Growing graphs with addition of communities
Paper proposes a model of large networks based on a random preferential attachment graph with addition of complete subgraphs (cliques). The proposed model refers to models of random graphs following the nonlinear preferential attachment rule and takes into account the possibility of {\guillemotleft}adding{\guillemotright} entire communities of nodes to the network. In the derivation of the relations that determine the vertex degree distribution, the technique of finite-difference equations describing stationary states of a graph is used. The obtained results are tested empirically (by generating large graphs), special cases correspond to known mathematical relations.
💡 Research Summary
The paper introduces a novel growth model for large‑scale networks that extends the classic preferential attachment (PA) framework by allowing the addition of whole communities, represented as complete subgraphs (cliques). Traditional PA models assume that each new vertex connects to existing vertices with probability proportional to their degree, which yields a scale‑free degree distribution. However, many real‑world systems—social platforms, collaboration networks, biological interaction maps—exhibit bursts of growth where entire tightly‑connected groups appear simultaneously. To capture this phenomenon, the authors propose a two‑fold stochastic rule set. With probability (1-p) a single vertex is added according to a nonlinear PA kernel (f(k)=k+\alpha) (α≥0). With probability (p) a clique of fixed size (m) is inserted. Inside the clique every vertex has degree (m-1); each vertex also creates one external link to the existing network, the target being chosen by the same PA kernel.
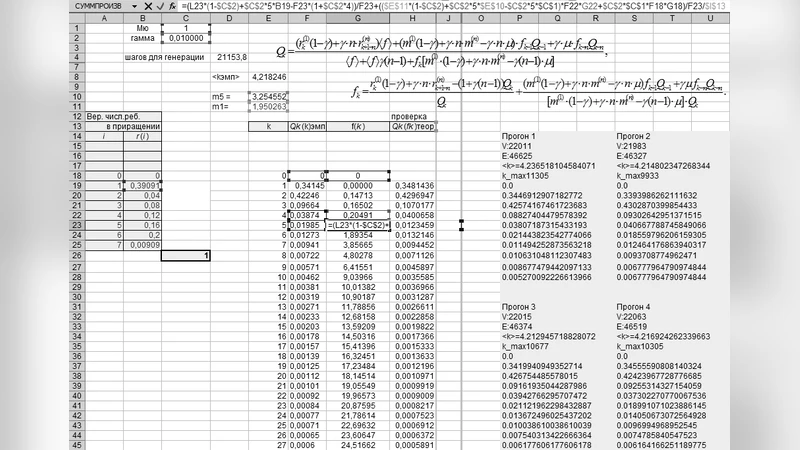
The analytical core relies on finite‑difference equations describing the stationary state of the degree distribution. Let (N_k(t)) be the expected number of vertices of degree (k) at time (t). By enumerating the contributions of the two growth events to (N_k(t+1)-N_k(t)) and imposing the steady‑state condition (\lim_{t\to\infty} N_k(t)/N(t)=\pi_k), the authors derive a recursive relation for (\pi_k) that explicitly contains the parameters (p) and (m). In the limiting cases (p=0) (pure PA) and (m=2) (the added “clique” reduces to a single edge) the recursion collapses to the well‑known solutions, confirming consistency with existing theory.
Solving the recursion yields a mixed degree distribution. For large (k) the tail follows a power law (\pi_k\propto k^{-(\gamma+\Delta)}), where (\gamma) is the exponent of the underlying PA process and (\Delta) is a positive correction that grows with both the insertion probability (p) and the clique size (m). Consequently, higher values of (p) or larger cliques steepen the tail, reducing the prevalence of very high‑degree hubs. In the intermediate range a pronounced peak appears at degree (k=m-1), reflecting the fixed internal degree of newly inserted cliques; this feature is absent in pure PA models.
To validate the theory, the authors generate synthetic networks up to one million vertices for a grid of parameter pairs ((p,m)). Empirical degree histograms match the analytical (\pi_k) with high fidelity, and the predicted intermediate‑degree peak is clearly observable for moderate (p) (e.g., (p=0.3)) and larger cliques ((m=5)). Beyond degree statistics, the study measures clustering coefficient and average shortest‑path length. As (m) increases, clustering rises sharply while the average path length contracts, indicating that community insertion dramatically enhances network cohesion and information‑flow efficiency—behaviors commonly reported in empirical social networks.
The discussion highlights several avenues for extension. The current model assumes fully connected cliques; real communities often exhibit partial connectivity, hierarchical substructures, or evolving internal topology. Introducing an internal edge‑density parameter or allowing (p) and (m) to evolve over time would produce a richer class of dynamic networks. Moreover, fitting the model to real data (e.g., Reddit sub‑communities, Facebook groups, protein complexes) could provide estimates of the effective community‑insertion rate and clique size distribution, thereby offering predictive insight into how macro‑scale network properties emerge from micro‑scale group formation processes.
In summary, by integrating community‑level addition into the preferential‑attachment paradigm, the paper delivers a mathematically tractable yet more realistic description of network growth, elucidates how such mechanisms reshape degree distributions, clustering, and path lengths, and opens a clear path toward empirical calibration and further theoretical refinement.
Comments & Academic Discussion
Loading comments...
Leave a Comment