Towards Emotion Recognition: A Persistent Entropy Application
Emotion recognition and classification is a very active area of research. In this paper, we present a first approach to emotion classification using persistent entropy and support vector machines. A topology-based model is applied to obtain a single real number from each raw signal. These data are used as input of a support vector machine to classify signals into 8 different emotions (calm, happy, sad, angry, fearful, disgust and surprised).
💡 Research Summary
The paper proposes a novel framework for speech‑based emotion recognition that combines tools from topological data analysis (TDA) with conventional machine‑learning classifiers. Instead of extracting a suite of acoustic descriptors (pitch, MFCCs, energy, etc.), the authors treat each raw audio waveform as a piecewise‑linear function and compute a single scalar descriptor—persistent entropy—derived from the lower‑star filtration of the function.
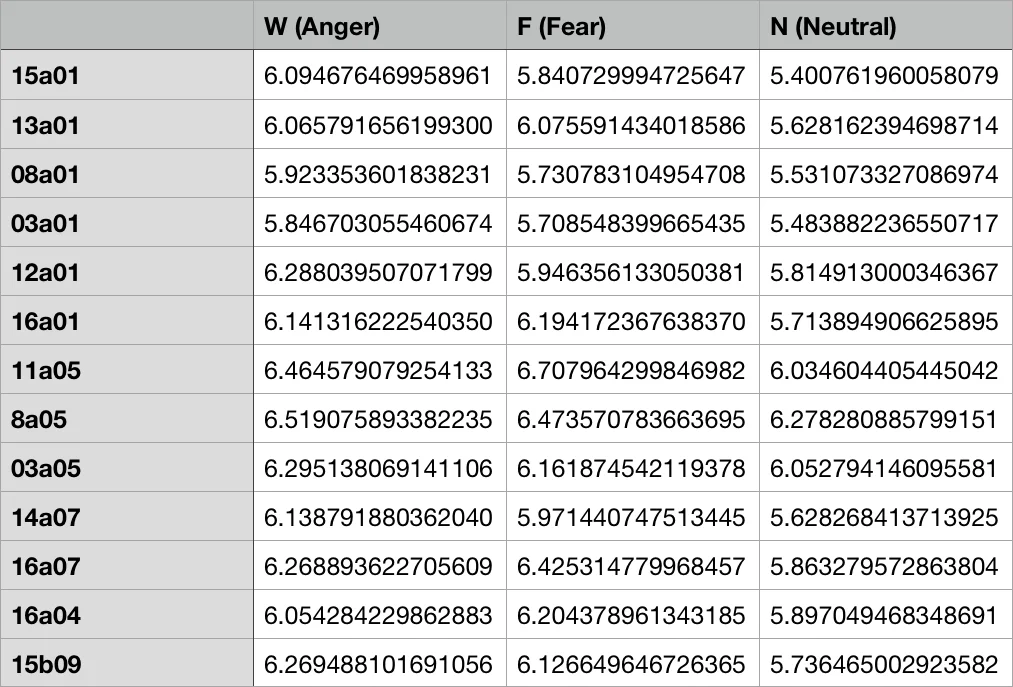
The methodology proceeds as follows. First, each audio signal from the RAVDESS corpus (24 actors, 60 utterances per actor, 8 emotion categories, 1 440 recordings) is uniformly down‑sampled from roughly 197 k points to 10 k points to keep the computational cost of persistent homology manageable while preserving the overall shape of the waveform. A tiny amount of imperceptible noise is added to guarantee that no two samples share the same amplitude, a prerequisite for the lower‑star filtration. The lower‑star filtration orders the vertices by their function values and builds a nested sequence of simplicial complexes; from this filtration the 0‑dimensional (connected components) and 1‑dimensional (loops) persistence barcodes are extracted.
Persistent entropy is then calculated by normalising each barcode interval length (l_i) to a probability (p_i = l_i / \sum_j l_j) and applying the Shannon entropy formula (E = -\sum_i p_i \log p_i). This single number summarises the distribution of birth‑death pairs in the barcode and, thanks to the stability theorem for persistent entropy, is robust to small perturbations of the signal.
These entropy values are fed to a support vector machine (SVM). The authors test three kernels—linear, polynomial, and Gaussian (RBF)—and select the one delivering the highest cross‑validation accuracy. Three experimental configurations are examined.
-
Naïve single‑value approach: each recording is represented by its own entropy value. Using a linear kernel, the classifier achieves only 20.3 % accuracy, confirming that a one‑dimensional embedding cannot capture the multi‑faceted nature of emotional expression.
-
Actor‑averaged vector approach: for each emotion, the 24 entropy values produced by the 24 different actors are concatenated into a 24‑dimensional feature vector. With a Gaussian kernel, the SVM reaches over 92 % accuracy (training on 40 vectors, testing on 20). This result demonstrates that aggregating across speakers mitigates individual variability and yields a discriminative representation.
-
Sex‑aware analysis: the authors compute Pearson correlation matrices for entropy values within male and female subsets. Correlations are moderate among same‑sex recordings but low across sexes, suggesting that gender‑specific models could further improve performance.
Box‑plots of entropy by emotion reveal substantial overlap among categories, indicating that entropy alone cannot separate emotions cleanly. However, the plots also show consistent peaks within each gender, hinting at systematic patterns that could be exploited.
The paper concludes that persistent entropy provides a compact, noise‑stable descriptor of speech waveforms, but its discriminative power is limited when used in isolation. Multi‑dimensional representations (e.g., vectors of actor‑specific entropies) are necessary for high‑accuracy classification. The authors propose several avenues for future work: (i) learning directly from persistence barcodes using deep neural networks or kernel methods tailored to barcode similarity, (ii) integrating visual cues (facial expressions, gestures) for multimodal emotion recognition, and (iii) developing gender‑ or speaker‑adapted models to exploit the observed correlation structure.
Overall, the study introduces a fresh topological perspective to affective computing, showing that while topological summaries alone are insufficient, they can complement traditional acoustic features and open new research directions in robust, low‑dimensional emotion representation.
Comments & Academic Discussion
Loading comments...
Leave a Comment