BOINC: A Platform for Volunteer Computing
“Volunteer computing” is the use of consumer digital devices for high-throughput scientific computing. It can provide large computing capacity at low cost, but presents challenges due to device heterogeneity, unreliability, and churn. BOINC, a widely-used open-source middleware system for volunteer computing, addresses these challenges. We describe its features, architecture, and implementation.
💡 Research Summary
The paper presents BOINC (Berkeley Open Infrastructure for Network Computing) as a mature, open‑source middleware platform that enables volunteer computing (VC) – the use of consumer devices such as desktops, laptops, tablets, and smartphones – for high‑throughput scientific workloads. The authors begin by quantifying the current state of VC: roughly 700,000 active devices contribute about 4 million CPU cores and 560,000 GPUs, delivering an average throughput of 93 PetaFLOPS. They argue that the potential is far larger, citing billions of consumer computers and mobile devices that could collectively provide hundreds of ExaFLOPS if a modest fraction of owners participated.
Cost analysis shows that operating a typical BOINC‑based project (e.g., Einstein@Home, Rosetta@Home, SETI@Home) costs on the order of $100 K per year, yet yields about 1 PetaFLOPS of sustained performance. By contrast, achieving the same performance on commercial cloud services would cost tens of millions of dollars annually, highlighting a dramatic cost advantage for VC. Energy efficiency is discussed qualitatively: data‑center nodes are more FLOPS‑per‑watt, but consumer devices often operate without dedicated cooling and can contribute waste heat to ambient environments, making a direct comparison difficult.
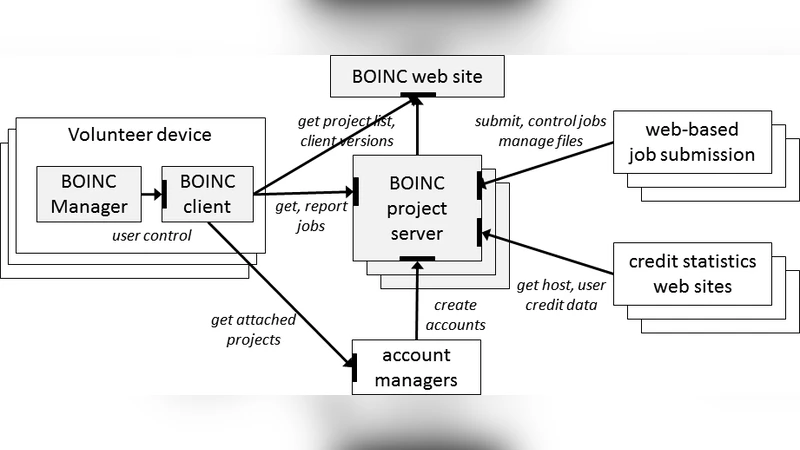
The paper then outlines the unique challenges of VC: devices are anonymous, heterogeneous (different CPUs, GPUs, operating systems), intermittently available, and subject to high churn. BOINC is designed to address each of these challenges through a modular client‑server architecture, HTTP‑based RPC communication, and a rich set of configuration and policy mechanisms.
Key architectural components include:
- Projects and Volunteers – A project runs its own BOINC server, distributes jobs, and provides web‑based community features. Volunteers install the BOINC client, create accounts on one or more projects, and allocate a “resource share” that determines long‑term computing contribution.
- Client/Server Interaction – The client periodically contacts the server, reports completed work, and fetches new jobs. All traffic is outbound HTTP, allowing operation behind firewalls and proxies. Files are compressed, hashed, and optionally code‑signed for integrity. Uploads use POST with random filenames and optional token‑based size limits to mitigate DoS attacks.
- Account Managers (AMs) – To simplify multi‑project management, BOINC supports web‑based AMs (e.g., GridRepublic, BAM!). A client attached to an AM receives a list of projects to attach or detach, enabling a single web interface to control many devices. AMs also support the “coordinated VC” model where volunteers select scientific keywords rather than individual projects.
- Computing and Keyword Preferences – Volunteers can set CPU throttling, idle‑time restrictions, memory/disk/network caps, and time‑of‑day limits. A hierarchical keyword system (science area and research location) lets volunteers express “yes” or “no” preferences, which the scheduler respects when assigning jobs.
The paper delves deeply into job processing abstractions that enable handling of extreme heterogeneity:
- Platforms, Apps, App Versions, and Plan Classes – A platform is a CPU‑OS pair (e.g., Windows‑x86_64). An app groups all versions of a scientific program; each version is tied to a platform. Plan classes are user‑defined functions that examine a host’s hardware/software description and decide whether a version can run, how many CPU/GPU fractions it will consume, and its peak FLOPS. This fine‑grained filtering allows projects such as SETI@Home to support dozens of platforms, dozens of apps, and hundreds of versions.
- Anonymous Platform Mechanism – When source code is available, volunteers may compile their own binaries and supply a local configuration file describing them. The client then advertises these “anonymous” versions to the scheduler, enabling security‑conscious users and community‑driven optimizations (e.g., GPU‑specific kernels). Projects that support this mechanism also provide reference input/output to validate volunteer‑built binaries.
- Job Properties – Each job carries estimates of FLOPs, maximum FLOPs (to abort runaway jobs), RAM working‑set size, disk usage limits, and optional scientific keywords. These metadata guide the server’s dispatch algorithm, ensuring that jobs are matched to hosts capable of satisfying resource constraints.
Result validation is achieved primarily through replication: each job is sent to two unrelated hosts; matching outputs are accepted, while mismatches trigger a third instance and possibly further replication until a quorum is reached. Projects may also embed domain‑specific sanity checks (e.g., energy conservation).
The authors describe the scheduling policy (Section 6.4, referenced but not fully reproduced) as a multi‑criteria decision process that considers host capabilities, plan‑class eligibility, estimated runtime (based on FLOP estimate and host speed), memory/disk constraints, and keyword preferences. The client reports its supported platforms and a detailed hardware description; the server selects the newest compatible app version for each job.
Overall, BOINC demonstrates how a volunteer‑driven computing ecosystem can be built at scale, delivering high‑throughput scientific workloads with minimal financial outlay while handling the intrinsic volatility of consumer devices. Its open‑source nature, extensible plug‑in architecture, and community‑driven development have enabled a broad portfolio of projects across astrophysics, bioinformatics, climate modeling, and more. The paper concludes that BOINC effectively bridges the gap between the massive, underutilized compute capacity of everyday devices and the demanding computational needs of modern science.
Comments & Academic Discussion
Loading comments...
Leave a Comment