Channel adversarial training for cross-channel text-independent speaker recognition
The conventional speaker recognition frameworks (e.g., the i-vector and CNN-based approach) have been successfully applied to various tasks when the channel of the enrolment dataset is similar to that of the test dataset. However, in real-world applications, mismatch always exists between these two datasets, which may severely deteriorate the recognition performance. Previously, a few channel compensation algorithms have been proposed, such as Linear Discriminant Analysis (LDA) and Probabilistic LDA. However, these methods always require the collections of different channels from a specific speaker, which is unrealistic to be satisfied in real scenarios. Inspired by domain adaptation, we propose a novel deep-learning based speaker recognition framework to learn the channel-invariant and speaker-discriminative speech representations via channel adversarial training. Specifically, we first employ a gradient reversal layer to remove variations across different channels. Then, the compressed information is projected into the same subspace by adversarial training. Experiments on test datasets with 54,133 speakers demonstrate that the proposed method is not only effective at alleviating the channel mismatch problem, but also outperforms state-of-the-art speaker recognition methods. Compared with the i-vector-based method and the CNN-based method, our proposed method achieves significant relative improvement of 44.7% and 22.6% respectively in terms of the Top1 recall.
💡 Research Summary
The paper addresses a fundamental obstacle in modern speaker‑recognition systems: performance degradation caused by channel mismatch between enrollment and test recordings. Traditional approaches such as i‑vector extraction followed by LDA/PLDA or recent CNN‑based embeddings assume that the enrollment and test data share the same acoustic channel, or they require multi‑channel recordings of the same speaker to learn channel compensation matrices. In real‑world deployments—call‑center authentication, voice assistants on heterogeneous devices—such assumptions are rarely satisfied. To overcome this limitation, the authors propose a deep‑learning framework called Channel Adversarial Training (CAT) that explicitly learns channel‑invariant yet speaker‑discriminative representations without needing multi‑channel data from individual speakers.
The architecture consists of three main components: (1) a feature encoder (implemented as a stack of 1‑D convolutional layers or a ResNet‑style backbone) that maps raw waveforms or log‑Mel spectra into a high‑dimensional embedding; (2) a speaker classifier that predicts speaker identity using a standard cross‑entropy loss; and (3) a channel classifier that predicts the recording channel. The channel classifier is preceded by a Gradient Reversal Layer (GRL). During back‑propagation, the GRL multiplies the gradient by a negative scalar, effectively turning the channel classification loss into an adversarial signal for the encoder. Consequently, the encoder is encouraged to produce embeddings that confuse the channel classifier (i.e., make channel prediction accuracy approach chance) while still enabling the speaker classifier to succeed. The total loss is a weighted sum L = L_speaker + λ·L_channel, where λ controls the trade‑off between speaker discrimination and channel invariance. The authors also apply L2 normalization and optional dimensionality reduction (e.g., a linear projection) to force all embeddings into a common subspace, facilitating downstream similarity measures such as cosine distance or PLDA scoring.
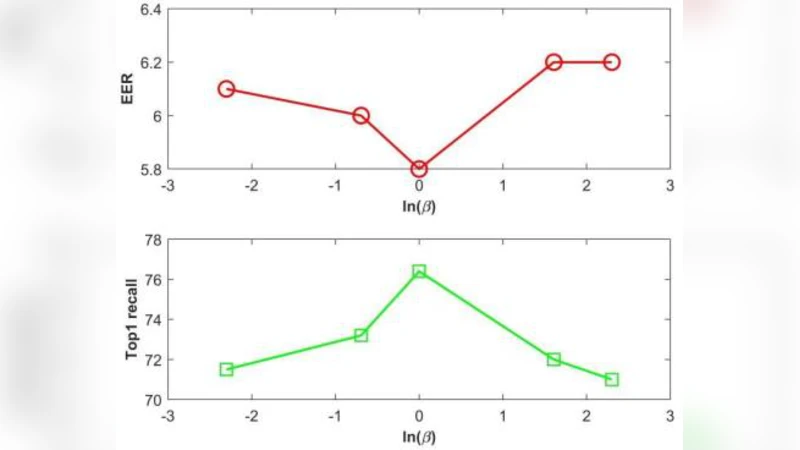
Experiments were conducted on a large-scale corpus comprising 54,133 speakers recorded across multiple devices (smartphones, headsets, telephone lines). The dataset was split into enrollment and test sets with deliberately mismatched channels to simulate realistic deployment conditions. Evaluation used Top‑1 recall (the proportion of test utterances whose highest‑scoring enrollment counterpart belongs to the same speaker). Baseline systems included (a) a conventional i‑vector + PLDA pipeline, and (b) a state‑of‑the‑art CNN‑based speaker embedding model trained without any channel adaptation. The CAT model achieved a relative improvement of 44.7 % over the i‑vector baseline and 22.6 % over the CNN baseline. Moreover, analysis of the channel classifier’s accuracy showed it hovered around 50 % (random guessing), confirming that the encoder successfully suppressed channel information. Ablation studies varying λ demonstrated that moderate values (≈0.1–0.5) yield the best balance; too high a λ harms speaker discrimination, while too low a λ leaves residual channel bias.
Key contributions of the work are: (1) introducing an adversarial training scheme that requires only channel labels (not speaker‑specific multi‑channel data) to achieve channel invariance; (2) demonstrating that such a scheme scales to tens of thousands of speakers and yields substantial gains in mismatched‑channel scenarios; (3) providing empirical evidence that GRL‑based adversarial learning can be effectively integrated into speaker‑recognition pipelines without sacrificing computational efficiency. The paper also discusses limitations: adversarial training can be unstable, especially when the number of channels is large or when channel characteristics differ dramatically (e.g., studio‑recorded speech vs. noisy far‑field recordings). The current setup assumes explicit channel annotations; extending the method to fully unsupervised channel discovery would require clustering or self‑supervised techniques. Future directions suggested include meta‑learning to adapt λ dynamically, multi‑task extensions that jointly learn speaker, language, and environment attributes, and combining CAT with self‑supervised pre‑training (e.g., wav2vec‑2.0) to further improve robustness.
In summary, the paper presents a practical and theoretically sound solution to the pervasive channel mismatch problem in text‑independent speaker recognition. By leveraging gradient reversal and adversarial objectives, the proposed system learns embeddings that are both highly discriminative of speaker identity and largely agnostic to recording conditions, achieving state‑of‑the‑art performance on a massive, real‑world dataset. This work paves the way for more resilient voice‑based authentication and personalization services across heterogeneous devices and acoustic environments.
Comments & Academic Discussion
Loading comments...
Leave a Comment