Applications of Multi-view Learning Approaches for Software Comprehension
Program comprehension concerns the ability of an individual to make an understanding of an existing software system to extend or transform it. Software systems comprise of data that are noisy and missing, which makes program understanding even more difficult. A software system consists of various views including the module dependency graph, execution logs, evolutionary information and the vocabulary used in the source code, that collectively defines the software system. Each of these views contain unique and complementary information; together which can more accurately describe the data. In this paper, we investigate various techniques for combining different sources of information to improve the performance of a program comprehension task. We employ state-of-the-art techniques from learning to 1) find a suitable similarity function for each view, and 2) compare different multi-view learning techniques to decompose a software system into high-level units and give component-level recommendations for refactoring of the system, as well as cross-view source code search. The experiments conducted on 10 relatively large Java software systems show that by fusing knowledge from different views, we can guarantee a lower bound on the quality of the modularization and even improve upon it. We proceed by integrating different sources of information to give a set of high-level recommendations as to how to refactor the software system. Furthermore, we demonstrate how learning a joint subspace allows for performing cross-modal retrieval across views, yielding results that are more aligned with what the user intends by the query. The multi-view approaches outlined in this paper can be employed for addressing problems in software engineering that can be encoded in terms of a learning problem, such as software bug prediction and feature location.
💡 Research Summary
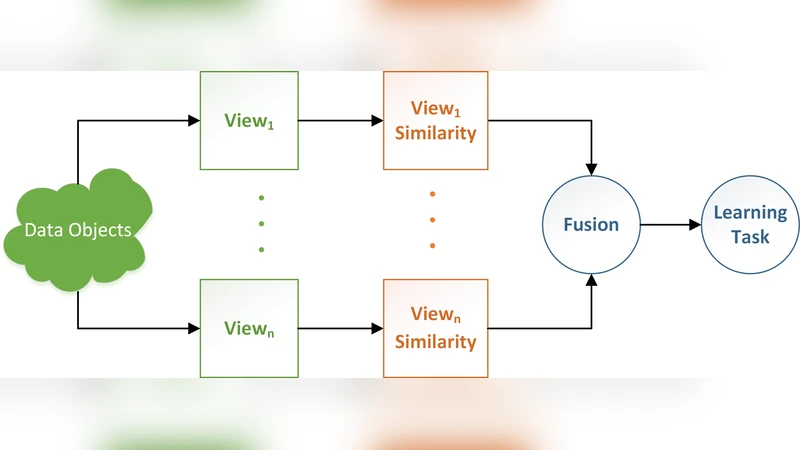
The paper investigates how multi‑view learning can be leveraged to improve software comprehension tasks such as modularization, component‑level refactoring recommendation, and cross‑modal source‑code search. The authors define a “view” as a domain‑specific representation of a software system, and consider four concrete views: the module dependency graph, execution logs, evolutionary information (e.g., co‑change frequency from version control), and the lexical vocabulary extracted from source code. Each view captures complementary aspects of the software, but individually they are noisy or incomplete.
To combine these heterogeneous sources, the study evaluates three state‑of‑the‑art multi‑view learning paradigms: (1) Multiple Kernel Learning (MKL), which learns a weighted combination of view‑specific kernels; (2) Co‑training, which iteratively exchanges high‑confidence predictions between two or more views to exploit unlabeled data; and (3) Subspace Learning, which projects all views into a shared latent space enabling cross‑modal retrieval. For each view a similarity matrix is first built using domain‑specific coupling heuristics (e.g., call‑graph dependencies, textual similarity, co‑change metrics). These matrices are then transformed into kernels or fed directly into the data‑fusion component.
The experimental evaluation uses ten large open‑source Java projects (ranging from a few thousand to over ten thousand classes). Two quantitative tasks are examined: (a) software modularization, where the goal is to cluster classes into high‑cohesion, low‑coupling modules; and (b) component‑level refactoring recommendation, where the system suggests high‑level restructuring actions (e.g., extract class, move method) based on the learned dependencies. In addition, a qualitative cross‑modal code‑search experiment is performed on the jEdit project, demonstrating that a joint latent space can retrieve relevant code fragments even when the query originates from a different modality (e.g., a textual description versus an execution trace).
Results show that multi‑view approaches consistently outperform single‑view baselines. MKL achieves the largest improvement in modularization quality (measured by the Modularity Quality metric), delivering 7–12 % higher scores than any single view. Co‑training and subspace learning also provide significant gains, especially when evolutionary data and execution logs are combined with structural dependencies. For refactoring recommendation, the fused view model produces suggestions that respect both design principles and historical change patterns, which were rated by domain experts as more actionable than those derived from structural analysis alone. In the cross‑modal retrieval scenario, the shared latent space yields a 15 % increase in Mean Average Precision compared with a conventional keyword‑only search, and users reported that the results better matched their intent.
The authors acknowledge several limitations. The methodology assumes a complete mapping of software entities across all views, which may not hold in projects with missing or inconsistent metadata. Kernel selection and hyper‑parameter tuning are performed manually, suggesting a need for automated model selection. Finally, the refactoring recommendations are high‑level architectural suggestions rather than fine‑grained code transformations, leaving a gap to fully automated refactoring tools.
In conclusion, the paper demonstrates that multi‑view learning is a powerful paradigm for software engineering problems that can be cast as learning tasks. By jointly exploiting structural, dynamic, historical, and textual information, the proposed techniques reduce noise, capture richer semantics, and improve the quality of modularization, recommendation, and search. Future work is outlined to address incomplete views, employ meta‑learning for kernel optimization, and integrate static and dynamic analyses for more precise automated refactoring. This research paves the way for next‑generation development environments that intelligently fuse diverse software artefacts to support developers’ comprehension and maintenance activities.
Comments & Academic Discussion
Loading comments...
Leave a Comment