Managed Forgetting to Support Information Management and Knowledge Work
Trends like digital transformation even intensify the already overwhelming mass of information knowledge workers face in their daily life. To counter this, we have been investigating knowledge work and information management support measures inspired by human forgetting. In this paper, we give an overview of solutions we have found during the last five years as well as challenges that still need to be tackled. Additionally, we share experiences gained with the prototype of a first forgetful information system used 24/7 in our daily work for the last three years. We also address the untapped potential of more explicated user context as well as features inspired by Memory Inhibition, which is our current focus of research.
💡 Research Summary
The paper addresses the overwhelming amount of information that knowledge workers face, especially under the pressure of digital transformation, by proposing a “Managed Forgetting” (MF) approach inspired by human memory processes. The authors review five years of research conducted in the EU ForgetIT project (2013‑2016) and the German DFG‑funded Managed Forgetting project (2016‑2019), and they share practical experience from a prototype Forgetful Information System (FIS) that has been used continuously for three years in the authors’ daily work.
MF is defined as a graduated set of measures that go beyond the binary keep‑or‑delete paradigm. It progresses through stages: temporary hiding, condensation, adaptive synchronization, archiving, and eventual deletion. The implementation rests on a Semantic Desktop (SemDesk) ecosystem that represents all digital artefacts—files, emails, contacts, events, topics, etc.—as “things” with unique URIs and RDF metadata. These things are organized in a Personal Information Model (PIMO) for each user and a Group Information Model (GIMO) for collaborative contexts, forming a rich, machine‑readable knowledge graph that mirrors the user’s mental model.
A central quantitative indicator is Memory Buoyancy (MB), which reflects the current relevance of each thing for a specific user. MB is calculated from evidence collected automatically from user actions (view, create, modify) and propagated through the graph using a spreading activation algorithm. The algorithm takes into account thing types, predicate semantics, connection density, and a set of heuristics. Over time, MB decays steeply for unattended items and then follows a long‑tail decline; repeated stimulation slows the decay, mirroring the reinforcement of memory in the brain. Decay curves are customized per item class—e‑mails decay faster than presentations—based on their intrinsic ephemerality. Upcoming events stimulate associated items before their date and accelerate decay afterward if not re‑stimulated.
The system operationalizes MF in several concrete ways. First, items whose MB falls below a configurable threshold are hidden from the user interface. The threshold is lower on desktop devices and higher on mobile devices to reduce cognitive load while on the move. Users can reveal hidden items via a “show forgotten” button and adjust thresholds dynamically. In search results, low‑MB items are filtered out, and a slider lets users blend forgotten items back into the ranking. Snippets displayed for search results are also curated to include only high‑MB annotations, providing concise relevance cues without overwhelming the user.
Adaptive synchronization constitutes the next MF tier. Files with low MB are automatically moved from local storage to cloud storage or an archive, while their semantic representation remains in the graph. If a user later needs the file, it is fetched on demand. Conversely, items with high MB are kept locally, ensuring that the device contains only the most relevant documents for the current user mindset.
Condensation is applied when an entire sub‑graph (e.g., a completed project or long‑finished task) has uniformly low MB. The system can generate a condensed representation—a summary node that references the underlying items—allowing the user to retain a high‑level view while the detailed items may be archived or deleted. The PIMO Diary component implements on‑demand condensation for user footprints within a selected time window.
The prototype has been running 24/7 for three years, managing a semantic graph of more than 18 000 things, including about 2 000 private items. Over seven years of usage, the system accumulated more than 1 000 task footprints, each with associated resources, topics, and notes. The authors observed that MB values indeed fade gradually when relevance declines, and that related items can be “pulled up” through indirect stimulation, forming a dynamic “hotspot” that reflects the user’s current mindset. However, user behavior revealed trust issues: many users reset the search‑filter slider to zero to see all results when the filtered list was unsatisfactory, indicating insufficient confidence in the MF decisions. Additionally, isolated graph regions can drop in MB despite still being relevant, because the current algorithm heavily weights connectivity. This points to a need for more sophisticated context‑aware linking and automatic reintegration mechanisms.
The paper also discusses the concept of “preservation value,” an orthogonal measure that captures long‑term importance of items that may have low short‑term MB but should be retained for future reference.
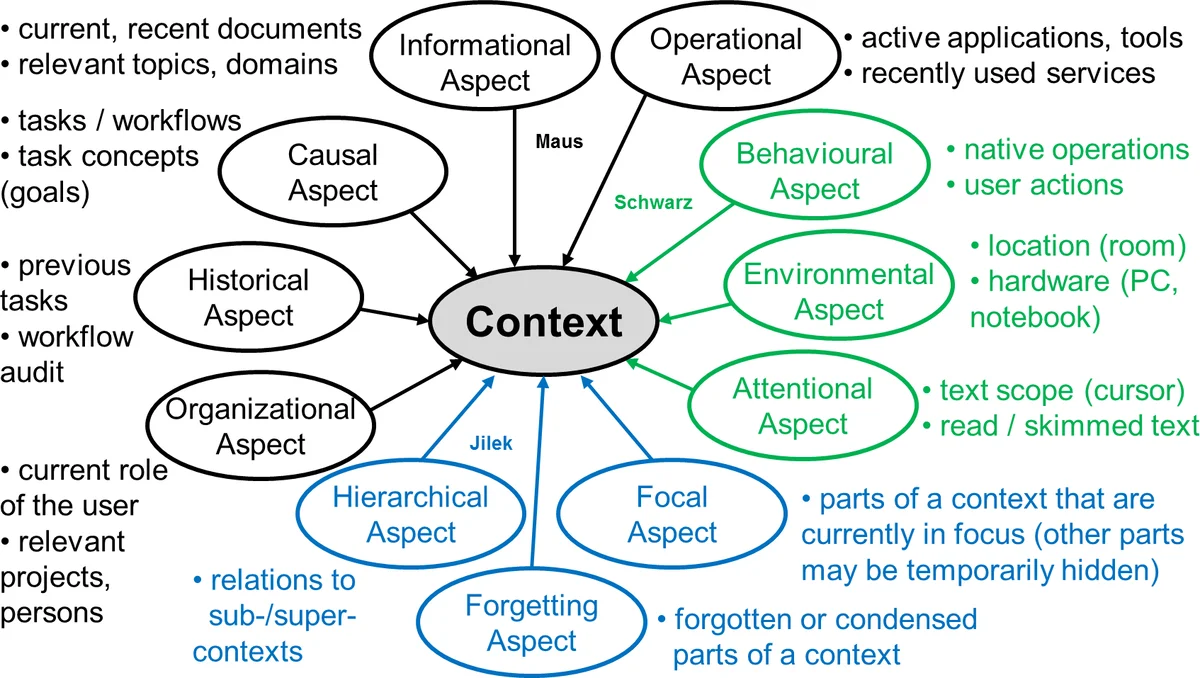
Looking forward, the authors identify two major research directions. First, they aim to exploit explicit user context more thoroughly, collecting richer contextual cues (e.g., task goals, workspace, temporal patterns) to refine MB calculations and MF actions. Second, they plan to incorporate principles from Memory Inhibition—a cognitive process that suppresses competing memories—to actively dampen the activation of irrelevant or distracting items, thereby sharpening focus on the current task.
In summary, this work presents a pioneering, empirically validated framework for intentional forgetting in information systems. By integrating a semantic knowledge graph, evidence‑driven relevance assessment, and a multi‑stage forgetting pipeline, the authors demonstrate that human‑inspired forgetting can be operationalized to alleviate information overload, improve retrieval efficiency, and support sustainable knowledge management in both individual and collaborative settings. Future work will refine context modeling, inhibition mechanisms, and long‑term preservation strategies to enhance trust and effectiveness of managed forgetting.
Comments & Academic Discussion
Loading comments...
Leave a Comment