CBinfer: Exploiting Frame-to-Frame Locality for Faster Convolutional Network Inference on Video Streams
The last few years have brought advances in computer vision at an amazing pace, grounded on new findings in deep neural network construction and training as well as the availability of large labeled datasets. Applying these networks to images demands a high computational effort and pushes the use of state-of-the-art networks on real-time video data out of reach of embedded platforms. Many recent works focus on reducing network complexity for real-time inference on embedded computing platforms. We adopt an orthogonal viewpoint and propose a novel algorithm exploiting the spatio-temporal sparsity of pixel changes. This optimized inference procedure resulted in an average speed-up of 9.1x over cuDNN on the Tegra X2 platform at a negligible accuracy loss of <0.1% and no retraining of the network for a semantic segmentation application. Similarly, an average speed-up of 7.0x has been achieved for a pose detection DNN and a reduction of 5x of the number of arithmetic operations to be performed for object detection on static camera video surveillance data. These throughput gains combined with a lower power consumption result in an energy efficiency of 511 GOp/s/W compared to 70 GOp/s/W for the baseline.
💡 Research Summary
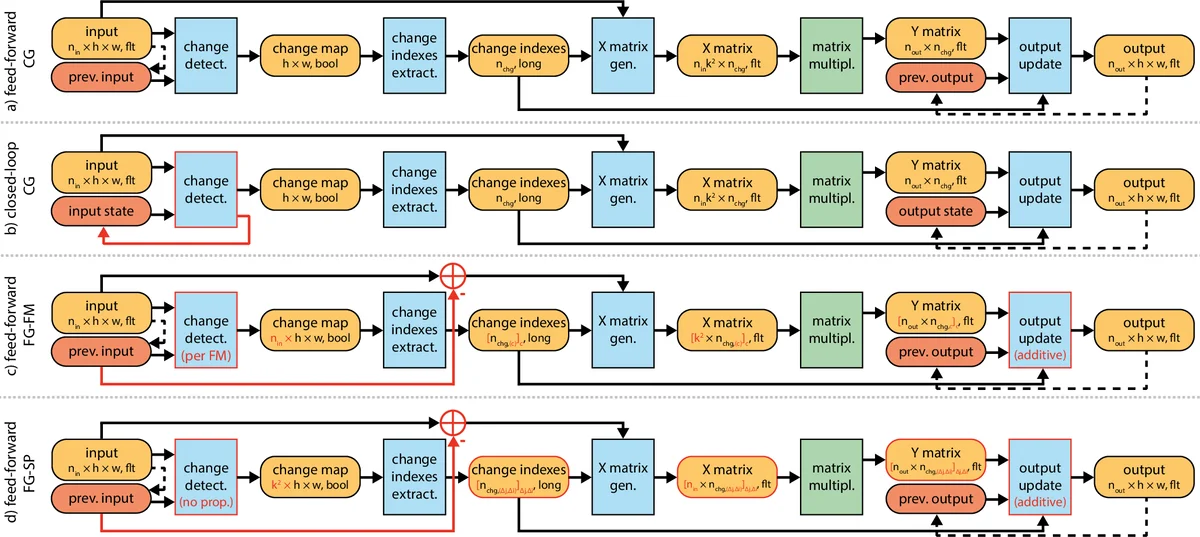
The paper introduces CBinfer, a change‑based inference technique that exploits the spatio‑temporal sparsity inherent in video streams captured by static cameras. Traditional convolutional neural network (CNN) inference recomputes the entire feature map for every frame, which is computationally prohibitive on embedded GPUs. CBinfer instead detects pixel‑wise differences between the current frame and the previous one, selects only those pixels whose absolute difference exceeds a small threshold, and expands each selected pixel to its receptive field to form an “active region.” Only the convolutions that intersect these active regions are recomputed; the rest of the feature map is simply copied from the previous frame. Because convolution is a linear operation, the authors can compute the output change directly from the input change and add it to the stored previous output, avoiding a full forward pass.
The algorithm proceeds in four steps: (1) compute a per‑pixel absolute difference and threshold it; (2) dilate the resulting change mask by the kernel’s receptive field size; (3) perform partial convolutions only on the dilated mask; (4) accumulate the partial results onto the previous frame’s activations. To prevent error accumulation when large scene changes occur, a “change‑limit” mechanism forces a full recomputation of a layer if the proportion of changed pixels exceeds a predefined bound.
The authors evaluate CBinfer on three representative vision tasks using a NVIDIA Tegra X2 SoC (≤15 W). For a 10‑class semantic segmentation network (based on Cityscapes), they achieve an average 9.1× speed‑up with less than 0.1 % drop in mean Intersection‑over‑Union (mIoU). For pose detection (OpenPose) they report a 7.0× speed‑up and a negligible accuracy loss (<0.1 %). For object detection (YOLOv3 on traffic‑surveillance video) they reduce the number of arithmetic operations by a factor of five and obtain a 6.8× reduction in per‑frame latency. Energy efficiency improves from 70 GOp/s/W (cuDNN baseline) to 511 GOp/s/W, i.e., roughly a seven‑fold gain.
CBinfer is orthogonal to other model‑level optimizations such as quantization, pruning, or low‑rank approximations. The authors demonstrate that combining 8‑bit quantization with CBinfer yields an additional 1.3× speed‑up while keeping accuracy loss under 0.1 %. The method therefore fits naturally into existing deployment pipelines for embedded vision.
Limitations include sensitivity to camera motion or abrupt illumination changes, which increase the fraction of changed pixels and trigger full‑layer recomputation, eroding the speed‑up. Moreover, the threshold that separates “changed” from “unchanged” pixels must be tuned per dataset; the paper suggests future work on adaptive thresholding and extensions to multi‑camera setups.
In summary, CBinfer provides a practical, low‑overhead way to accelerate CNN inference on static‑camera video streams. By recomputing only the portions of the network affected by genuine scene changes, it delivers order‑of‑magnitude throughput improvements and substantial energy savings while preserving the original model’s accuracy, making real‑time semantic segmentation, pose estimation, and object detection feasible on power‑constrained embedded platforms.
Comments & Academic Discussion
Loading comments...
Leave a Comment