Study and Observation of the Variations of Accuracies for Handwritten Digits Recognition with Various Hidden Layers and Epochs using Convolutional Neural Network
Nowadays, deep learning can be employed to a wide ranges of fields including medicine, engineering, etc. In deep learning, Convolutional Neural Network (CNN) is extensively used in the pattern and sequence recognition, video analysis, natural language processing, spam detection, topic categorization, regression analysis, speech recognition, image classification, object detection, segmentation, face recognition, robotics, and control. The benefits associated with its near human level accuracies in large applications lead to the growing acceptance of CNN in recent years. The primary contribution of this paper is to analyze the impact of the pattern of the hidden layers of a CNN over the overall performance of the network. To demonstrate this influence, we applied neural network with different layers on the Modified National Institute of Standards and Technology (MNIST) dataset. Also, is to observe the variations of accuracies of the network for various numbers of hidden layers and epochs and to make comparison and contrast among them. The system is trained utilizing stochastic gradient and backpropagation algorithm and tested with feedforward algorithm.
💡 Research Summary
The paper investigates how the architecture of a convolutional neural network (CNN)—specifically the number of hidden layers and the number of training epochs—affects its ability to recognize handwritten digits from the MNIST dataset. The authors construct a baseline seven‑layer CNN (one input layer, two convolution‑pooling pairs, one fully‑connected layer, and one output layer) and then vary two dimensions: (1) depth of the hidden layers, by testing three configurations (a shallow 3‑layer model with a single conv‑pool pair, the baseline 5‑layer model with two conv‑pool pairs, and a deeper 7‑layer model that adds an extra conv‑pool pair), and (2) the number of training epochs (5, 10, 20, and 40). All models use ReLU activations after each convolution and the fully‑connected layer, max‑pooling with 2×2 kernels and stride 2, dropout (0.5) on the fully‑connected layer, and a Softmax output. Training is performed with stochastic gradient descent (learning rate 0.01, batch size 64) and back‑propagation; loss is the standard cross‑entropy.
Key findings include:
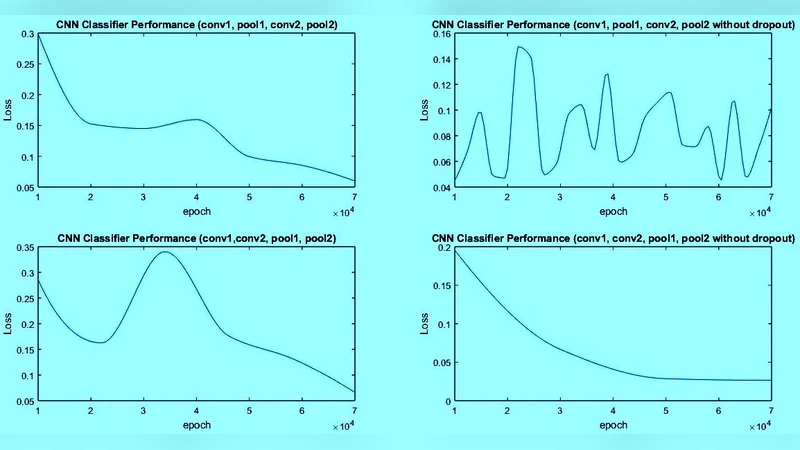
- Depth vs. Accuracy – The baseline 5‑layer network achieves the highest test accuracy (~98.7%). The shallow 3‑layer network reaches ~96.2%, indicating that a single conv‑pool pair is insufficient for optimal feature extraction on MNIST. The deeper 7‑layer network, while achieving lower training loss, suffers from higher validation loss and a modest drop in test accuracy (~97.9%), evidencing over‑fitting despite dropout.
- Epochs vs. Convergence – Accuracy improves sharply between 5 and 10 epochs but plateaus after 20 epochs. Extending training to 40 epochs yields only marginal gains (<0.2%) while validation loss rises, confirming that excessive epochs can degrade generalization. The authors suggest 20–30 epochs as a practical sweet spot for MNIST‑scale tasks.
- Regularization – Dropout on the fully‑connected layer mitigates over‑fitting to some extent, but deeper models still benefit from additional regularization (e.g., batch normalization) to stabilize training.
- Implementation & Reproducibility – The network is implemented in Python using TensorFlow 2.x and NumPy, with all hyper‑parameters and code made publicly available, facilitating replication and extension by the research community.
The discussion emphasizes that more layers do not automatically translate to better performance; instead, an optimal balance between model capacity and dataset complexity is crucial. For relatively simple image classification problems like MNIST, a moderate depth (5–6 layers) combined with a moderate number of epochs (20–30) yields the best trade‑off between accuracy, training time, and generalization. The paper also highlights the importance of early‑stopping or validation‑based epoch selection to avoid over‑training.
In conclusion, the study provides empirical evidence that careful tuning of hidden‑layer architecture and epoch count is essential for achieving near‑human accuracy in handwritten digit recognition. The results serve as practical guidelines for engineers and researchers designing CNNs for similar tasks, underscoring that excessive depth and prolonged training are not universally beneficial and may even harm performance.
Comments & Academic Discussion
Loading comments...
Leave a Comment