Learning latent representations for style control and transfer in end-to-end speech synthesis
In this paper, we introduce the Variational Autoencoder (VAE) to an end-to-end speech synthesis model, to learn the latent representation of speaking styles in an unsupervised manner. The style representation learned through VAE shows good properties such as disentangling, scaling, and combination, which makes it easy for style control. Style transfer can be achieved in this framework by first inferring style representation through the recognition network of VAE, then feeding it into TTS network to guide the style in synthesizing speech. To avoid Kullback-Leibler (KL) divergence collapse in training, several techniques are adopted. Finally, the proposed model shows good performance of style control and outperforms Global Style Token (GST) model in ABX preference tests on style transfer.
💡 Research Summary
The paper introduces a Variational Autoencoder (VAE) into a state‑of‑the‑art end‑to‑end text‑to‑speech (TTS) system (Tacotron2) to learn a continuous latent representation of speaking style in an unsupervised manner. The authors argue that while modern TTS models can generate near‑human quality neutral speech, expressive synthesis—controlling prosody, emotion, and style—remains a challenging and active research area. Existing approaches such as Global Style Tokens (GST) provide discrete style tokens but lack a smooth latent space and flexible style transfer capabilities.
The VAE component models a latent variable z that captures style information. A reference encoder processes an auxiliary audio sample, consisting of six 2‑D convolutional layers followed by a GRU, and outputs an embedding that is fed through two fully‑connected layers to produce the mean (μ) and variance (σ²) of a Gaussian posterior qφ(z|x). Using the re‑parameterization trick, a sample z is drawn and concatenated (after a linear projection) with the text encoder output of Tacotron2. The combined representation is then processed by the usual location‑sensitive attention and decoder to predict mel‑spectrograms, which are finally rendered into waveforms by a WaveNet vocoder.
Training optimizes a loss comprising three terms: (1) the KL divergence between the posterior qφ(z|x) and the isotropic Gaussian prior pθ(z), (2) an L2 reconstruction loss on mel‑spectrograms conditioned on both z and the input text, and (3) a stop‑token loss. A well‑known issue in VAE training—KL collapse, where the KL term quickly goes to zero and the encoder stops learning useful representations—is addressed by two tricks: (a) KL annealing, where the weight of the KL term starts near zero and is gradually increased, and (b) applying the KL loss only every K training steps. These measures keep the KL term non‑trivial throughout training, encouraging the encoder to encode meaningful style information.
Experiments use a 105‑hour single‑speaker audiobook dataset (Blizzard Challenge 2013) containing 58 k training utterances and 200 test utterances. The baseline is a GST‑based Tacotron2 model trained under the same conditions. The VAE latent space is set to 32 dimensions; the KL‑annealing schedule switches the step interval K from 100 to 400 after 15 k steps.
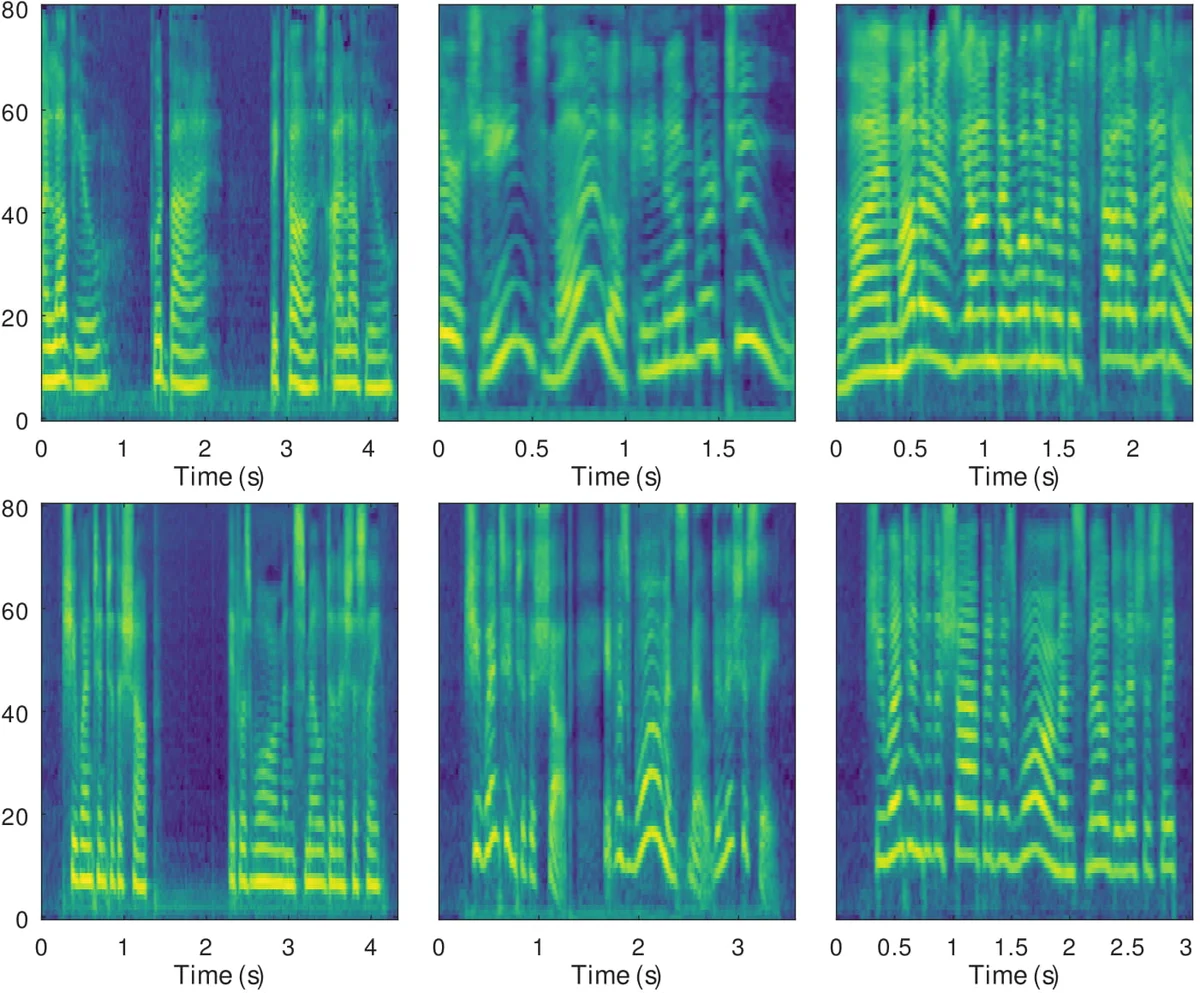
Style control experiments demonstrate that individual dimensions of z can be manipulated to affect specific acoustic attributes. For example, dimension 6 controls overall pitch height, while dimension 10 modulates local pitch variation. Adjusting these dimensions independently changes only the targeted attribute, confirming disentanglement. Moreover, linear interpolation between two style vectors (high‑pitch/high‑rate vs low‑pitch/low‑rate) yields smooth transitions in both pitch and speaking rate, illustrating the continuity of the latent space.
Style transfer is performed by feeding a reference audio through the recognition network to obtain z, then synthesizing speech for a (potentially different) target text. Spectrograms of the synthesized speech closely match the reference in pitch contour, pause distribution, and speaking rate. Subjective ABX preference tests were conducted for both parallel transfer (same text as reference) and non‑parallel transfer (different text). In each condition, 60 samples were evaluated by 25 native English listeners, resulting in a statistically significant preference for the VAE‑based model over the GST baseline (p < 10⁻⁵). The advantage is especially pronounced in the non‑parallel scenario, indicating better generalization of the learned style representation.
The authors conclude that integrating a VAE into an end‑to‑end TTS framework yields a continuous, interpretable style latent space that enables fine‑grained control, smooth interpolation, and effective style transfer. Future work includes improving disentanglement, extending the approach to multi‑speaker settings, and leveraging the latent space for data augmentation.
Comments & Academic Discussion
Loading comments...
Leave a Comment