Batch Size Influence on Performance of Graphic and Tensor Processing Units during Training and Inference Phases
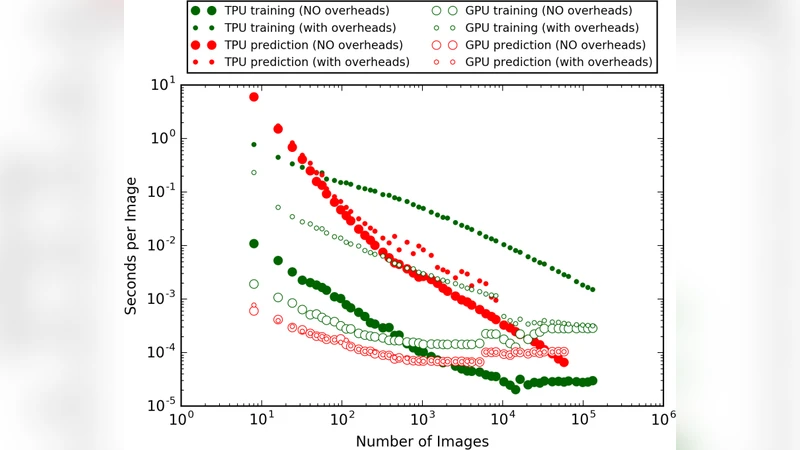
The impact of the maximally possible batch size (for the better runtime) on performance of graphic processing units (GPU) and tensor processing units (TPU) during training and inference phases is investigated. The numerous runs of the selected deep neural network (DNN) were performed on the standard MNIST and Fashion-MNIST datasets. The significant speedup was obtained even for extremely low-scale usage of Google TPUv2 units (8 cores only) in comparison to the quite powerful GPU NVIDIA Tesla K80 card with the speedup up to 10x for training stage (without taking into account the overheads) and speedup up to 2x for prediction stage (with and without taking into account overheads). The precise speedup values depend on the utilization level of TPUv2 units and increase with the increase of the data volume under processing, but for the datasets used in this work (MNIST and Fashion-MNIST with images of sizes 28x28) the speedup was observed for batch sizes >512 images for training phase and >40 000 images for prediction phase. It should be noted that these results were obtained without detriment to the prediction accuracy and loss that were equal for both GPU and TPU runs up to the 3rd significant digit for MNIST dataset, and up to the 2nd significant digit for Fashion-MNIST dataset.
💡 Research Summary
The paper investigates how the maximum feasible batch size influences the performance of graphics processing units (GPUs) and tensor processing units (TPUs) during both training and inference phases of deep neural networks. The authors conduct extensive experiments using two widely adopted benchmark datasets—MNIST and Fashion‑MNIST—each consisting of 60 000 training and 10 000 test images of size 28 × 28 pixels. A modest convolutional neural network (CNN) architecture with two convolutional layers followed by two fully‑connected layers is employed; this model is deliberately simple to keep experiment runtimes reasonable while still achieving high classification accuracy (≈99% on MNIST, ≈92% on Fashion‑MNIST).
Hardware platforms consist of an NVIDIA Tesla K80 GPU and a Google Cloud TPU v2 configured with eight cores. Both platforms are accessed through Google Colab, and the same TensorFlow 2.x environment is used to eliminate software‑stack bias. Batch sizes are varied from 8 up to 13 000 images, with larger batches created by duplicating images when memory limits are reached. Two timing metrics are recorded: (1) “time with overheads,” measured as the wall‑clock time of the first epoch divided by the number of images (including data loading, graph compilation, and device initialization), and (2) “time without overheads,” measured on the second epoch to capture pure computational latency. Speed‑up is defined as the GPU runtime divided by the TPU runtime for each batch size.
Key findings are as follows. During training, once the batch size exceeds 512 images, the TPU begins to outperform the GPU, and the advantage grows sharply with larger batches. At a batch size of 8 192 images, the TPU achieves up to a ten‑fold speed‑up over the K80 when overheads are excluded. This dramatic gain is attributed to the TPU’s architecture: a 700 MHz clock driving 65 536 8‑bit multiply‑add units in parallel, delivering an instruction‑per‑cycle count on the order of 10⁵, far surpassing the K80’s ≈10⁴. In contrast, the GPU’s performance plateaus because its memory bandwidth and compute unit count limit the degree of data‑level parallelism that can be exploited.
For inference, the TPU’s advantage appears at much larger batch sizes—around 40 000 images—where it delivers up to a two‑fold speed‑up relative to the GPU. The authors explain that inference is more sensitive to data‑transfer and preprocessing overheads; only when the batch is sufficiently large does the TPU’s raw compute throughput dominate the total latency.
Crucially, the acceleration does not come at the cost of model quality. Accuracy and loss values are virtually identical on both platforms: MNIST yields 0.99 ± 0.0004 accuracy with 0.02 ± 0.0002 loss, while Fashion‑MNIST yields 0.92 ± 0.005 accuracy with 0.24 ± 0.003 loss. ROC‑AUC curves and area‑under‑curve metrics also match, confirming that the 8‑bit integer arithmetic used by the TPU does not degrade predictive performance compared with FP32 on the GPU.
The paper acknowledges several limitations. The chosen network is shallow, so the results may not extrapolate to deeper, parameter‑heavy models such as ResNet‑50 or transformer‑based architectures. Batch size expansion via image duplication does not faithfully represent real‑world data pipelines where I/O bandwidth can become a bottleneck. Only an 8‑core TPU v2 configuration is examined; larger TPU pods or newer generations (v3/v4) could exhibit different scaling characteristics. Finally, measuring overhead only at the epoch level makes it difficult to isolate the exact cost of graph compilation versus data movement.
Despite these caveats, the study provides solid empirical evidence that, for workloads with sufficiently large batches, TPUs can deliver up to ten times faster training and up to two times faster inference than a relatively powerful GPU, without sacrificing accuracy. This insight is especially relevant for applications requiring high‑throughput processing of massive image streams, such as advanced driver‑assistance systems, real‑time traffic monitoring, or large‑scale video analytics. Future work should explore a broader set of network architectures, incorporate memory‑saving techniques like quantization and pruning, and benchmark newer TPU and GPU generations to develop more comprehensive guidelines for hardware selection in deep‑learning pipelines.
Comments & Academic Discussion
Loading comments...
Leave a Comment