A model of reward-modulated motor learning with parallelcortical and basal ganglia pathways
Many recent studies of the motor system are divided into two distinct approaches: Those that investigate how motor responses are encoded in cortical neurons’ firing rate dynamics and those that study the learning rules by which mammals and songbirds develop reliable motor responses. Computationally, the first approach is encapsulated by reservoir computing models, which can learn intricate motor tasks and produce internal dynamics strikingly similar to those of motor cortical neurons, but rely on biologically unrealistic learning rules. The more realistic learning rules developed by the second approach are often derived for simplified, discrete tasks in contrast to the intricate dynamics that characterize real motor responses. We bridge these two approaches to develop a biologically realistic learning rule for reservoir computing. Our algorithm learns simulated motor tasks on which previous reservoir computing algorithms fail, and reproduces experimental findings including those that relate motor learning to Parkinson’s disease and its treatment.
💡 Research Summary
The paper addresses a fundamental limitation of conventional reservoir computing (RC) models: their reliance on fully supervised learning rules that require explicit access to the target output. While RC excels at generating complex dynamical patterns when a teacher signal is available, real motor learning in mammals and songbirds proceeds with only a scalar reward signal, not a full trajectory. Existing reward‑modulated Hebbian learning (RMHL) algorithms attempt to bridge this gap, but they often fail to converge on high‑dimensional, continuous motor tasks because the exploratory noise required for reinforcement overwhelms the system.
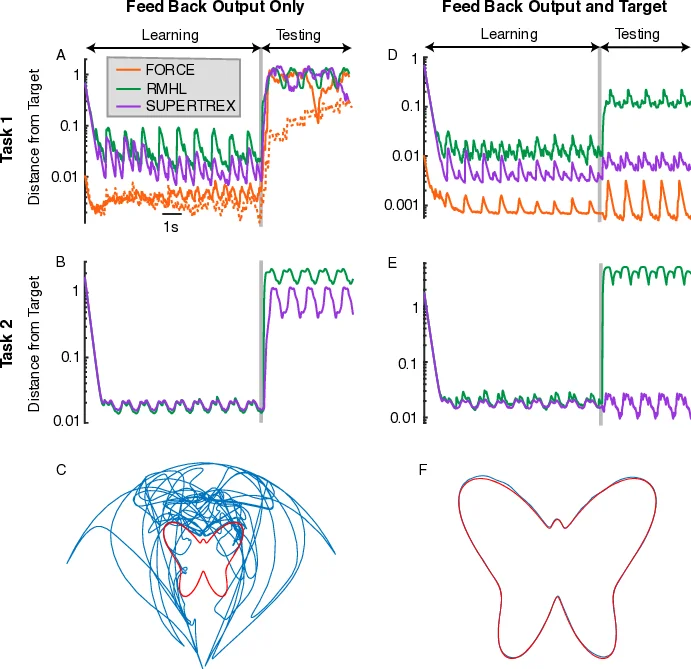
To resolve this, the authors propose a novel architecture called SUPER‑TREX (Supervised Learning Trained by Rewarded Exploration). The network retains a standard recurrent “reservoir” of rate‑model neurons, but it splits the readout into two parallel pathways: an “exploratory path” (z₁) and a “mastery path” (z₂). The exploratory path follows an RMHL‑like rule: it receives a one‑dimensional error (or negative reward) e(t), adds sub‑linear exploratory noise η(t) scaled by Ψ(e), and updates its weights W₁ using a high‑pass filtered error and output (τ₁ dW₁/dt = Φ(ĥe) ĥz rᵀ). This path quickly reduces the total error of the combined output z = z₁ + z₂ but does not need to converge to the exact target.
The mastery path, by contrast, uses a FORCE‑like recursive least‑squares (RLS) update (τ₂ dW₂/dt = (z – z₂) rᵀ P). Crucially, the error term for this update is not the external reward but the current output of the exploratory path (z – z₂ = z₁). Thus, the mastery pathway treats the exploratory output as a teacher signal, learning to reproduce the target while the exploratory pathway gradually diminishes to zero. This mirrors biological theories in which dopamine‑dependent basal ganglia plasticity drives early learning, while cortical circuits gradually take over as the behavior becomes automatized.
The authors also introduce a soft‑threshold mechanism that reduces the transfer of learning from the exploratory to the mastery pathway when the total error exceeds a preset bound, preventing destabilizing feedback during early exploration. Although the RLS matrix P is non‑local, they note that substituting the identity matrix yields a fully local learning rule at the cost of slower convergence.
Three experimental domains validate the model. First, a “butterfly” drawing task requires the network to control pen coordinates to trace a parametrized curve using only a scalar reward based on distance to the target path. SUPER‑TREX converges within ten repetitions, achieving sub‑0.02 mean error, whereas RMHL stalls at ~0.15 and FORCE cannot be applied. Second, a three‑joint robotic arm must reproduce a complex 3‑D trajectory. Again, SUPER‑TREX reaches >95 % fidelity after 30 trials, while RMHL remains around 70 % even after 200 trials. Third, a Parkinson’s disease simulation reduces the reward sensitivity of the exploratory pathway, reproducing empirical findings: early learning is severely impaired, yet previously learned mastery outputs remain relatively intact.
Overall, the paper makes three major contributions. (1) It provides a biologically plausible computational framework that captures the transition from basal‑ganglia‑driven exploration to cortical‑driven execution observed in motor learning. (2) It introduces a two‑stage learning algorithm that eliminates the need for an explicit teacher signal while preserving the rapid convergence properties of FORCE. (3) It demonstrates practical relevance for neuroprosthetics, rehabilitation robotics, and disease modeling, suggesting that future brain‑machine interfaces could exploit parallel reward‑modulated and supervised pathways for robust skill acquisition.
In summary, SUPER‑TREX unifies reinforcement‑driven exploration with supervised error‑driven refinement, offering a powerful and neuro‑biologically grounded solution to the longstanding supervised‑learning bottleneck in reservoir computing.
Comments & Academic Discussion
Loading comments...
Leave a Comment