An "On The Fly" Framework for Efficiently Generating Synthetic Big Data Sets
Collecting, analyzing and gaining insight from large volumes of data is now the norm in an ever increasing number of industries. Data analytics techniques, such as machine learning, are powerful tools used to analyze these large volumes of data. Synthetic data sets are routinely relied upon to train and develop such data analytics methods for several reasons: to generate larger data sets than are available, to generate diverse data sets, to preserve anonymity in data sets with sensitive information, etc. Processing, transmitting and storing data is a key issue faced when handling large data sets. This paper presents an “On the fly” framework for generating big synthetic data sets, suitable for these data analytics methods, that is both computationally efficient and applicable to a diverse set of problems. An example application of the proposed framework is presented along with a mathematical analysis of its computational efficiency, demonstrating its effectiveness.
💡 Research Summary
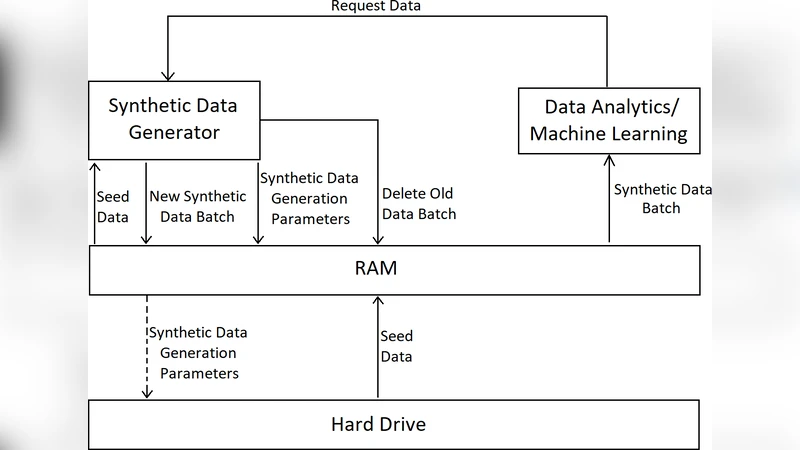
The paper addresses a fundamental bottleneck in modern data‑driven research and industry: the generation, storage, and handling of massive synthetic datasets. Traditional pipelines first generate an entire synthetic dataset, write it to disk, and later read it back into memory for analysis. While straightforward, this “generate‑then‑store” approach quickly becomes infeasible when the dataset size grows to gigabytes or terabytes, because it demands large upfront CPU time, substantial RAM for the generation phase, and extensive disk space for the resulting data. Moreover, the repeated I/O required to load the data for each analysis step adds considerable latency.
To overcome these limitations, the authors propose an “On‑the‑fly” (OTF) framework that merges data generation and consumption into a single, tightly coupled loop. The key idea is to generate data in batches only when the downstream analytics algorithm requests it, keep the current batch in RAM, and discard it as soon as it is no longer needed. Instead of persisting the full batch, the framework records a compact set of generation parameters (e.g., seed identifiers, scaling coefficients, noise identifiers). These parameters are orders of magnitude smaller than the raw data; in the energy‑consumption example, 86 400 time‑series values are replaced by just four parameters, a compression factor of 21 600. The parameters can be stored in RAM or written to disk, depending on whether the batch may need to be regenerated later.
The OTF workflow proceeds as follows:
- Request – The analytics algorithm signals the size of the next batch it can process, based on available RAM.
- Cleanup – The previous batch is freed; its generation parameters are optionally saved for reproducibility.
- Generation – A seed dataset (loaded once at the start) is transformed using the stored parameters to produce the new batch.
- Consumption – The analytics algorithm works directly on the in‑memory batch.
- Finalization – Upon program termination, all parameter logs are persisted for future reconstruction.
The authors illustrate the framework with a concrete energy‑consumption classification task. A daily consumption profile (86 400 seconds) serves as the seed; synthetic data are produced by scaling the seed and a noise profile with coefficients λ₁ and λ₂ (Equation 1). To reproduce any batch later, only the tuple
Comments & Academic Discussion
Loading comments...
Leave a Comment