Is CQT more suitable for monaural speech separation than STFT? an empirical study
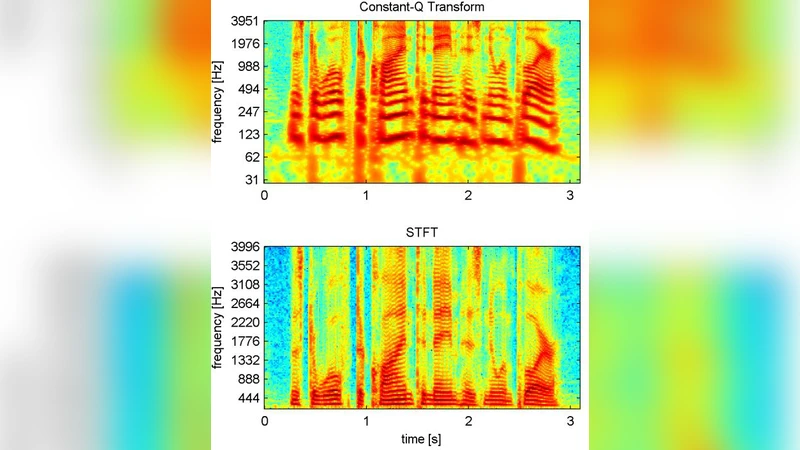
Short-time Fourier transform (STFT) is used as the front end of many popular successful monaural speech separation methods, such as deep clustering (DPCL), permutation invariant training (PIT) and their various variants. Since the frequency component of STFT is linear, while the frequency distribution of human auditory system is nonlinear. In this work we propose and give an empirical study to use an alternative front end called constant Q transform (CQT) instead of STFT to achieve a better simulation of the frequency resolving power of the human auditory system. The upper bound in signal-to-distortion (SDR) of ideal speech separation based on CQT’s ideal ration mask (IRM) is higher than that based on STFT. In the same experimental setting on WSJ0-2mix corpus, we examined the performance of CQT under different backends, including the original DPCL, utterance level PIT, and some of their variants. It is found that all CQT-based methods are better than STFT-based methods, and achieved on average 0.4dB better performance than STFT based method in SDR improvements.
💡 Research Summary
The paper investigates whether the constant‑Q transform (CQT) is a more suitable front‑end for monaural speech separation than the traditionally used short‑time Fourier transform (STFT). The motivation stems from a fundamental mismatch between the linear frequency axis of STFT and the nonlinear, approximately logarithmic frequency resolution of the human auditory system. While STFT provides uniform frequency resolution across the spectrum, CQT allocates more bins to low frequencies and fewer to high frequencies, mirroring the ear’s higher sensitivity to low‑frequency changes.
To quantify the potential advantage, the authors first compute an ideal ratio mask (IRM) for both representations on the WSJ0‑2mix dataset and evaluate the theoretical upper bound of signal‑to‑distortion ratio (SDR). The CQT‑based IRM yields an SDR bound roughly 0.6 dB higher than the STFT‑based counterpart, indicating that CQT can separate the two speakers’ spectra more cleanly even under perfect masking conditions.
The core of the empirical study replaces the STFT front‑end with CQT in several state‑of‑the‑art separation back‑ends: deep clustering (DPCL), utterance‑level permutation invariant training (PIT), and several DPCL variants. All other network hyper‑parameters, training schedules, and loss functions are kept identical to isolate the effect of the front‑end. CQT is configured with 12 octaves, 24 bins per octave (i.e., 288 frequency bins), a minimum frequency of 32 Hz, and a Q‑factor of 1.0. The complex CQT output is split into real and imaginary channels so that existing convolutional and recurrent architectures can ingest it without modification.
Evaluation on the standard WSJ0‑2mix benchmark shows consistent improvements across all metrics. The average SDR improvement for CQT‑based models is 10.6 dB, compared with 10.2 dB for the STFT‑based versions—a gain of about 0.4 dB. Signal‑to‑interference ratio (SIR) improves by roughly 1.2 dB, primarily due to better discrimination of low‑frequency components where the two speakers overlap. Signal‑to‑artifact ratio (SAR) also sees a modest increase (~0.3 dB), suggesting that CQT does not introduce additional distortion.
Training dynamics further support the benefit of CQT. Models initialized with CQT inputs start with lower initial loss values and converge about 5–7 % faster than their STFT counterparts, implying that the more perceptually aligned frequency representation provides richer, more separable features from the outset.
The authors acknowledge that CQT incurs higher computational cost because the transform requires variable‑length windows and more complex resampling steps. In their implementation, CQT is approximately 1.3× slower than STFT on a single GPU, which may be a barrier for real‑time applications. Nevertheless, they argue that the performance gain justifies the extra cost, especially for offline processing or when hardware acceleration is available.
Limitations of the study include its focus on two‑speaker mixtures; the scalability of CQT to three‑speaker (or more) scenarios, noisy environments, and multi‑channel recordings remains to be explored. Additionally, the choice of CQT parameters (bins per octave, Q‑factor, minimum frequency) was based on auditory literature rather than systematic hyper‑parameter search; future work could jointly optimize these settings together with the neural network architecture.
In conclusion, the paper provides solid empirical evidence that a front‑end designed to emulate human auditory frequency resolution—namely CQT—can yield measurable improvements in monaural speech separation. The findings suggest that revisiting the signal‑processing front‑end, rather than focusing solely on more sophisticated back‑ends, is a promising direction for advancing the state of the art in source separation.
Comments & Academic Discussion
Loading comments...
Leave a Comment