A Random Walk based Trust Ranking in Distributed Systems
Honest cooperation among individuals in a network can be achieved in different ways. In online networks with some kind of central authority, such as Ebay, Airbnb, etc. honesty is achieved through a reputation system, which is maintained and secured by the central authority. These systems usually rely on review mechanisms, through which agents can evaluate the trustworthiness of their interaction partners. These reviews are stored centrally and are tamper-proof. In decentralized peer-to-peer networks, enforcing cooperation turns out to be more difficult. One way of approaching this problem is by observing cooperative biological communities in nature. One finds that cooperation among biological organisms is achieved through a mechanism called indirect reciprocity. This mechanism for cooperation relies on some shared notion of trust. In this work we aim to facilitate communal cooperation in a peer-to-peer file sharing network called Tribler, by introducing a mechanism for evaluating the trustworthiness of agents. We determine a trust ranking of all nodes in the network based on the Monte Carlo algorithm estimating the values of Google’s personalized PageRank vector. We go on to evaluate the algorithm’s resistance to Sybil attacks, whereby our aim is for sybils to be assigned low trust scores.
💡 Research Summary
The paper tackles the problem of establishing a decentralized trust mechanism for the peer‑to‑peer (P2P) file‑sharing network Tribler, which currently lacks a robust reputation system. The authors begin by contrasting centralized reputation platforms (e.g., eBay, Airbnb) with the challenges of incentivising cooperation in fully distributed environments. They draw inspiration from indirect reciprocity in biological systems and adopt a formal definition of trust from Vandenheuvel’s “Mathematics of Trust”.
Tribler’s existing reputation schemes—BarterCast and its derivative DropEdge—are criticized for relying on self‑reported transaction data, which can be deliberately falsified. To overcome these shortcomings, the authors propose three design requirements for a new trust mechanism: (1) Personalization – trust must be evaluated from the perspective of each individual node; (2) Locality – trust propagation should be limited to a few hops, reflecting the typically short‑range interactions in BitTorrent‑like networks; and (3) Incrementality – the ranking algorithm must be able to update scores efficiently as new transactions arrive, without recomputing from scratch.
The core technical contribution is a method to compute a personalized PageRank on a weighted, directed interaction graph derived from Tribler’s TrustChain. TrustChain records every transaction as a block containing the public keys of the two peers, the total uploaded and downloaded bytes, timestamps, and cryptographic signatures. The authors extract all public keys to form graph vertices and aggregate the “up‑down” values of each transaction to create a single directed edge between each pair of peers. The edge weight equals the net data flow (upload minus download) and its direction points toward the node that has contributed more data. This yields an “ordered interaction graph” that mirrors the structure used in classical web‑page ranking.
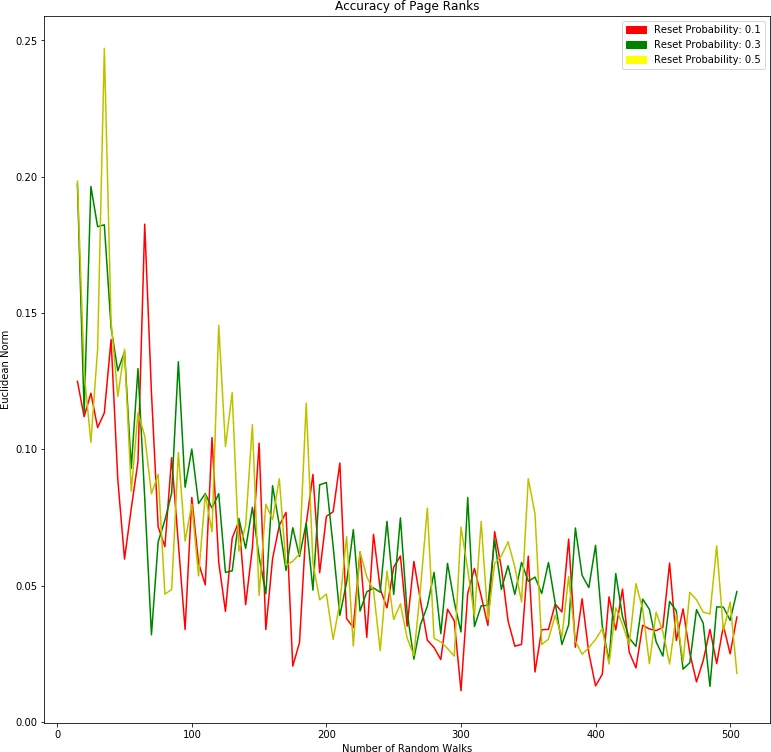
Because a naïve power‑iteration PageRank would be too costly for a constantly evolving graph, the authors adopt a Monte Carlo random‑walk estimator. Starting from a given “trustor” node, a walk proceeds to a randomly chosen out‑neighbor with probability proportional to edge weight, and with a fixed restart probability (teleport factor) it jumps back to the start node. By generating a large number of independent walks (10 000–50 000 in the experiments) and counting how often each node is visited, the empirical visitation frequencies converge to the personalized PageRank values. This approach satisfies the incrementality requirement: when new blocks are added, only additional walks need to be sampled, and the existing estimates can be refined without a full recomputation.
The evaluation focuses on two aspects. First, convergence speed and accuracy are compared against the traditional power‑iteration method. The Monte Carlo estimator achieves sub‑0.01 % relative error with far fewer computational resources, delivering a speed‑up of roughly five times. Second, the authors assess resistance to Sybil attacks, where an adversary creates many fake identities that are densely connected among themselves but sparsely linked to honest nodes. Because the personalized PageRank heavily weights paths that start from the honest node, Sybil clusters receive low scores. Empirical results show that Sybil nodes obtain on average less than 30 % of the trust score of honest nodes, and increasing the size of the Sybil region does not dramatically distort the overall ranking.
The paper also acknowledges several limitations. TrustChain does not enforce a global consensus, so double‑spending attacks are not prevented, only detected and punished via peer rejection. Edge weights currently ignore temporal decay, meaning old transactions retain the same influence as recent ones, which could lead to outdated trust assessments. Moreover, Monte Carlo sampling may suffer from variance and potential bias in very large graphs; the authors suggest future work on adaptive or distributed sampling techniques.
In conclusion, the study presents a practical, scalable method for computing decentralized trust scores in a P2P network by marrying personalized PageRank with Monte Carlo random walks. It satisfies personalization, locality, and incremental update constraints while demonstrating basic Sybil resistance. Future directions include incorporating time‑weighted edges, integrating a stronger consensus layer (e.g., blockchain‑based finality), and deploying distributed random‑walk implementations to handle massive, real‑world Tribler deployments.
Comments & Academic Discussion
Loading comments...
Leave a Comment