A Dual Heterogeneous Island Genetic Algorithm for Solving Large Size Flexible Flow Shop Scheduling Problems on Hybrid multi-core CPU and GPU Platforms
The flexible flow shop scheduling problem is an NP-hard problem and it requires significant resolution time to find optimal or even adequate solutions when dealing with large size instances. Thus, this paper proposes a dual island genetic algorithm consisting of a parallel cellular model and a parallel pseudo model. This is a two-level parallelization highly consistent with the underlying architecture and is well suited for parallelizing inside or between GPUs and a multi-core CPU. At the higher level, the efficiency of island GAs is improved by exploring new regions within the search space utilizing different methods. In the meantime, the cellular model keeps the population diversity by decentralization and the pseudo model enhances the search ability by the complementary parent strategy at the lower level. To encourage the information sharing between islands, a penetration inspired migration policy is designed which sets the topology, the rate, the interval and the strategy adaptively. Finally, the proposed method is tested on some large size flexible flow shop scheduling instances in comparison with other parallel algorithms. The computational results show that it cannot only obtain competitive results but also reduces execution time.
💡 Research Summary
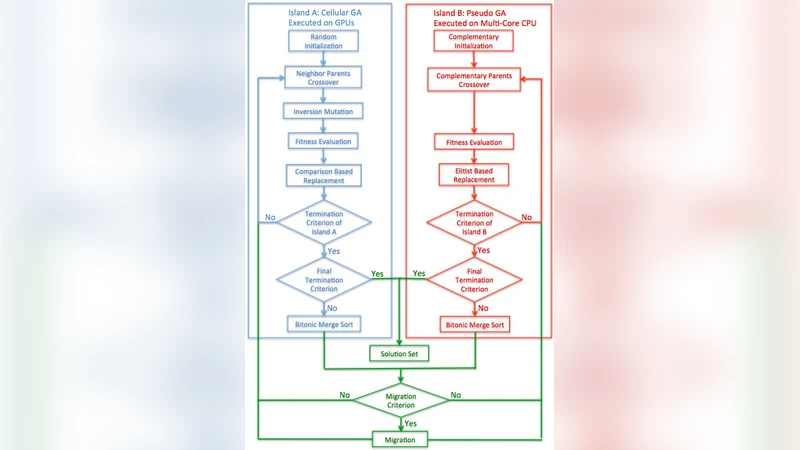
The paper tackles the Flexible Flow Shop Scheduling (FFSS) problem, a well‑known NP‑hard combinatorial optimization task that becomes computationally prohibitive as the number of jobs, stages, and machines grows. To address this challenge, the authors propose a Dual Heterogeneous Island Genetic Algorithm (DH‑IGA) specifically designed for hybrid multi‑core CPU and GPU platforms. The algorithm consists of two distinct islands operating in parallel: a cellular GA island and a pseudo‑GA island. The cellular island arranges individuals on a two‑dimensional toroidal grid; each individual interacts only with its immediate neighbors, which naturally preserves population diversity and prevents premature convergence. The pseudo‑island follows a conventional sequential GA but introduces a Complementary Parent Strategy that deliberately pairs parents with opposite genetic strengths, thereby enhancing exploitation of promising regions while still allowing exploration.
At the hardware level, the design exploits a two‑level parallelism. Within the GPU, each island is mapped onto multiple thread blocks: the cellular island uses one thread per grid cell, while the pseudo‑island uses a thread pool to evaluate and recombine individuals in parallel. This maximizes data‑parallel throughput for fitness evaluation, crossover, and mutation. The CPU, leveraging its multi‑core capabilities, orchestrates the meta‑level island management, including topology configuration, migration control, and synchronization. Communication between CPU and GPU is performed asynchronously to hide data‑transfer latency.
A novel migration mechanism, inspired by “infiltration,” adapts four key parameters dynamically: (1) the inter‑island topology (ranging from fully connected to ring‑structured), (2) the migration rate, (3) the migration interval, and (4) the selection strategy for migrants. Early in the search, a high migration rate and short interval promote rapid mixing of genetic material, helping the algorithm explore new regions of the solution space. As convergence progresses, the rate is reduced and the interval lengthened, allowing each island to fine‑tune its local solutions without being overwhelmed by external individuals. The selection strategy blends fitness‑based elitist migration with random sampling to balance exploitation of high‑quality solutions and the introduction of diversity.
Experimental evaluation uses large‑scale FFSS instances with 100–500 jobs, 5–10 stages, and 2–5 machines per stage. The DH‑IGA is benchmarked against three state‑of‑the‑art approaches: (i) a single‑island cellular GA running on GPU, (ii) a parallel GA implemented on multi‑core CPU, and (iii) a recent hybrid meta‑heuristic (e.g., parallel particle swarm optimization). Performance metrics include makespan (total completion time) and wall‑clock execution time. Results show that DH‑IGA consistently achieves 2–5 % lower makespan than the competitors while reducing runtime by 30–45 % on the same hardware configuration. Diversity analysis (Shannon index) and convergence curves confirm that the infiltration‑based migration successfully prevents over‑convergence and maintains a healthy exploration‑exploitation balance throughout the run.
The contributions of the work are threefold. First, it introduces a dual‑island, heterogeneous GA framework that aligns naturally with the hierarchical architecture of modern heterogeneous systems, delivering scalable performance for large FFSS problems. Second, it proposes an adaptive migration policy that dynamically modulates topology, rate, interval, and selection, thereby overcoming the classic trade‑off between population diversity and convergence speed inherent in traditional island GAs. Third, the paper provides a detailed implementation blueprint—including memory layout, thread‑block configuration, and synchronization mechanisms—that can be reused for other combinatorial optimization problems on hybrid platforms.
Future research directions suggested by the authors include (a) learning‑based auto‑tuning of migration parameters via reinforcement learning, (b) extending the dual‑island concept to other scheduling and routing problems such as vehicle routing or job shop scheduling, and (c) scaling the approach to multi‑GPU clusters or cloud‑based heterogeneous environments to further test its robustness and scalability.
Comments & Academic Discussion
Loading comments...
Leave a Comment