Audio-Linguistic Embeddings for Spoken Sentences
We propose spoken sentence embeddings which capture both acoustic and linguistic content. While existing works operate at the character, phoneme, or word level, our method learns long-term dependencies by modeling speech at the sentence level. Formul…
Authors: Albert Haque, Michelle Guo, Prateek Verma
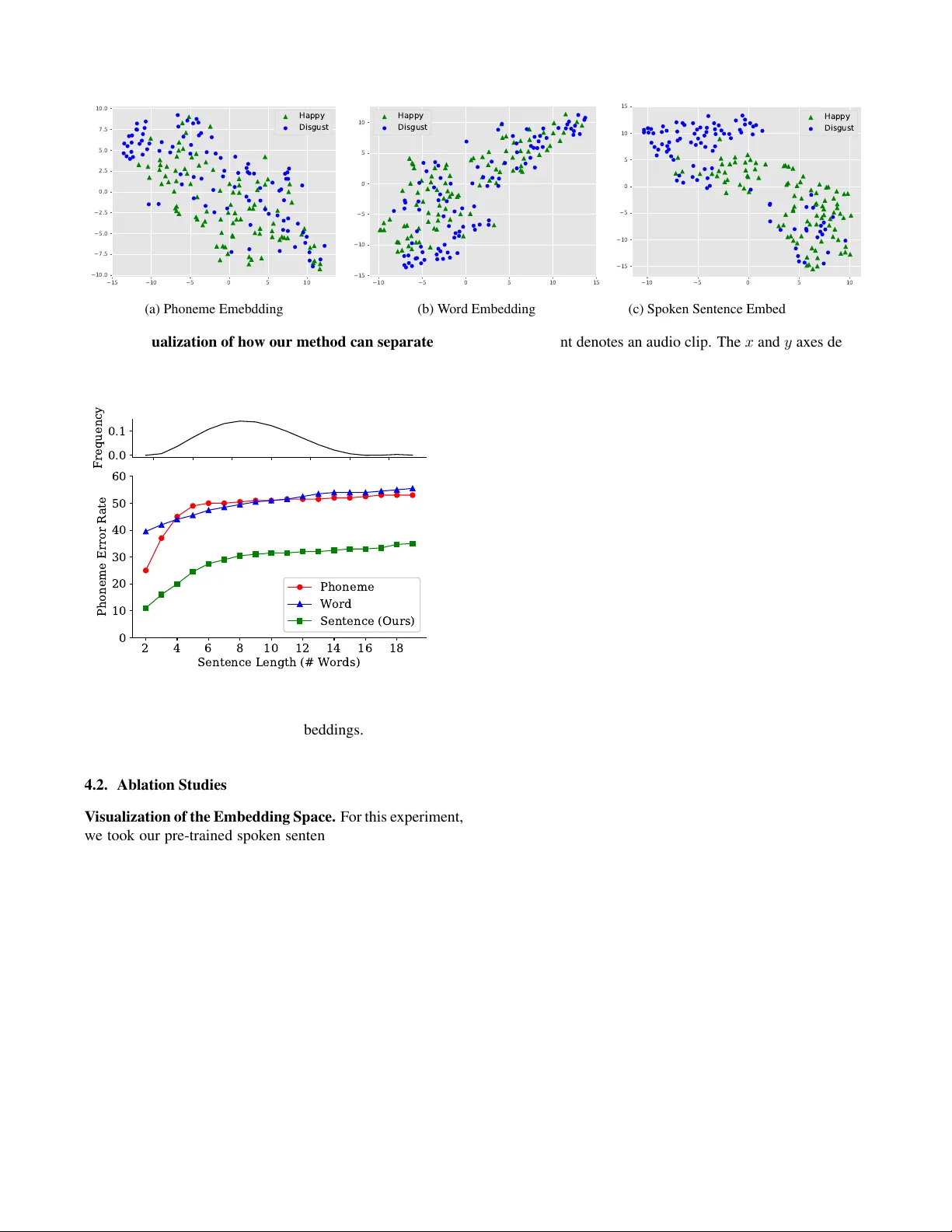
A UDIO-LINGUISTIC EMBEDDINGS FOR SPOKEN SENTENCES Albert Haque 1 Michelle Guo 1 Prateek V erma 2 Li F ei-F ei 1 1 Department of Computer Science, Stanford Uni versity 2 Center for Computer Research in Music and Acoustics, Stanford Uni versity ABSTRA CT W e propose spoken sentence embeddings which capture both acoustic and linguistic content. While existing works op- erate at the character , phoneme, or word lev el, our method learns long-term dependencies by modeling speech at the sen- tence le vel. F ormulated as an audio-linguistic multitask learn- ing problem, our encoder-decoder model simultaneously re- constructs acoustic and natural language features from audio. Our results show that spoken sentence embeddings outper- form phoneme and word-lev el baselines on speech recogni- tion and emotion recognition tasks. Ablation studies show that our embeddings can better model high-lev el acoustic con- cepts while retaining linguistic content. Overall, our work illustrates the viability of generic, multi-modal sentence em- beddings for spoken language understanding. 1. INTR ODUCTION During verbal communication, humans process multiple words sequentially , often waiting for a full sentence to be completed. Y et, many written and spoken language systems depend on individual character and word-le vel representa- tions either implicitly or explicitly . This lack of sentence- lev el context can make it difficult to understand sentences containing conjunctions [1], negations [2], and vocal pitch variations [3]. In this work, we in vestigate embeddings in the domain of spoken language processing and propose spoken sentence embeddings, capable of modeling both acoustic and linguistic content in a single latent code. Machine representation of words dates back to ASCII. This one-hot representation encodes each character using a mixture of dummy or indicator v ariables. While this was slowly extended to words, the lar ge v ocabulary size of lan- guages made it dif ficult. Learned, or distributed, word vector representations [4] replaced one-hot encodings. These word vectors are able to capture semantic information including context from neighboring words. Even today , the community continues to build better contextual word embeddings such as ELMo [5], ULMFit [6], and BER T [7]. W ord, phoneme, and grapheme embeddings like Speech2V ec [8] and Char2W av [9] hav e also been proposed for speceh, following techniques from natural language understanding. While word-le vel embeddings are promising, they are of- ten insufficient for speech-related tasks for se veral reasons. First, word and phoneme embeddings capture a narrow tem- poral context, often a few hundred milliseconds at most. As a result, these embeddings cannot capture long-term depen- dencies required for higher-le vel reasoning (e.g., paragraph or song-lev el understanding). Almost all of the systems for speech recognition focus on the correctness of local context (e.g., letters, words, and phonemes) rather than overall se- mantics. Second, for speech recognition, an external language model is often used to correct character and word-lev el pre- dictions. This requires the addition of complex, multiple hy- pothesis generation methods [10]. Sentence-lev el embeddings offer adv antages over word and character embeddings. A sentence-lev el embedding can capture latent factors across words. This is directly useful for higher-le vel audio tasks such as emotion recognition, prosody modeling, and musical style analysis. Furthermore, most ex- ternal language models operate at the sentence-lev el. By ha v- ing a single sentence-lev el embedding, the embedding can capture both acoustic and linguistic content at longer contex- tual window sizes – thus alle viating the need for an external language model entirely , by learning the temporal structure. Contributions. In this work, our contributions are tw o- fold. First, we propose moving from phoneme, character , and word-le vel representations to sentence-lev el understanding by learning spoken sentence embeddings. Second, we design this embedding to capture both linguistic and acoustic con- tent in order to learn latent codes which can be applicable to a variety of speech and language tasks. W e verify the quality of the embedding in our ablation studies, where we assess the generality of sentence-le vel embeddings when used for auto- matic speech recognition and emotion classification. W e be- liev e this work will inspire future work in speech processing, semantic understanding, and multi-modal transfer learning. 2. METHOD Our method allows us to learn spoken sentence embeddings that capture both acoustic and linguistic content. In this sec- tion, we discuss (i) how we handle long sequences with a tem- poral con volutional network [11] and (ii) how to learn audio- linguistic content under a multitask learning framew ork [12]. 2.1. T emporal Con volutional Network (TCN) Our goal is to learn a spoken sentence embedding, which can be used for a variety of speech tasks. Recurrent models are often the default starting point for sequence modeling tasks [11]. For most applications, the state-of-the-art approach to start with is very often a recurrent model. This is evide nt in machine translation [13, 14], automatic speech recognition [15, 16, 17], and speech synthesis tasks [18, 19, 9]. Howe ver , recurrent models such as recurrent neural net- works (RNNs) are notoriously difficult to train [20]. For years, machine learning researchers hav e tried to mak e RNNs easier to train through novel training strategies [21] and ar - chitectures [22]. In [11], the authors sho w that fully conv olu- tional networks can outperform recurrent netw orks, without the training complexities [11]. In addition, they can better capture long term dependencies [23] required for such tasks. Motiv ated by these findings, in this work, we opt for a fully con volutional sequence model (Figure 1). Similar to W aveNet [23], we use a temporal conv olutional network (TCN) [11]. While we use the TCN in this work, any causal model will suffice (e.g., T ransformer [24]). Causal Con volutions. T o begin, we introduce some quick notation. The sequence modeling task is defined as follows. Gi ven an input sequence x of length T , we have x = x 1 , ..., x T , where each x t is an observation for timestep t . Suppose we wish to make a prediction y t at each timestep, then we hav e y = y 1 , ..., y T . The causal constraint states that when predicting y t , it should depend only on past ob- servations x
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment