M$^3$RL: Mind-aware Multi-agent Management Reinforcement Learning
Most of the prior work on multi-agent reinforcement learning (MARL) achieves optimal collaboration by directly controlling the agents to maximize a common reward. In this paper, we aim to address this from a different angle. In particular, we consider scenarios where there are self-interested agents (i.e., worker agents) which have their own minds (preferences, intentions, skills, etc.) and can not be dictated to perform tasks they do not wish to do. For achieving optimal coordination among these agents, we train a super agent (i.e., the manager) to manage them by first inferring their minds based on both current and past observations and then initiating contracts to assign suitable tasks to workers and promise to reward them with corresponding bonuses so that they will agree to work together. The objective of the manager is maximizing the overall productivity as well as minimizing payments made to the workers for ad-hoc worker teaming. To train the manager, we propose Mind-aware Multi-agent Management Reinforcement Learning (M^3RL), which consists of agent modeling and policy learning. We have evaluated our approach in two environments, Resource Collection and Crafting, to simulate multi-agent management problems with various task settings and multiple designs for the worker agents. The experimental results have validated the effectiveness of our approach in modeling worker agents’ minds online, and in achieving optimal ad-hoc teaming with good generalization and fast adaptation.
💡 Research Summary
**
The paper tackles a realistic multi‑agent coordination problem in which a set of self‑interested “worker” agents each possess private preferences, skills, and intentions, and cannot be forced to execute tasks they do not wish to perform. Instead of training all agents to directly maximize a shared reward (the usual MARL paradigm), the authors introduce a hierarchical manager–worker architecture. The manager’s role is to infer each worker’s “mind” (preferences, intentions, skills) from observed behavior and then issue contracts that pair a specific goal with a monetary bonus. Workers decide whether to accept a contract and, if they do, they attempt to achieve the assigned goal, possibly deviating if the goal is unreachable or the bonus insufficient.
The proposed framework, Mind‑aware Multi‑agent Management Reinforcement Learning (M³RL), consists of three main modules:
-
Performance History Module – For each worker‑goal‑bonus triple the manager maintains an empirical success probability ρₜᵢᵍᵇ (the chance the worker finishes the goal within t steps after signing the contract). This matrix is updated in an Upper‑Confidence‑Bound (UCB) style and flattened into a vector hᵢ that encodes the worker’s past performance.
-
Mind Tracker Module – Using the current episode’s trajectory Γᵢₜ = {(sτᵢ, aτᵢ, gτᵢ, bτᵢ)}₍τ≤t₎ together with the history embedding hᵢ, a shared‑weight LSTM network produces an online estimate mᵢₜ of the worker’s internal state (its current intention and skill estimate). The tracker is pretrained via imitation learning on simulated worker behavior.
-
Manager Module – All workers’ (state, mind estimate, history) tuples are pooled into a context vector cₜ₊₁ = C({(sᵢₜ₊₁, mᵢₜ, hᵢ)}). Two policy networks then output (i) a goal‑selection policy πᵍ and (ii) a bonus‑selection policy πᵇ. Goal selection leverages a high‑level Successor Representation (SR) to quickly approximate long‑term value Q(s,g) for each possible goal, while bonus selection uses an ε‑greedy scheme that is applied per‑worker, encouraging more exploration on agents whose behavior is still uncertain.
Training proceeds with an actor‑critic RL algorithm: the manager receives a reward at each timestep equal to the sum over workers of (manager utility for the completed goal minus the promised bonus) whenever a worker’s state matches the assigned goal. The SR is updated via TD‑error, the performance‑history matrices are refreshed after each contract outcome, and the mind‑tracker continues to be refined online.
The authors evaluate M³RL in two 2‑D Minecraft‑style environments:
- Resource Collection – Workers must gather different resource types; each resource has a distinct utility for the manager. Workers have heterogeneous skill‑resource mappings and private preferences.
- Crafting – Workers must first collect raw resources and then combine them into composite items, introducing task dependencies and delayed, sparse rewards.
Both environments feature stochastic worker policies, possible deceptive behavior (accepting contracts they cannot fulfill), and dynamic team composition (workers are sampled from a large population each episode). In testing, the manager is confronted with a completely unseen population to assess generalization.
Key empirical findings:
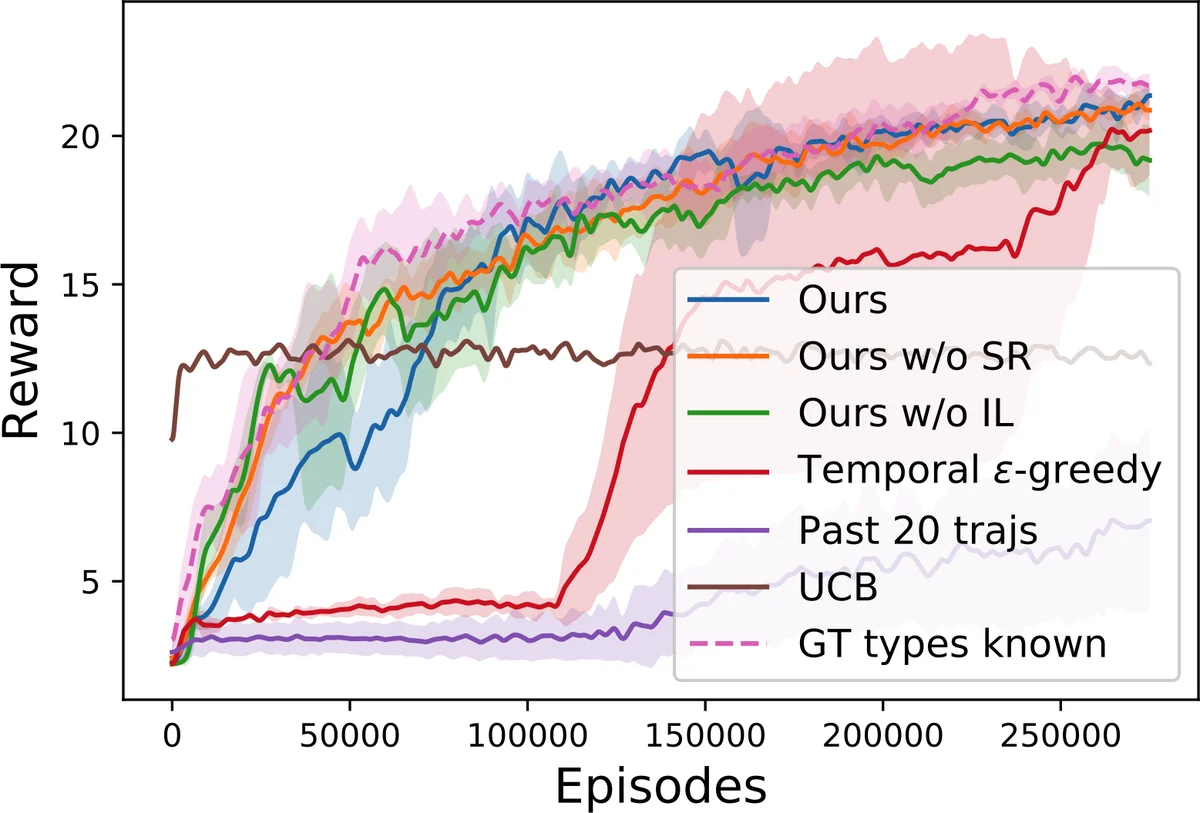
- The mind‑tracker predicts each worker’s true preference and skill vector with >90 % accuracy (F1 score), demonstrating effective online inference.
- Contract‑based management yields a 30–45 % increase in total manager reward compared to baseline MARL methods that train workers to directly maximize a common objective.
- The manager learns to allocate bonuses efficiently, reducing average bonus expenditure by ~20 % while maintaining or improving task‑completion rates.
- When team composition changes or new worker types appear, the manager adapts within 5–10 episodes, showing rapid transfer of learned policies.
- Ablation studies reveal that removing SR, the per‑agent ε‑greedy exploration, or the performance‑history module each degrades overall reward by 15–25 %, confirming the necessity of all components.
The paper situates its contribution at the intersection of principal‑agent problems in economics, mechanism design, and multi‑agent reinforcement learning. Unlike classic mechanism‑design approaches that assume known utility functions and static games, M³RL learns a data‑driven contract policy without any prior knowledge of worker utilities, and it handles sequential decision‑making with evolving agents. The authors also discuss limitations: the current model does not capture workers’ beliefs about the manager (i.e., a full Theory of Mind), and bonuses are restricted to a discrete set, which may limit applicability to domains requiring continuous incentive design.
In summary, M³RL introduces a novel, end‑to‑end RL framework that equips a manager with the ability to (1) infer hidden worker characteristics from limited observations, (2) generate adaptive contracts that align self‑interested agents with a global objective, and (3) generalize across varying team sizes and unseen worker populations. The experimental results convincingly demonstrate that such a mind‑aware, contract‑based approach can achieve superior productivity, lower incentive costs, and fast adaptation—qualities essential for real‑world multi‑agent systems such as autonomous robot fleets, distributed cloud services, and complex game AI.
Comments & Academic Discussion
Loading comments...
Leave a Comment