Towards Deriving Verification Properties
Formal software verification uses mathematical techniques to establish that software has certain properties. For example, that the behaviour of a software system satisfies certain logically-specified properties. Formal methods have a long history, but a recurring assumption is that the properties to be verified are known, or provided as part of the requirements elicitation process. This working note considers the question: where do the verification properties come from? It proposes a process for systematically identifying verification properties.
💡 Research Summary
This working note addresses a fundamental yet often overlooked question in formal software verification: where do the properties that we verify actually come from? The paper critiques the common assumption that verification properties (φ) are simply given or emerge naturally from requirements, arguing that their derivation is a significant challenge in itself.
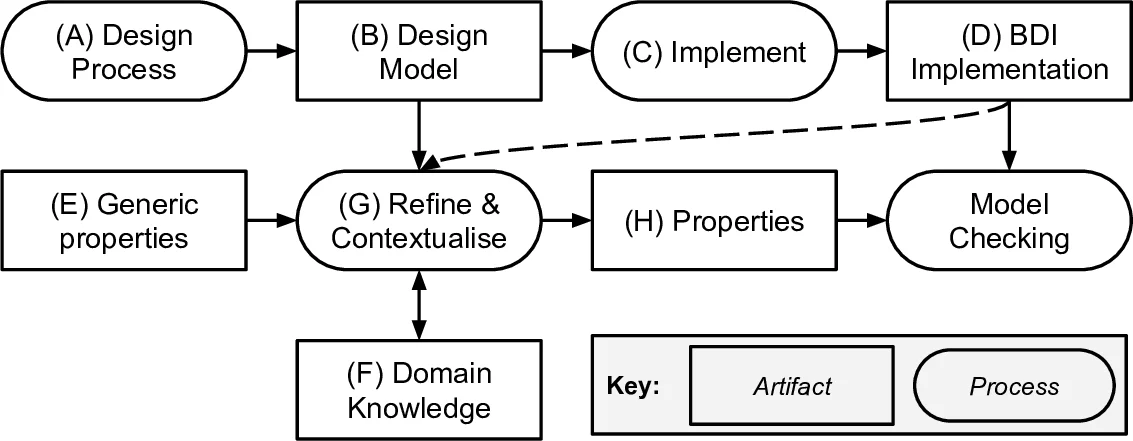
The core contribution is a pragmatic, top-down process for systematically deriving verification properties. The process begins with high-level, informal “tenets” (e.g., “do no harm”), which represent the ultimate assurance goals for a system. It then methodically refines these tenets into concrete, formally specifiable properties using two key sources: domain knowledge (represented as logical implications) and the system’s design model, specifically a goal tree. The refinement is captured in an intermediate “refinement tree,” where each node describes a set of system behaviors, and children nodes are more specific conditions that imply their parent node. The relationship ensures traceability from abstract tenets to concrete properties.
The detailed process algorithm works on the negation of a tenet (e.g., “cause harm”). It iteratively refines leaf nodes of this tree until they can be directly formalized in a logic like Linear Temporal Logic (LTL). The refinement strategies include: (0) direct formalization when possible; (1) applying domain knowledge rules to replace a general concept with its specific definition or consequence; (2) using the goal-tree structure to identify which system goals are relevant to violating or upholding the tenet; and (3a/3b) if stuck, expanding the goal tree or eliciting new domain knowledge. Finally, the LTL formulas at the leaves are negated to produce the set of properties that must hold to ensure the original tenet.
The paper illustrates the process with a running example of a home-care robot (Care-O-bot). Starting from the tenet “keep the person safe/healthy,” it demonstrates how domain knowledge (e.g., defining “enough food” as “three meals a day”) and the robot’s goal tree (with goals like “remind to take medication”) are used to derive specific LTL properties such as ensuring reminders are issued for meals and that the medication administered matches what was prescribed.
The author acknowledges similarities to van Lamsweerde and Letier’s obstacle derivation technique but highlights a key difference: while obstacle analysis starts from formalized system goals, this process starts from the broader, informal tenets we truly care about safeguarding. The proposed framework is presented as an early sketch, identifying limitations like the need for human judgment during refinement and the difficulty of capturing probabilistic domains with standard LTL. Its primary value lies in providing a structured starting point for turning the ad-hoc “art” of property derivation into a more systematic engineering practice.
Comments & Academic Discussion
Loading comments...
Leave a Comment