Utterance-level end-to-end language identification using attention-based CNN-BLSTM
In this paper, we present an end-to-end language identification framework, the attention-based Convolutional Neural Network-Bidirectional Long-short Term Memory (CNN-BLSTM). The model is performed on the utterance level, which means the utterance-level decision can be directly obtained from the output of the neural network. To handle speech utterances with entire arbitrary and potentially long duration, we combine CNN-BLSTM model with a self-attentive pooling layer together. The front-end CNN-BLSTM module plays a role as local pattern extractor for the variable-length inputs, and the following self-attentive pooling layer is built on top to get the fixed-dimensional utterance-level representation. We conducted experiments on NIST LRE07 closed-set task, and the results reveal that the proposed attention-based CNN-BLSTM model achieves comparable error reduction with other state-of-the-art utterance-level neural network approaches for all 3 seconds, 10 seconds, 30 seconds duration tasks.
💡 Research Summary
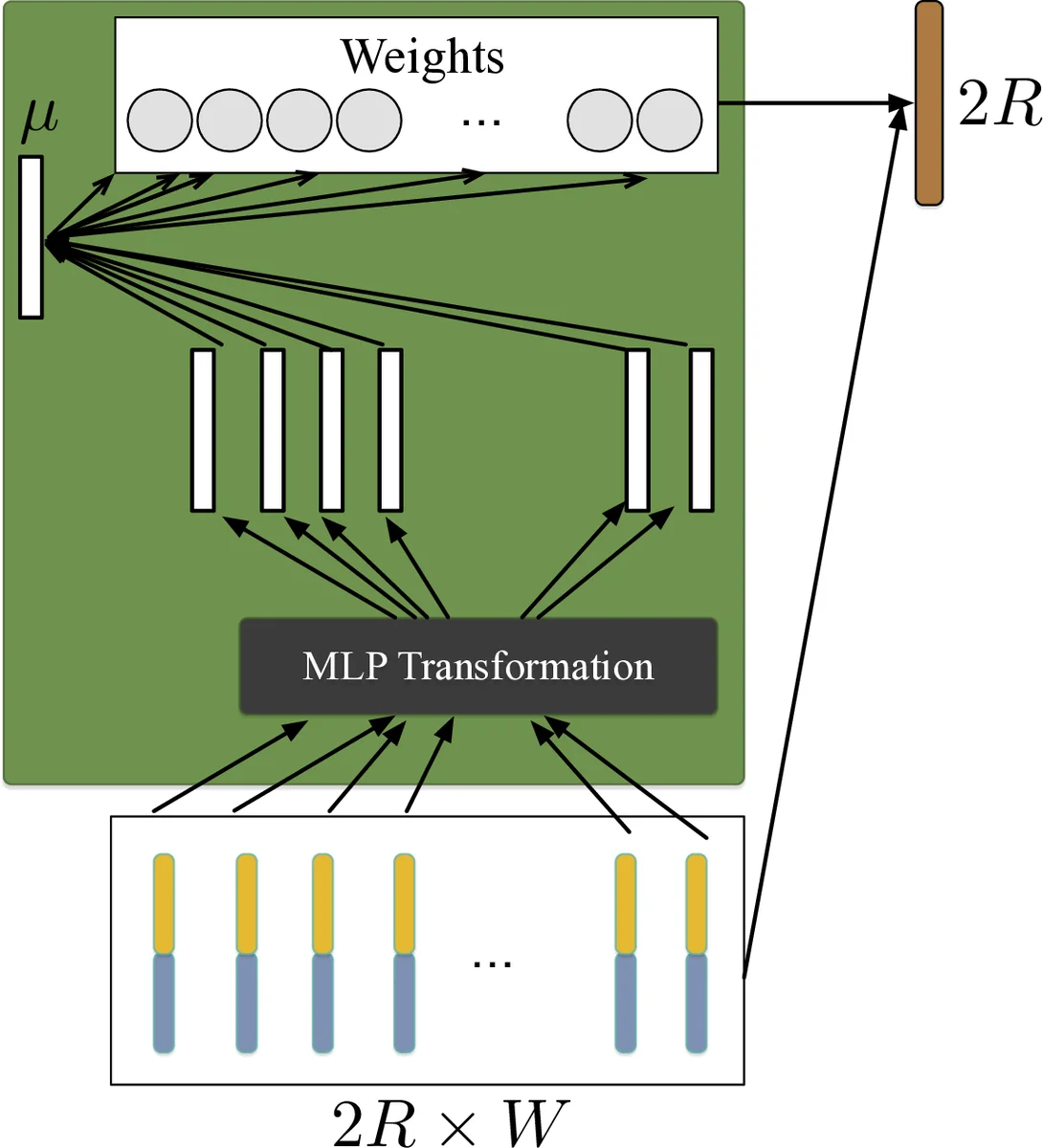
The paper introduces an end‑to‑end language identification (LID) system that operates directly at the utterance level, eliminating the need for separate frame‑level scoring or external pooling stages. The core architecture consists of a tandem Convolutional Neural Network (CNN) and a Bidirectional Long Short‑Term Memory (BLSTM) network followed by a Self‑Attentive Pooling (SAP) layer. Input speech is first transformed into 64‑dimensional log‑Mel filterbank features. A deep CNN based on ResNet‑34 extracts local time‑frequency patterns, producing a three‑dimensional tensor (channels × height × width). After pooling along the frequency axis, the tensor is reshaped to a two‑dimensional sequence (channels × time) and fed into a two‑layer BLSTM with 256 hidden units per direction. The BLSTM yields a variable‑length sequence of 2R‑dimensional vectors (R = 128), preserving both past and future contextual information for each time step.
To convert this variable‑length sequence into a fixed‑dimensional utterance representation, the authors employ a self‑attention mechanism. Each BLSTM output vector xₜ is passed through a single‑layer MLP with tanh activation to obtain hₜ. A learnable context vector μ is then used to compute attention scores αₜ = softmax(hₜ·μ). The final utterance embedding e is the weighted sum Σₜ αₜ xₜ. This attention pooling emphasizes frames that are most informative for language discrimination, such as the first backward and last forward BLSTM steps, and mitigates the “curse of sentence length” that can affect simple averaging.
Training uses stochastic gradient descent with momentum 0.9, weight decay 1e‑4, and a learning‑rate schedule (0.1 → 0.01 → 0.001). Crucially, each mini‑batch is constructed with a randomly chosen frame length L in the range 200–1000, and all utterances in the batch are either cropped or padded to this length. This dynamic batching forces the model to handle a wide range of utterance durations during training. No separate validation set is used; the final model after the last learning‑rate decay is evaluated directly.
Experiments were conducted on the NIST LRE07 closed‑set task, which includes 14 target languages and test utterances of 3 s, 10 s, and 30 s durations. Baseline systems include CNN‑TAP (CNN with temporal average pooling), CNN‑SAP (CNN with self‑attentive pooling), CNN‑LSTM, and CNN‑GRU. Results show that replacing TAP with SAP consistently improves performance (e.g., CNN‑SAP C_avg = 8.59 % vs. CNN‑TAP = 9.98 % for 3 s). Adding a BLSTM without attention (CNN‑BLSTM‑TAP) slightly degrades performance, confirming that simple averaging is insufficient for the richer BLSTM outputs. However, the proposed CNN‑BLSTM‑SAP achieves the best results across all durations (C_avg = 9.22 % for 3 s, 2.54 % for 10 s, 0.97 % for 30 s), outperforming both CNN‑based and recurrent‑only baselines. Score‑level fusion of the CNN‑SAP and CNN‑BLSTM‑SAP systems further reduces error (e.g., C_avg = 7.98 % for 3 s).
The study’s contributions are threefold: (1) integrating a CNN‑BLSTM front‑end to capture both local spectral patterns and bidirectional temporal context; (2) applying self‑attention pooling to convert variable‑length BLSTM outputs into discriminative fixed‑dimensional utterance embeddings; and (3) employing a dynamic mini‑batch strategy that promotes robustness to arbitrary utterance lengths. The authors suggest future work could explore multi‑head attention, deeper recurrent stacks, or Transformer‑style encoders to further boost LID performance.
Comments & Academic Discussion
Loading comments...
Leave a Comment