Twins Recognition with Multi Biometric System: Handcrafted-Deep Learning Based Multi Algorithm with Voice-Ear Recognition Based Multi Modal
With the development of technology, the usage areas and importance of biometric systems have started to increase. Since the characteristics of each person are different from each other, a single model biometric system can yield successful results. However, because the characteristics of twin people are very close to each other, multiple biometric systems including multiple characteristics of individuals will be more appropriate and will increase the recognition rate. In this study, a multiple biometric recognition system consisting of a combination of multiple algorithms and multiple models was developed to distinguish people from other people and their twins. Ear and voice biometric data were used for the multimodal model and 38 pair of twin ear images and sound recordings were used in the data set. Sound and ear recognition rates were obtained using classical (hand-crafted) and deep learning algorithms. The results obtained were combined with the score level fusion method to achieve a success rate of 94.74% in rank-1 and 100% in rank -2.
💡 Research Summary
The paper addresses the challenging problem of distinguishing identical twins by proposing a multimodal biometric system that fuses ear image and voice data. Recognizing that a single biometric trait is insufficient for twins—whose physiological characteristics are extremely similar—the authors construct a three‑layered architecture: (1) multiple modalities (ear and voice), (2) multiple algorithms (hand‑crafted feature extractors and deep learning models), and (3) multiple models (separate classifiers for each modality).
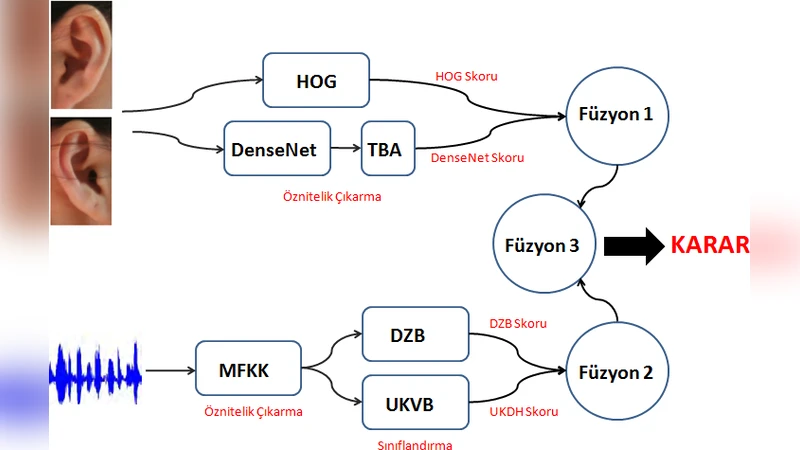
The dataset consists of 38 twin pairs (76 individuals). For each person, a left and right ear photograph and three voice recordings are available; two recordings are used for training and one for testing. Ear recognition employs two parallel pipelines: a traditional HOG (Histogram of Oriented Gradients) descriptor and a DenseNet convolutional neural network. Because DenseNet produces high‑dimensional feature vectors, the authors apply a custom dimensionality reduction technique called Total Variance Analysis (TBA) to reduce computational load. HOG yields a modest 38.16 % identification rate, while DenseNet+TBA improves this to 51.32 %.
Voice recognition also follows a dual‑pipeline approach. Mel‑Frequency Cepstral Coefficients (MFCC) are extracted as the primary acoustic features. Two classifiers are then applied: (a) Dynamic Time Warping (DTW) based matching, which aligns temporal variations in speech and achieves a high 90.79 % accuracy, and (b) an LSTM‑based Unscented Kalman Variational Bayes (UKVB) model that captures long‑term dependencies but only reaches 61.84 % accuracy. The disparity highlights the robustness of DTW for small, controlled datasets versus the data‑hungry nature of deep recurrent networks.
All matching scores are first normalized using a tanh function to place them on a common scale. The authors then perform score‑level fusion in a hierarchical manner. In the first fusion layer, scores from the two ear algorithms are combined, and separately, scores from the two voice algorithms are merged. In the second layer, the fused ear score and the fused voice score are combined to produce a final decision. Fusion weights are empirically set, giving the voice modality a higher weight (0.85) than the ear modality (0.15), reflecting its superior individual performance.
The final fused system achieves a Rank‑1 identification rate of 94.74 % and a Rank‑2 rate of 100 %, with an area under the ROC curve (AUC) of 99.97. These results surpass previously reported twin‑identification systems, which typically attain around 81 % Rank‑1 accuracy. The authors attribute the improvement to the complementary nature of hand‑crafted and deep learning features, as well as the hierarchical score‑level fusion that effectively balances contributions from each algorithm and modality.
Despite the promising performance, the study acknowledges limitations: the dataset is small and collected under controlled conditions, which may inflate accuracy. Future work is suggested to include larger, unconstrained datasets, additional biometric traits (e.g., face, fingerprint), real‑time processing optimizations, and privacy‑preserving fusion mechanisms. Overall, the paper demonstrates that a thoughtfully designed multimodal, multi‑algorithm biometric framework can reliably differentiate individuals whose biometric signatures are otherwise nearly indistinguishable.
Comments & Academic Discussion
Loading comments...
Leave a Comment