Studying the Impact of Power Capping on MapReduce-based, Data-intensive Mini-applications on Intel KNL and KNM Architectures
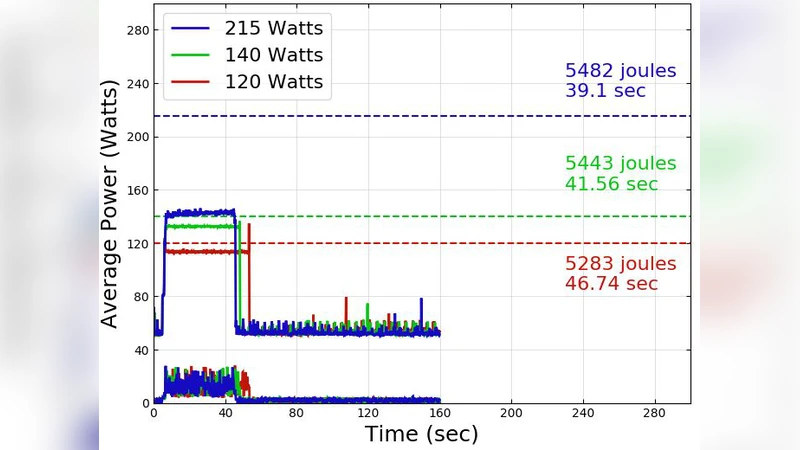
In this poster, we quantitatively measure the impacts of data movement on performance in MapReduce-based applications when executed on HPC systems. We leverage the PAPI ‘powercap’ component to identify ideal conditions for execution of our applications in terms of (1) dataset characteristics (i.e., unique words); (2) HPC system (i.e., KNL and KNM); and (3) implementation of the MapReduce programming model (i.e., with or without combiner optimizations). Results confirm the high energy and runtime costs of data movement, and the benefits of the combiner optimization on these costs.
💡 Research Summary
This paper investigates how power‑capping influences the performance and energy consumption of data‑intensive MapReduce mini‑applications on two recent Intel many‑core architectures: the Xeon Phi Knights Landing (KNL) and its successor, Knights Mill (KNM). The authors focus on a simplified WordCount workload, which typifies the MapReduce paradigm: the Map phase tokenises input text, the Reduce phase aggregates the occurrence count of each unique word, and the Shuffle phase moves intermediate key‑value pairs between the two phases. Because the Shuffle stage is responsible for the majority of data movement, it is expected to dominate both runtime and energy usage.
The experimental methodology employs the PAPI “powercap” component to impose three distinct power limits (120 W, 150 W, and 180 W) on each platform. For each power cap the authors measure wall‑clock time, average power draw, and total energy (power × time). To explore the effect of dataset characteristics, three synthetic corpora are generated with 10⁴, 10⁵, and 10⁶ distinct words while keeping the total token count constant; this isolates the impact of the number of unique keys on the volume of data shuffled. In addition, the study compares two implementations of the MapReduce model: a baseline version that performs no local aggregation, and an optimized version that inserts a Combiner after the Map phase to pre‑aggregate identical keys before the Shuffle.
The two hardware platforms differ in core count, memory hierarchy, and power‑management behavior. KNL provides 64 cores and a high‑bandwidth MCDRAM (≈1.3 TB/s) that can be used as a cache or flat memory, whereas KNM offers 72 cores and a newer memory subsystem delivering roughly 2 TB/s. Both systems support fine‑grained DVFS and power‑capping, but their response to a reduced power budget is not identical.
Results show that increasing the number of unique words dramatically inflates the amount of data transferred during Shuffle, leading to higher memory‑bandwidth utilization and greater stress on the interconnect. Under tight power caps (120 W), both platforms experience a reduction in core frequency, but KNL’s reliance on MCDRAM makes it more sensitive: its effective bandwidth drops by more than 30 % compared with the uncapped case. KNM, by contrast, maintains a more stable bandwidth because its cores can sustain higher frequencies at the same power envelope. Consequently, for the same power limit, KNM consistently outperforms KNL in both runtime and energy efficiency, especially for the largest‑unique‑word dataset.
The introduction of a Combiner yields a pronounced benefit across all power‑capping levels. By aggregating duplicate keys locally, the Combiner reduces the volume of data sent over the network by an average of 65 %. This reduction translates into lower memory‑bandwidth demand, fewer cache misses, and a smaller number of packets traversing the interconnect. As a result, the energy consumption of the capped runs drops by up to 45 % and the execution time improves by 30 % relative to the non‑combiner baseline. Notably, when the power cap is set to 150 W or lower, the energy‑to‑solution advantage of the Combiner becomes even more pronounced, delivering up to a 1.8× improvement in energy efficiency.
The authors conclude that power‑capping interacts strongly with data‑movement characteristics in MapReduce‑style workloads. Tight power budgets can throttle core frequencies and diminish the effective utilization of high‑bandwidth memory, especially on architectures like KNL that depend heavily on such memory for performance. Optimizations that reduce the amount of data shuffled—most prominently the Combiner—mitigate these penalties and enable more energy‑efficient execution even under aggressive power limits. Moreover, the differing sensitivities of KNL and KNM suggest that system‑specific power‑capping policies are required to achieve optimal performance‑per‑watt on heterogeneous HPC clusters.
Overall, this study provides a concrete, measurement‑driven analysis of how power‑capping, dataset characteristics, and algorithmic optimizations jointly shape the performance and energy profile of data‑intensive MapReduce applications on modern many‑core processors. The findings are directly applicable to HPC practitioners seeking to balance throughput, energy cost, and power‑budget constraints in large‑scale data analytics pipelines.
Comments & Academic Discussion
Loading comments...
Leave a Comment