Multitask learning for frame-level instrument recognition
For many music analysis problems, we need to know the presence of instruments for each time frame in a multi-instrument musical piece. However, such a frame-level instrument recognition task remains difficult, mainly due to the lack of labeled datasets. To address this issue, we present in this paper a large-scale dataset that contains synthetic polyphonic music with frame-level pitch and instrument labels. Moreover, we propose a simple yet novel network architecture to jointly predict the pitch and instrument for each frame. With this multitask learning method, the pitch information can be leveraged to predict the instruments, and also the other way around. And, by using the so-called pianoroll representation of music as the main target output of the model, our model also predicts the instruments that play each individual note event. We validate the effectiveness of the proposed method for framelevel instrument recognition by comparing it with its singletask ablated versions and three state-of-the-art methods. We also demonstrate the result of the proposed method for multipitch streaming with real-world music. For reproducibility, we will share the code to crawl the data and to implement the proposed model at: https://github.com/biboamy/ instrument-streaming.
💡 Research Summary
The paper tackles the challenging problem of frame‑level instrument recognition, which requires knowing which instruments are active at each short time step of a polyphonic piece. Existing datasets either provide only clip‑level instrument tags or contain only a few hundred songs with frame‑level annotations, limiting the training of deep models. To overcome this bottleneck, the authors introduce a large synthetic dataset called MuseScore, comprising 344,166 audio‑MIDI pairs scraped from the MuseScore community website. Each piece is about two minutes long, spans a wide variety of genres, and includes 128 instrument classes defined by the MIDI specification. Because the audio is generated from the MIDI files, precise temporal alignment is achievable; the authors further refine alignment using a dynamic time‑warping algorithm. From the MIDI files they derive three ground‑truth tensors: a multi‑track pianoroll (frequency × time × instrument), a pitch roll (frequency × time), and an instrument roll (instrument × time).
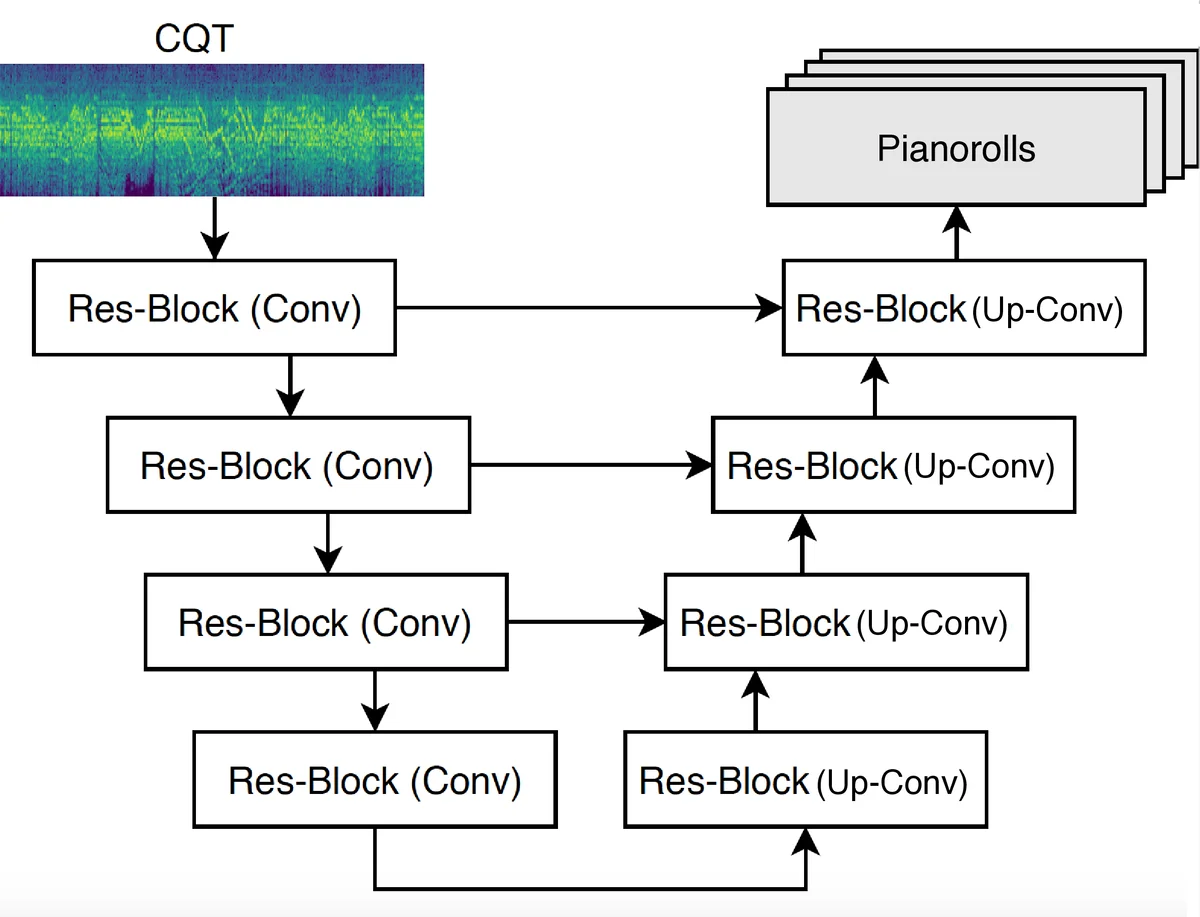
The core methodological contribution is a multitask learning framework that jointly predicts these three targets from a single audio representation. The input is a constant‑Q transform (CQT) spectrogram (88 bins, 16 kHz sampling, 512‑sample hop). The network follows a U‑Net architecture with four residual encoder blocks and four residual decoder blocks, each block containing three convolution‑batch‑norm‑LeakyReLU layers and skip connections that preserve fine‑grained time‑frequency details. The model outputs a binary pianoroll tensor; the pitch roll and instrument roll are obtained by summing the pianoroll along the instrument and frequency dimensions, respectively. Three binary cross‑entropy losses (L_roll, L_pitch, L_inst) are computed, re‑scaled to comparable ranges, and summed to form the total loss. This design forces the shared encoder‑decoder to learn representations that capture the strong interdependence between pitch and timbre: pitch ranges constrain possible instruments, and instrument-specific articulation patterns aid pitch detection.
Training uses stochastic gradient descent with a learning rate of 0.005, processing 10‑second CQT segments as mini‑batches.
Experiments are conducted in two phases. First, an ablation study on the MuseScore dataset selects the nine most frequent instruments (piano, acoustic/electric guitar, trumpet, saxophone, violin, cello, flute, etc.). Four models are compared: the full multitask model and three single‑task variants that train only on L_roll, L_pitch, or L_inst. The multitask model achieves an instrument F1‑score of 0.947, far surpassing the L_roll‑only baseline (0.623). Pitch accuracy and pianoroll accuracy also improve markedly, confirming that joint learning yields synergistic benefits.
Second, the proposed system is benchmarked against three recent state‑of‑the‑art frame‑level instrument recognizers: Gururani et al. (2019)
Comments & Academic Discussion
Loading comments...
Leave a Comment