ( φ 1 , φ 2 | y ) p ( y )d y R p ( φ 1 | y ) p ( y )d y R p ( φ 2 | y ) p ( y )d y , where s denotes the confidence score, and the equality relation ( φ 1 = φ 2 ) denotes that the two embeddings are from the same speaker . According to Eq.(1), PLD A is a linear Gaussian model and the prior , the conditional, and the marginal are Gaussian. If the embeddings do not satisfy this condition, PLD A cannot model them well, leading to inferior performance. This is the case of x-vectors, which are deri ved from DNNs and both the speaker prior and speaker conditionals are unconstrained. In order to deal with the unconstrained distributions of x-vectors, we need a probabilistic model more complex than PLD A. 2.2. V AE for regularization V AE is a generati ve model (like PLDA) that can represent a complex data distrib ution [17]. The ke y idea of V AE is to learn a DNN-based mapping function x = f ( z ) that maps a simple distribution p ( z ) to a complex distribution p ( x ) . In other words, it represents complex observations by simple-distributed latent codes via distrib ution mapping . An illustration of this map- ping is shown in Fig. 1. It can be easily shown that the mapped distribution is written by: log p ( x ) = log p ( z ) + log | det d f − 1 ( x ) d x | , where f − 1 is the in verse function of f ( z ) . Although V AE can be used to represent the complex marginals , it does not in volv e any class structure, and so cannot be used in the hypothesis test scoring framew ork. Nevertheless, if we can find the posterior p ( z | x ) , the complex p ( x ) can be mapped to a more constrained p ( z ) , so the simple cosine dis- tance can be used for verification. Moreover , the regularized code z tends to be easily modeled by PLD A, hence combining the strength of V AE in distribution mapping and the strength of PLD A in distinguishing between- and within-speaker varia- tions. Fortunately , V AE provides a simple way to infer an ap- proximation distrib ution of p ( z | x ) , denoted by q ( z | x ) . It learns a function g ( x ) , parameterized by a DNN, to map x to the pa- rameters of q ( z | x ) , which are the mean and cov ariance if q ( z | x ) is assumed to be Gaussian. By this setting, the mean vector of q ( z | x ) can be treated as V AE-regularized speaker codes, and can be used in cosine or PLD A-based scoring. Fig. 2 illustrates the V AE frame work. In this framework, a decoder f ( z ) maps p ( z ) to p ( x ) , i.e., p ( x ) = Z p ( x | z ) p ( z )d z = Z N ( f ( z ) , I ) p ( z )d z, where p ( x | z ) has been assumed to be a Gaussian. Furthermore, an encoder g ( x ) produces a distribution q ( z | x ) that approxi- mates the posterior distribution p ( z | x ) as follo ws: p ( z | x ) ≈ q ( z | x ) = N ( µ ( x ) , σ ( x )) , where [ µ ( x ) σ ( x )] = g ( x ) . The training objectiv e is the log probability of the training data P i ln p ( x i ) . It is intractable so a variational lower bound is optimized instead, which depends on both the encoder g ( x ) and the decoder f ( z ) . This is formally written by: L ( f , g ) = X i {− D KL [ q ( z | x i ) || p ( z )] + E q ( z | x i ) [ln p ( x i | z )] } , where D KL is the KL distance, and E q denotes expectation w .r .t. distribution q . As the expectation is intractable, a sam- pling scheme is often used, as shown in Fig. 2. More details of the training process can be found in [17]. Note that the L ( f , g ) in volves two components: a regular - ization term that pushes q ( z | x ) to p ( z ) , and a reconstruction term that encourages a good reconstruction of x from z . W e are free to tune the relati ve weights of these two terms in practice, in order to obtain latent codes that are either more regularized or more representati ve. This freely-modified objecti ve may be nev er a variational lower bound, though non-balanced weights often lead to better performance in our experiments. (a) (b) Figure 1: T wo examples of distribution mapping. (a) a discr ete distribution is mapped to a mixture of two Gaussians; (b) a 2- dim Gaussian is mapped to an irr egular distribution. 2.3. Speaker cohesive V AE The standard V AE only constrains the marginal distribution p ( z ) to be Gaussian, which does not guarantee a Gaussian prior or a Gaussian conditional. This is because the V AE model is purely unsupervised and there is no speaker information in- volv ed. This lack of speaker information is probably not a big 𝑔 ( 𝑥 ) 𝑥 𝜎 𝜇 𝑧 𝜀 ~ 𝑁 ( 0 , 𝐼 ) 𝑓 ( 𝑧 ) 𝑥 𝒒 ( 𝒛 | 𝒙 ) 𝒑 ( 𝒙 | 𝒛 ) Figure 2: The standard V AE arc hitecture. It involves a gen- erative model (decoder) p ( z ) and p ( x | z ) , and an inference model (encoder) q ( z | x ) that appr oximates the posterior p ( z | x ) . Both p ( x | z ) and q ( z | x ) in volve a DNN-based mapping func- tion. A random variable is used to facilitate the construction of q ( z | x ) , known as ‘repar ameterization trick’ [17]. issue for x-vectors as they are speaker discriminative already . Howe ver , considering speaker information may help V AE to produce a better regularization. Especially , if the speaker code z s,u of a particular speaker s can be regularized to be Gaus- sian, the scores based on either cosine distance or PLD A will be more across-speaker comparable. This can be formulated as an additional term in the V AE objecti ve function, which we call speaker cohesive loss denoted by L C : L C ( f , g ) = X i ln p ( µ ( x ) | s ( x )) = X i ln N ( µ ( x ); s ( x ) , I ) where s ( x ) denotes the mean of µ ( x ) of all utterances that be- long to the same speaker as x . This essentially follows the same spirit of the central loss used in [15, 16]. Fig. 3 illus- trates the V AE architecture with cohesive loss, and we name this improv ed V AE architecture as Cohesive V AE . 𝑔 ( 𝑥 ) 𝑥 𝜎 𝜇 𝑧 𝜀 ~ 𝑁 ( 0 , 𝐼 ) 𝑓 ( 𝑧 ) 𝑥 𝑝 ( 𝑧 | 𝑠 𝑥 ) 𝑆 ( 𝑥 ) Figure 3: The V AE ar chitecture with cohesive loss (dotted box). 3. Experiments 3.1. Data Three datasets were used in our experiments: V oxCeleb, SITW and CSL T -SITW . V oxCeleb was used for model training, while the other two were used for ev aluation. More information about these three datasets is presented below . V oxCeleb : A large-scale free speaker database collected by Univ ersity of Oxford, UK [18]. The entire database inv olves V oxCeleb1 and V oxCeleb2 . This dataset, after removing the ut- terances shared by SITW , was used to train the x-vector model, plus the PLD A and V AE models. Data augmentation was ap- plied, where the MUSAN corpus [19] was used to generate noisy utterances and the room impulse responses (RIRS) cor- pus [20] was used to generate re verberant utterances. SITW : A standard database used to test ASV performance in real-world conditions [21]. It w as collected from open-source media channels, and consists of speech data cov ering 299 well- known persons. There are two standard datasets for testing: Dev . Core and Eval. Cor e . W e used Dev . Cor e to select model parameters, and Eval. Core to perform test in our first exper - iment. Note that the acoustic condition of SITW is similar to that of the training set V oxCeleb, so this test can be regarded as an in-domain test . CSLT -SITW : A small dataset collected by CSL T for com- mercial usage. It consists of 77 speakers, each of which records a simple Chinese command word, and the duration is about 2 seconds. The scenarios in volve laboratory , corridor , street, restaurant, bus, subway , mall, home, etc. Speakers varied their poses during the recording, and the recording de vices were placed both near and far . There are about 30 k utterances in total. The acoustic condition of this dataset is quite different from that of the training set V oxCeleb, and was used for out-of- domain test . 3.2. Settings W e built sev eral systems to validate the V AE-based regulariza- tion, each in volving a particular pair of front-end and back-end. 3.2.1. F r ont-end x-vector : The baseline x-vector front-end. It was built follow- ing the Kaldi SITW recipe [22]. The feature-learning compo- nent is a 5 -layer time-delay neural network (TDNN). The statis- tic pooling layer computes the mean and standard deviation of the frame-le vel features from a speech se gment. The size of the output layer is 7 , 185 , corresponding to the number of speakers in the training set. Once trained, the 512 -dimensional activ a- tions of the penultimate hidden layer are read out as an x-vector . v-vector : The V AE-regularized speaker code. The V AE model is a 7 -layer DNN. The dimension of code layer is 200 , and other hidden layers are 1 , 800 . The x-vectors of all the training utter- ances are used to the V AE training. c-vector : The V AE-regularized speaker code, with the cohe- siv e loss inv olved in the V AE training. The model structure is the same as in the v-vector front-end, and the v-v ector V AE was used as the initial model for training. W e tuned the weight L C ( f , g ) in the objective function, and found 10 is a reasonable value. a-vector : Speaker code regularized by a standard auto-encoder (AE). AE shares a similar structure as V AE, but the latent codes are not probabilistic so it is less capable of modeling complex distributions. The AE structure is identical to the V AE model in the v-vector front-end, except that the code layer is determinis- tic. 3.2.2. Back-end Cosine : Simple cosine distance. PCA : PCA-based projection (150-dim) plus cosine distance. PLD A : PLD A scoring. L-PLD A : LD A-based projection (150-dim) plus PLDA scoring. P-PLD A : PCA-based projection (150-dim) plus PLD A scoring. 3.3. In-domain test The results on the two SITW ev aluation sets, Dev . Core and Eval. Core , are reported in T able 1. The results are reported in terms of equal error rate (EER). Firstly focus on the x-vector front-end. It can be found that PLD A scoring outperformed cosine distance. As we argued, this cannot be interpreted as the discriminativ e nature of PLD A, but its regularization capability . This is supported by the ob- servation that the v-v ector front-end achie ved rather good per - formance with the cosine back-end (compared with x-vector + PLD A). Since V AE is purely unsupervised, it only contributes to regularization. This suggests that PLDA may play a similar role as V AE. Secondly , we observe that with PCA or LD A, PLDA can perform much better . It is not convincing to assume that LD A and PCA improve the discriminant power of x-vectors (in par- ticular PCA), so the only interpretation is that these two models performed regularization, generating more Gaussian codes that are suitable for PLDA. This regularization is similar as what V AE did, but it seems V AE did a better job than PCA, and e ven better than LD A on the larger ev aluation set Eval. Cor e , e ven without any speaker supervision. Thirdly , it can be found that c-vectors performed better than v-vectors with cosine scoring, confirming that in volving cohe- siv e loss improv es the regularization. When combined with PLD A, howe ver , the advantage of c-vectors diminished. This is expected as PLDA has already learned the speaker discrimi- nativ e knowledge. Finally , we found that other unsupervised regularization methods, including PCA and AE, can not obtain reasonable performance with cosine distance, indicating that they cannot conduct good regularization by themselves. This is contrast to V AE, confirming the importance of the probabilistic codes: without this probabilistic nature, it would be impossible to model the complex distrib ution of x-vectors. T able 1: P erformance (EER%) on SITW De v . Cor e and Eval. Cor e. SITW Dev . Core Cosine PCA PLD A L-PLD A P-PLD A x-vector 15.67 16.17 9.09 3.12 4.16 a-vector 16.10 16.48 11.21 4.24 5.01 v-vector 10.32 9.94 3.62 3.54 4.31 c-vector 9.05 8.55 3.50 3.31 3.85 SITW Eval. Core Cosine PCA PLD A L-PLD A P-PLD A x-vector 16.79 17.22 9.16 3.80 4.84 a-vector 16.05 16.81 12.14 4.27 5.09 v-vector 10.11 10.03 3.64 3.64 4.43 c-vector 9.05 8.83 3.77 3.53 4.10 3.4. Analysis T o better understand the V AE-based regularization, we com- pute the skewness and kurtosis of the distributions of different speaker codes. The skewness and kurtosis are defined as fol- lows: Sk ew( x ) = E [( x − µ x ) 3 ] σ 3 x , Kurt( x ) = E [ x − µ x ] 4 σ 4 x − 3 , where µ x and σ x denote the mean and standard v ariation of x , respectiv ely . More Gaussian is a distribution, more close to zero are the two v alues. The utterance-level and speaker-le vel skewness and kurto- sis of dif ferent speaker codes are reported in T able 2. Focusing on the utterance-level results, it can be seen that the v alues of ske wness and kurtosis of both v-vector and c-vector are clearly smaller than x-vector . This means that the v-vector and the c- vector are more Gaussian. For the speaker-le vel results, it can be found that the kurtosis was largely reduced in v-vectors and c-vectors. This indicates that the Gaussian regularization placed by V AE on the marginal has implicitly regularized the prior, which is the major reason that these vectors are more suitable for PLDA. The a-vector , derived from AE, has smaller ske w- ness but larger kurtosis compared to the x-vector , on both the utterance-lev el and the speaker-le vel, suggesting that AE did not perform a good regularization. T able 2: Utterance-level and speaker-le vel skewness and kurto- sis of differ ent speaker codes on the V oxceleb set. Ske w(utt) Kurt(utt) Ske w(spk) Kurt(spk) x-vector -0.0423 -0.3604 0.0018 -0.4499 a-vector -0.0072 -0.7740 0.0014 -0.9765 v-vector -0.0055 0.1324 -0.0042 -0.0285 c-vector -0.0043 0.1154 -0.0076 -0.0298 3.5. Out-of-domain test In this experiment, we test the performance of various systems on the CSL T -SITW dataset. Due to the limited data, three-fold cross-validation was used whene ver training is required. Three experiments were conducted: (1) directly using all the front- end and back-end models trained by V oxCeleb; (2) retraining all the models except the x-vector DNN; (3) the same as the retraining scheme, but all the PLD A models were trained by an unsupervised adaptation [23]. The results show that scheme (2) is generally the best, and the PLD A adaptation contrib utes additional gains in some test settings. For simplicity , only the retraining results under scheme (2) are reported in T able 3. The results exhibit a similar trend as in the SITW test, that both the v-vector and c-vector outperform the x-vector , and the c- vector obtained the best performance in nearly all the test set- tings. Compared to the SITW test, the larger performance gains obtained by V AE-regularization. It might be attributed to the more complex acoustic conditions of CSL T -SITW , though more in vestigation is required. T able 3: P erformance (EER%) on CSLT -SITW . Cosine PCA PLD A L-PLD A P-PLD A x-vector 16.65 16.89 16.91 15.39 13.29 v-vector 13.55 13.71 12.46 12.06 12.02 c-vector 12.98 13.13 12.48 12.01 11.98 4. Conclusions This paper proposed a V AE-based regularization for deep speaker embedding. By this model, x-vectors that usually ex- hibit a complex distribution are mapped to latent speaker codes that are simply Gaussian. This model was further enhanced by a speaker cohesive loss, which regularizes speaker condition- als. Experiments on the SITW dataset and a priv ate commercial dataset demonstrated that the V AE-regularized speaker codes can achieve better performance with either cosine distance or PLD A scoring, compared to the x-vector baseline. Future work will in vestigate speaker-aw are V AE, where speaker codes and utterance codes are hierarchically linked as in PLD A. 5. References [1] D. A. Reynolds, T . F . Quatieri, and R. B. Dunn, “Speaker veri- fication using adapted Gaussian mixture models, ” Digital signal pr ocessing , vol. 10, no. 1-3, pp. 19–41, 2000. [2] P . Kenn y , G. Boulianne, P . Ouellet, and P . Dumouchel, “Joint factor analysis versus eigenchannels in speaker recognition, ” IEEE T ransactions on Audio, Speech, and Language Pr ocessing , vol. 15, no. 4, pp. 1435–1447, 2007. [3] N. Dehak, P . J. Kenny , R. Dehak, P . Dumouchel, and P . Ouellet, “Front-end factor analysis for speaker verification, ” IEEE T rans- actions on Audio, Speech, and Language Pr ocessing , vol. 19, no. 4, pp. 788–798, 2011. [4] P . Kenny , “Joint factor analysis of speaker and session v ariability: Theory and algorithms, ” T ech. Rep., 2005. [5] S. Ioffe, “Probabilistic linear discriminant analysis, ” pp. 531–542, 2006. [6] S. J. Prince and J. H. Elder , “Probabilistic linear discriminant anal- ysis for inferences about identity , ” in 2007 IEEE 11th Interna- tional Conference on Computer V ision . IEEE, 2007, pp. 1–8. [7] D. Garcia-Romero and C. Y . Espy-W ilson, “ Analysis of i-vector length normalization in speaker recognition systems, ” in T welfth Annual Confer ence of the International Speech Communication Association , 2011. [8] E. V ariani, X. Lei, E. McDermott, I. L. Moreno, and J. Gonzalez- Dominguez, “Deep neural netw orks for small footprint text- dependent speaker verification, ” in 2014 IEEE International Con- fer ence on Acoustics, Speech and Signal Processing (ICASSP) . IEEE, 2014, pp. 4052–4056. [9] G. Heigold, I. Moreno, S. Bengio, and N. Shazeer , “End-to- end text-dependent speaker verification, ” in 2016 IEEE Interna- tional Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) . IEEE, 2016, pp. 5115–5119. [10] L. Li, Y . Chen, Y . Shi, Z. T ang, and D. W ang, “Deep speaker feature learning for text-independent speaker verification, ” in In- terspeech , 2017, pp. 1542–1546. [11] D. Snyder , D. Garcia-Romero, G. Sell, D. Pove y , and S. Khudan- pur , “X-vectors: Robust dnn embeddings for speaker recognition, ” in 2018 IEEE International Conference on Acoustics, Speech and Signal Pr ocessing (ICASSP) . IEEE, 2018, pp. 5329–5333. [12] S.-X. Zhang, Z. Chen, Y . Zhao, J. Li, and Y . Gong, “End-to-end at- tention based text-dependent speaker verification, ” in 2016 IEEE Spoken Language T echnology W orkshop (SLT) . IEEE, 2016, pp. 171–178. [13] D. Snyder , P . Ghahremani, D. Pov ey , D. Garcia-Romero, Y . Carmiel, and S. Khudanpur, “Deep neural network-based speaker embeddings for end-to-end speaker verification, ” in 2016 IEEE Spoken Language T echnology W orkshop (SLT) . IEEE, 2016, pp. 165–170. [14] D. Snyder , D. Garcia-Romero, A. McCree, G. Sell, D. Povey , and S. Khudanpur, “Spoken language recognition using x- vectors, ” in Pr oc. Odyssey 2018 The Speaker and Language Recognition W orkshop , 2018, pp. 105–111. [Online]. A vailable: http://dx.doi.org/10.21437/Odysse y .2018- 15 [15] W . Cai, J. Chen, and M. Li, “Exploring the encoding layer and loss function in end-to-end speaker and language recognition system, ” in Pr oc. Odysse y 2018 The Speaker and Language Recognition W orkshop , 2018, pp. 74–81. [Online]. A vailable: http://dx.doi.org/10.21437/Odysse y .2018- 11 [16] L. Li, Z. T ang, Y . Shi, and D. W ang, “Gaussian-constrained train- ing for speaker verification, ” in 2019 IEEE International Confer- ence on Acoustics, Speech and Signal Processing (ICASSP) , 2019. [17] D. P . Kingma and M. W elling, “ Auto-encoding variational bayes, ” arXiv preprint arXiv:1312.6114 , 2013. [18] A. Nagrani, J. S. Chung, and A. Zisserman, “V oxceleb: a large-scale speaker identification dataset, ” arXiv preprint arXiv:1706.08612 , 2017. [19] D. Snyder, G. Chen, and D. Pove y , “MUSAN: A Music, Speech, and Noise Corpus, ” 2015. [20] T . K o, V . Peddinti, D. Pove y , M. L. Seltzer , and S. Khudanpur , “ A study on data augmentation of re verberant speech for robust speech recognition, ” in 2017 IEEE International Conference on Acoustics, Speech and Signal Pr ocessing (ICASSP) . IEEE, 2017, pp. 5220–5224. [21] M. McLaren, L. Ferrer , D. Castan, and A. La wson, “The speak ers in the wild (SITW) speak er recognition database. ” in Interspeech , 2016, pp. 818–822. [22] D. Pov ey , A. Ghoshal, G. Boulianne, L. Burget, O. Glembek, N. Goel, M. Hannemann, P . Motlicek, Y . Qian, P . Schwarz et al. , “The kaldi speech recognition toolkit, ” in IEEE 2011 workshop on automatic speech r ecognition and understanding , no. EPFL- CONF-192584. IEEE Signal Processing Society , 2011. [23] D. Garcia-Romero, X. Zhang, A. McCree, and D. Pove y , “Im- proving speaker recognition performance in the domain adapta- tion challenge using deep neural networks, ” in 2014 IEEE Spoken Language T echnology W orkshop (SLT) . IEEE, 2014, pp. 378– 383.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment