An Evolutionary Framework for Automatic and Guided Discovery of Algorithms
This paper presents Automatic Algorithm Discoverer (AAD), an evolutionary framework for synthesizing programs of high complexity. To guide evolution, prior evolutionary algorithms have depended on fitness (objective) functions, which are challenging to design. To make evolutionary progress, instead, AAD employs Problem Guided Evolution (PGE), which requires introduction of a group of problems together. With PGE, solutions discovered for simpler problems are used to solve more complex problems in the same group. PGE also enables several new evolutionary strategies, and naturally yields to High-Performance Computing (HPC) techniques. We find that PGE and related evolutionary strategies enable AAD to discover algorithms of similar or higher complexity relative to the state-of-the-art. Specifically, AAD produces Python code for 29 array/vector problems ranging from min, max, reverse, to more challenging problems like sorting and matrix-vector multiplication. Additionally, we find that AAD shows adaptability to constrained environments/inputs and demonstrates outside-of-the-box problem solving abilities.
💡 Research Summary
The paper introduces Automatic Algorithm Discoverer (AAD), an evolutionary framework that synthesizes high‑complexity programs without relying on explicitly designed fitness functions. Instead of a traditional objective, AAD employs Problem Guided Evolution (PGE), a paradigm in which a set of related problems is presented together; solutions to simpler problems are automatically reused as building blocks for more complex ones. This mirrors how humans learn by solving progressively harder tasks and eliminates the need to craft problem‑specific fitness measures, which is often the bottleneck in evolutionary search for sophisticated algorithms.
AAD operates on a restricted subset of Python, defining a grammar that includes four primitive types—numbers (NUM), booleans (BOOL), arrays (ARR), and arrays‑of‑arrays (AoA, used for matrices). Each operand in an expression is annotated as a Producer (write‑only), Consumer (read‑only), or ProdCon (read‑modify‑write). These annotations enable the system to reason about data flow, enforce scoping rules, and dramatically prune the search space, especially for in‑place operations such as list.append or pop.
The solution generation pipeline consists of three phases. In Phase 1, the Evolver creates a skeletal function (SolFunc) by placing the input arguments at the top and the return statement at the bottom, then randomly inserting expressions or idioms (pre‑defined code patterns such as loops or conditionals) between them. The insertion proceeds bottom‑up: starting from the return, the Evolver selects an expression that produces the required return type, then recursively supplies producers for each of its consumer operands, thereby constructing a directed acyclic graph of data dependencies. Phase 2 links each consumer operand to a concrete producer by assigning unique integer IDs, ensuring that producers are visible to their consumers within the same lexical scope; when scoping violations occur, the system aliases the producer to an equivalent variable at the appropriate level. Phase 3 applies lightweight mutations: arithmetic operators (+, –, *, //) can be swapped, and function calls (e.g., Min ↔ Max) can be replaced with type‑compatible alternatives, providing a cheap way to explore neighboring programs without rebuilding the entire graph.
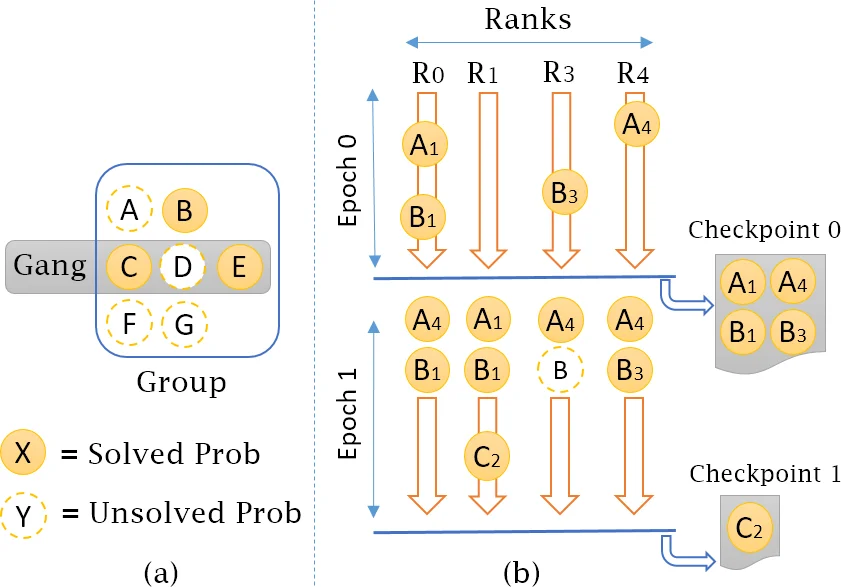
AAD’s evolutionary strategies extend beyond a single problem. The Composition strategy records any accepted solution as a callable function; subsequent problems in the same group may invoke these functions, effectively composing complex algorithms from previously discovered sub‑routines. Cross‑Pollination exchanges sub‑solutions between different problem groups, while Ganged Evolution evolves an entire problem set simultaneously, allowing a breakthrough in one problem to immediately benefit the others. Because each candidate program is evaluated independently, the whole process maps naturally onto high‑performance computing (HPC) resources: populations can be distributed across nodes, and the checking phase (execution of the generated Python code) can be parallelized without communication overhead.
The Checker component is problem‑specific but does not need a reference implementation. For example, the sorting checker merely verifies that the output list contains exactly the same elements as the input and that they appear in non‑decreasing order; it does not require the generated code to be efficient. This design dramatically reduces verification cost while still guaranteeing functional correctness.
In experiments, AAD was tasked with 29 array/vector problems ranging from trivial (minimum, maximum, reverse) to more demanding (sorting, matrix‑vector multiplication). For the sorting task, a group of ten related problems (min, max, first/last index, reverse, remove‑first/last, membership, ascending/descending sort) was supplied. AAD discovered a sorting algorithm that repeatedly extracts the minimum element, appends it to a new list, and removes it from the original list—a correct but not optimal solution, demonstrating that the system can synthesize non‑trivial algorithms from elementary primitives. Across all benchmarks, AAD produced correct Python programs, showed adaptability to constrained inputs (e.g., fixed‑size arrays) and resource limits, and exhibited “outside‑the‑box” solutions that differed from conventional textbook implementations.
The authors acknowledge several limitations and outline future work. Automatic grouping of related problems remains manual; developing methods to infer or learn such groupings would reduce human effort. Extending the grammar to support recursion, higher‑order functions, and richer data structures would broaden the class of discoverable algorithms. Finally, applying AAD to real‑world software engineering tasks and scaling it on large HPC clusters are identified as promising directions.
Overall, the paper presents a compelling alternative to fitness‑driven evolutionary program synthesis. By leveraging problem‑guided evolution and a carefully engineered expression store, AAD demonstrates that complex algorithmic behavior can emerge automatically, even when the evaluation metric is reduced to simple functional correctness. This work opens new avenues for automated software generation, especially in domains where defining a precise objective is difficult but a suite of related tasks is available.
Comments & Academic Discussion
Loading comments...
Leave a Comment