Federated Learning for Keyword Spotting
We propose a practical approach based on federated learning to solve out-of-domain issues with continuously running embedded speech-based models such as wake word detectors. We conduct an extensive empirical study of the federated averaging algorithm for the “Hey Snips” wake word based on a crowdsourced dataset that mimics a federation of wake word users. We empirically demonstrate that using an adaptive averaging strategy inspired from Adam in place of standard weighted model averaging highly reduces the number of communication rounds required to reach our target performance. The associated upstream communication costs per user are estimated at 8 MB, which is a reasonable in the context of smart home voice assistants. Additionally, the dataset used for these experiments is being open sourced with the aim of fostering further transparent research in the application of federated learning to speech data.
💡 Research Summary
This paper investigates the application of federated learning (FL) to the training of a wake‑word detector for smart‑home voice assistants, focusing on the “Hey Snips” keyword. Wake‑word detection must run continuously on resource‑constrained devices (≈200 k parameters, ≤20 MFLOPS) while achieving high recall and low false‑alarm rates. Centralized collection of user speech raises privacy concerns, motivating a decentralized training approach where raw audio never leaves the user’s device.
The authors first construct a crowdsourced dataset that emulates a realistic federation of wake‑word users. Over 1,800 contributors recorded the target phrase and a variety of negative utterances on their own devices, yielding 69 k utterances (≈18 % positive) with strong per‑user imbalance (mean 39 utterances, σ = 32). The data are split by user into training (77 %), development (10 %), and test (13 %) sets, ensuring a non‑IID, highly unbalanced distribution.
The model architecture is a lightweight convolutional neural network designed for on‑device inference: five dilated convolutional layers followed by two fully‑connected layers and a softmax, totaling 190 852 parameters. Input features are 40‑dimensional MFCCs stacked over 32 frames (25 ms windows, 10 ms stride). The network predicts four frame‑wise labels (“Hey”, “sni”, “ps”, “filler”), and a posterior‑based confidence score is used to trigger the wake word when it exceeds a threshold calibrated to 5 false alarms per hour (FAH) on the development set.
Training follows the standard FedAvg protocol: at each communication round a random subset of clients (participation ratio C) receives the current global model, performs local SGD updates for E epochs with batch size B, and returns the updated weights. The server aggregates updates using a weighted average proportional to each client’s data size. The novelty lies in replacing the simple weighted average with an adaptive per‑coordinate update inspired by the Adam optimizer. Specifically, the server computes the model difference Gₜ = ∑ₖ (nₖ/nᵣ)(wₜ₋₁ − wₜ,ₖ) and updates first‑ and second‑moment estimates with β₁ = 0.9, β₂ = 0.999, ε = 10⁻⁸, applying a global learning rate η₍global₎ = 0.001. This “Adam‑global averaging” smooths the aggregated gradient across rounds and adapts learning rates per parameter, mitigating the divergence caused by heterogeneous, non‑IID client data.
Extensive experiments explore the impact of client participation (C), local epochs (E), batch size (B), and averaging strategy. Key findings include:
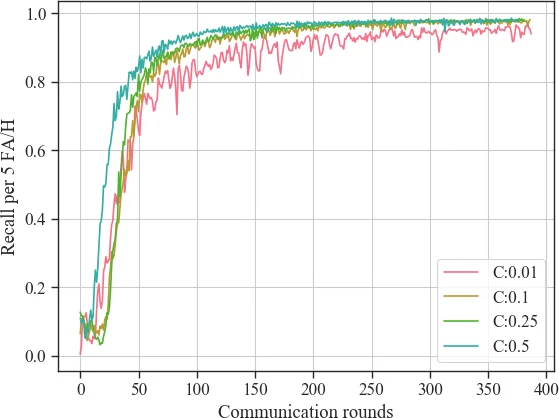
- Client participation: C = 10 % offers a practical trade‑off between convergence speed and realistic device availability. Lower C (1 %) leads to noisy gradients; higher C (≥50 %) yields diminishing returns.
- Averaging strategy: Standard FedAvg (η₍global₎ = 1) fails to reach the target even after 400 rounds, while Adam‑global averaging achieves >98 % recall within 100 rounds. The adaptive per‑parameter scaling is crucial for handling the semantic variability of user‑specific pronunciations.
- Local training: Increasing local epochs or batch size provides modest gains. The best configuration (E = 1, B = 20) results in an average of 2.4 local updates per participating client per round, delivering an 80 % speed‑up over FedSGD (E = 1, B = ∞). Excessive local computation does not dramatically accelerate convergence, likely because each user’s acoustic characteristics differ substantially.
- Communication cost: Assuming 32‑bit floating‑point transmission, each client uploads ≈8 MB over 100 rounds (C = 0.1). The server receives ~137 model uploads per round, totaling ~110 GB for the entire training run with 1.4 k clients. Extending to 400 rounds raises per‑client upload to ~32 MB while achieving 98 % recall and 0.5 FAH.
Evaluation on the held‑out test set confirms that the federated model matches or exceeds centralized baselines. At a fixed 95 % recall, false‑alarm rates are 3.2 FAH on test negatives, 3.9 FAH on Librispeech, and 0.2–0.6 FAH on internal news and TV recordings, demonstrating robustness across diverse acoustic environments.
In conclusion, the paper demonstrates that federated learning, when equipped with an Adam‑style adaptive global averaging, can efficiently train a resource‑constrained wake‑word detector on highly heterogeneous, privacy‑sensitive speech data. The approach achieves target performance within a modest communication budget, making it viable for real‑world deployment. Future work will address on‑device early‑stopping, client selection policies, and further communication reductions via model compression or quantization.
Comments & Academic Discussion
Loading comments...
Leave a Comment