Audio-Based Activities of Daily Living (ADL) Recognition with Large-Scale Acoustic Embeddings from Online Videos
Over the years, activity sensing and recognition has been shown to play a key enabling role in a wide range of applications, from sustainability and human-computer interaction to health care. While many recognition tasks have traditionally employed inertial sensors, acoustic-based methods offer the benefit of capturing rich contextual information, which can be useful when discriminating complex activities. Given the emergence of deep learning techniques and leveraging new, large-scaled multi-media datasets, this paper revisits the opportunity of training audio-based classifiers without the onerous and time-consuming task of annotating audio data. We propose a framework for audio-based activity recognition that makes use of millions of embedding features from public online video sound clips. Based on the combination of oversampling and deep learning approaches, our framework does not require further feature processing or outliers filtering as in prior work. We evaluated our approach in the context of Activities of Daily Living (ADL) by recognizing 15 everyday activities with 14 participants in their own homes, achieving 64.2% and 83.6% averaged within-subject accuracy in terms of top-1 and top-3 classification respectively. Individual class performance was also examined in the paper to further study the co-occurrence characteristics of the activities and the robustness of the framework.
💡 Research Summary
The paper presents a novel framework for recognizing Activities of Daily Living (ADL) using only ambient audio, without any manually collected or annotated training recordings. The authors exploit Google’s AudioSet, a massive public dataset consisting of over two million 10‑second audio clips harvested from YouTube videos. Each clip is represented by a 128‑dimensional embedding extracted from the bottleneck layer of a VGG‑like deep neural network that was pre‑trained on the YouTube‑100M corpus. AudioSet provides a hierarchical ontology of 527 sound classes, but none of these classes correspond directly to the everyday household activities the authors wish to detect. To bridge this gap, the authors manually map 15 target ADL (e.g., bathing, hand‑washing, toilet flushing, brushing teeth, shaving, chopping, frying, boiling water, squeezing juice, using a microwave, watching TV, listening to piano music, floor cleaning, chatting, and outdoor strolling) to 18 AudioSet labels (e.g., “water tap”, “sink”, “toilet flush”, “electric shaver”, “chopping (food)”, etc.). This mapping is necessarily subjective, but it allows the entire set of embeddings belonging to the selected AudioSet labels to serve as the sole training data.
Because AudioSet is highly unbalanced—some sound classes contain tens of thousands of samples while others have only a few hundred—the authors employ a simple oversampling strategy to equalize class frequencies before training. No additional data augmentation, outlier removal, or semi‑supervised learning is performed; the authors argue that the pre‑trained embeddings are already robust to noise and that oversampling suffices to mitigate imbalance.
The classification model itself is a straightforward deep neural network that ingests the 128‑dimensional embeddings and outputs a probability distribution over the 15 ADL classes via a soft‑max layer. Although the exact architecture (number of hidden layers, activation functions, regularization) is not detailed, the description suggests a multi‑layer perceptron (MLP) trained with cross‑entropy loss and optimized with Adam.
To evaluate the approach, a user study was conducted with 14 participants in their own homes. Each participant performed the 15 activities while a standard smartphone microphone recorded the ambient sound. The recordings were segmented into 10‑second windows and fed through the same embedding extractor used for AudioSet, ensuring that training and test representations are compatible. A within‑subject cross‑validation protocol was adopted, meaning that the model was trained on the AudioSet data plus the participant’s own recordings (excluding the test segment) and then tested on unseen segments from the same participant.
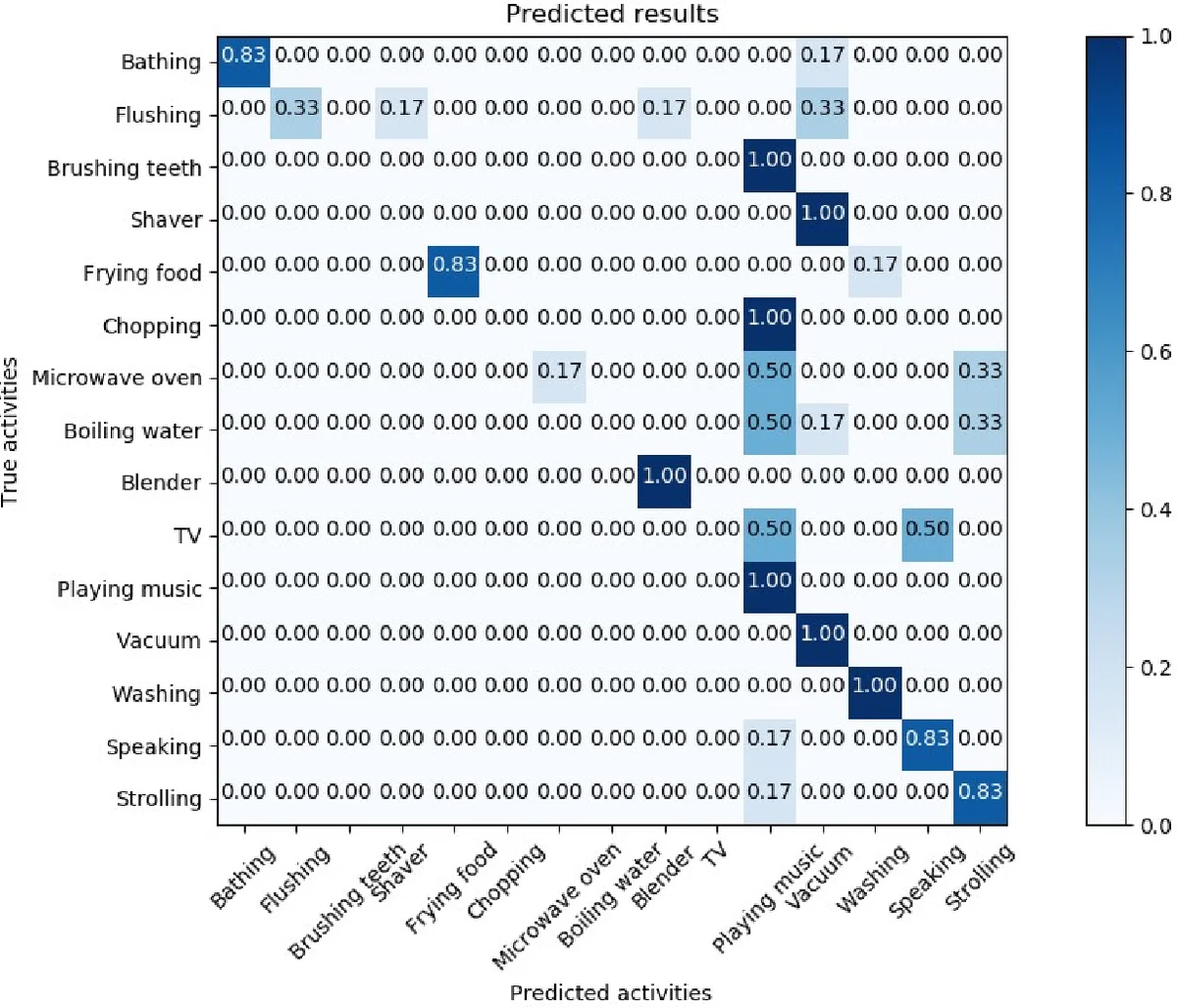
Results show a top‑1 (exact match) accuracy of 64.2 % and a top‑3 (correct label appears among the three highest‑scoring predictions) accuracy of 83.6 % across all participants and activities. Class‑wise analysis reveals that activities with distinctive, loud acoustic signatures—such as running water, microwave beeps, or vacuum‑cleaner noise—achieve high recognition rates (>80 %). In contrast, activities that generate subtle or overlapping sounds (e.g., “listening to music” versus “watching TV”, or “chatting”) exhibit more confusion, reflecting the limitations of relying solely on audio cues.
The authors also explore co‑occurrence patterns, noting that certain activities frequently happen together (e.g., music listening while watching TV), which can lead to misclassifications. This observation underscores the need for more nuanced label mapping or multimodal fusion in future work.
Key contributions of the paper are:
- Demonstrating that large‑scale, publicly available audio embeddings can replace costly, user‑collected training data for ADL recognition.
- Showing that simple oversampling is sufficient to handle severe class imbalance in such massive datasets, eliminating the need for complex preprocessing pipelines.
- Providing an empirical validation of the method in realistic home environments with multiple participants, achieving competitive top‑3 performance without any feature engineering or outlier filtering.
Limitations include the subjective nature of the AudioSet‑to‑ADL label mapping, the relatively small and homogeneous participant pool, and the reliance on activities that produce strong acoustic signatures. The framework also struggles with activities that are quiet or acoustically ambiguous. Future directions suggested by the authors involve automated label alignment using text‑audio embeddings, incorporation of additional sensor modalities (e.g., video, inertial data) to resolve ambiguities, and scaling the user study to more diverse households.
In summary, this work establishes a cost‑effective, scalable pathway for audio‑based activity recognition by leveraging the unprecedented scale of online video sound embeddings, opening new possibilities for smart‑home monitoring, elder‑care assistance, and context‑aware human‑computer interaction.
Comments & Academic Discussion
Loading comments...
Leave a Comment