Digital Neuron: A Hardware Inference Accelerator for Convolutional Deep Neural Networks
We propose a Digital Neuron, a hardware inference accelerator for convolutional deep neural networks with integer inputs and integer weights for embedded systems. The main idea to reduce circuit area and power consumption is manipulating dot products between input feature and weight vectors by Barrel shifters and parallel adders. The reduced area allows the more computational engines to be mounted on an inference accelerator, resulting in high throughput compared to prior HW accelerators. We verified that the multiplication of integer numbers with 3-partial sub-integers does not cause significant loss of inference accuracy compared to 32-bit floating point calculation. The proposed digital neuron can perform 800 MAC operations in one clock for computation for convolution as well as full-connection. This paper provides a scheme that reuses input, weight, and output of all layers to reduce DRAM access. In addition, this paper proposes a configurable architecture that can provide inference of adaptable feature of convolutional neural networks. The throughput in terms of Watt of the digital neuron is achieved 754.7 GMACs/W.
💡 Research Summary
The paper introduces “Digital Neuron,” a hardware inference accelerator designed specifically for embedded systems that need to run convolutional deep neural networks (CNNs) with minimal power consumption and high throughput. The core innovation lies in replacing conventional multipliers with a combination of barrel shifters and parallel adders, achieved by decomposing each 8‑bit weight into two or three “partial sub‑integers.” This decomposition allows multiplication to be performed using only shift‑and‑add operations, dramatically reducing circuit area and static power while preserving numerical fidelity.
Quantization experiments on LeNet‑5 with the MNIST dataset show that 8‑bit integer weights incur no loss in accuracy (99.10 %), and even 5‑bit weights with the proposed 2‑partial‑sub‑integer scheme lose only 0.18 % (99.10 % → 98.92 %). The maximum error introduced by the 3‑partial‑sub‑integer representation is about 2 %, which the authors demonstrate does not materially affect inference results.
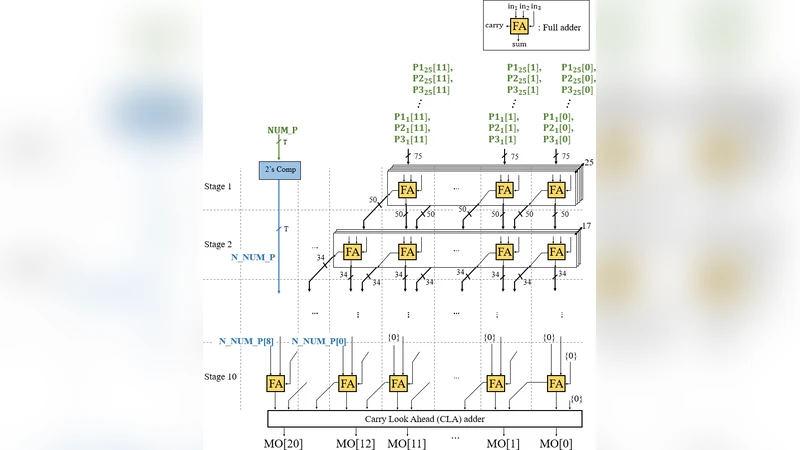
The computational engine consists of two main blocks: (1) Multiplication by Barrel Shift (MBS) and (2) Multi‑Operand Adder (MOA). Each MBS block receives an 8‑bit weight and generates three partial products (P1, P2, P3) via three barrel shifters controlled by a set of select signals (a, b, c, etc.). The MOA aggregates the 3N partial products from N parallel MBS units using a Wallace‑tree‑style adder network, effectively performing a high‑speed reduction of many operands while expanding bit‑width gradually. Sign handling is simplified by using a two’s‑complement subtraction of negative partials rather than full sign‑extension, saving roughly 21 % of additional area.
At the system level, the accelerator is organized into four “Neural Tiles” (NTs), each containing an 8 × 5 × 5 array of neural elements. The four NTs together can compute a full 3‑D convolution or a fully‑connected (FC) layer in a single clock cycle, achieving 800 MAC operations per cycle. Weights are loaded once from DRAM into dedicated w‑bank registers and reused across all layers, while input feature maps are streamed through an X‑bus that slides a convolution window across the input tensor. This data‑reuse strategy dramatically cuts DRAM traffic, which the authors note consumes 200× more power than on‑chip register accesses.
A notable contribution is the configurable filter‑size scheme. By rearranging how NTs and downstream carry‑look‑ahead (CLA) adders are connected, the accelerator can support various kernel dimensions (e.g., 3 × 3, 5 × 5, 7 × 7) without hardware redesign. The paper illustrates three cases where the filter is partitioned among the NTs in different ways, demonstrating flexibility for diverse CNN architectures.
Performance results indicate a throughput of 754.7 GMAC/W, far surpassing prior shift‑based designs such as UNPU and BIT‑FUSION. The authors also report a 42 % reduction in critical path delay and a 36 % reduction in total gate count for the MOA compared to a conventional binary‑adder tree handling the same number of inputs.
In summary, Digital Neuron achieves ultra‑low power, high‑throughput CNN inference by (1) quantizing weights into a small number of shift‑friendly sub‑integers, (2) employing a massively parallel, barrel‑shift‑based MAC engine, (3) minimizing DRAM accesses through aggressive on‑chip data reuse, and (4) providing a configurable architecture that can adapt to various convolution kernel sizes. The work demonstrates that careful arithmetic approximation combined with architectural optimizations can deliver state‑of‑the‑art efficiency for embedded AI applications without sacrificing model accuracy.
Comments & Academic Discussion
Loading comments...
Leave a Comment