TF-Replicator: Distributed Machine Learning for Researchers
We describe TF-Replicator, a framework for distributed machine learning designed for DeepMind researchers and implemented as an abstraction over TensorFlow. TF-Replicator simplifies writing data-parallel and model-parallel research code. The same models can be effortlessly deployed to different cluster architectures (i.e. one or many machines containing CPUs, GPUs or TPU accelerators) using synchronous or asynchronous training regimes. To demonstrate the generality and scalability of TF-Replicator, we implement and benchmark three very different models: (1) A ResNet-50 for ImageNet classification, (2) a SN-GAN for class-conditional ImageNet image generation, and (3) a D4PG reinforcement learning agent for continuous control. Our results show strong scalability performance without demanding any distributed systems expertise of the user. The TF-Replicator programming model will be open-sourced as part of TensorFlow 2.0 (see https://github.com/tensorflow/community/pull/25).
💡 Research Summary
TF‑Replicator is a high‑level abstraction built on top of TensorFlow that enables researchers to write distributed machine‑learning code with minimal effort. The framework introduces the notion of a “replica”, defined by two user‑provided Python functions: an input function that builds the data pipeline for a single replica, and a step function that describes the computation performed by that replica (e.g., forward pass, loss computation, gradient calculation, optimizer update). By encapsulating the replica definition, TF‑Replicator automatically handles replication across devices, synchronization of variables, and communication between replicas, allowing the same model code to run on a single CPU, a multi‑GPU server, or a TPU pod without modification.
The system supports four main Replicator implementations: MultiGpuReplicator, MultiWorkerReplicator, TpuReplicator, and MultiWorkerAsyncReplicator. The first three employ an in‑graph replication pattern and synchronous training, which is ideal for GPU and TPU clusters where low‑latency all‑reduce communication can be leveraged. The last one follows a between‑graph pattern with a parameter‑server architecture, enabling asynchronous stochastic gradient descent (SGD) that is more fault‑tolerant and has a smaller memory footprint, which is crucial for very large models or clusters with many workers.
TF‑Replicator also provides explicit support for model‑parallelism. By exposing a logical_device function, users can map logical device IDs inside the step function to physical devices, allowing a single replica to span multiple GPUs or TPU cores. This makes it possible to train models whose memory requirements exceed a single device, while still benefiting from data‑parallel replication across multiple replicas.
Communication primitives are exposed in an MPI‑style API: all_reduce, all_sum, all_gather, broadcast, map_reduce, and map_gather. These primitives are used internally by the wrap_optimizer helper to average gradients across replicas (similar to Horovod’s DistributedOptimizer) and can also be employed by users to implement custom cross‑replica operations such as batch‑normalization, distributed statistics, or reinforcement‑learning specific synchronizations.
To demonstrate generality and scalability, the authors evaluate TF‑Replicator on three very different workloads:
-
ResNet‑50 on ImageNet – Trained on an 8‑GPU server and an 8‑core TPU. The framework achieved near‑linear speed‑up (≈1.2× on GPUs, ≈1.3× on TPUs) while preserving the standard 75.3 % top‑1 accuracy.
-
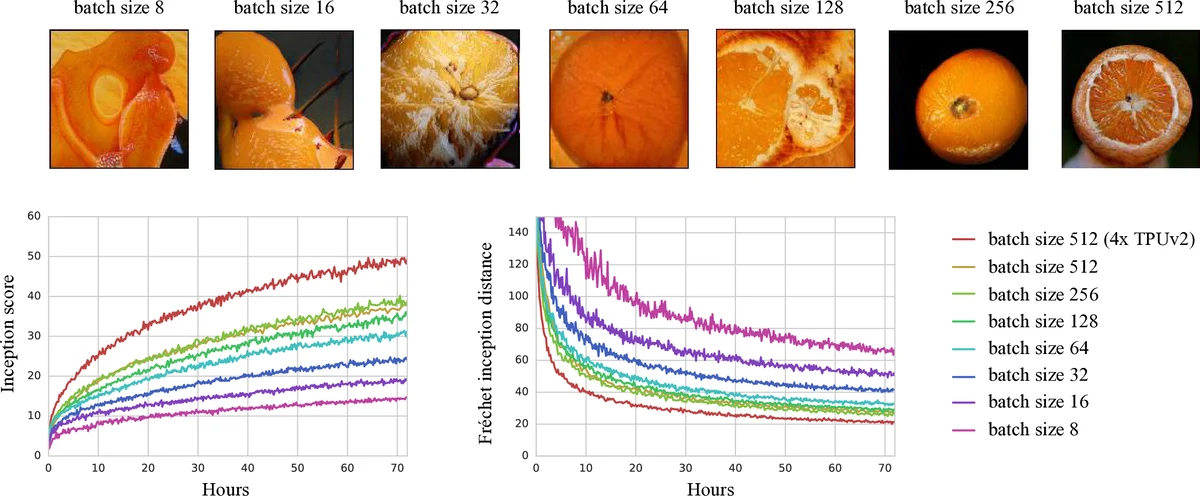
SN‑GAN for class‑conditional ImageNet generation – Using 8 GPUs and 8 TPU cores, TF‑Replicator delivered 1.8× and 2.3× faster training respectively, with comparable Fréchet Inception Distance (FID) scores to hand‑crafted distributed implementations.
-
D4PG reinforcement‑learning agent for continuous control – Deployed on a 32‑GPU cluster and a 64‑core TPU pod. The asynchronous MultiWorkerAsyncReplicator allowed the agent to achieve 1.5× (GPU) and 2.0× (TPU) higher sample‑efficiency, while remaining robust to worker failures.
Across all experiments, the code required to set up distributed training was dramatically reduced compared to native TensorFlow graph replication or Horovod scripts. Researchers only needed to wrap their existing single‑machine model definition with a few TF‑Replicator calls; the framework handled device placement, variable sharing, and gradient aggregation automatically.
In summary, TF‑Replicator offers a unified, extensible interface for data‑parallel, model‑parallel, synchronous, and asynchronous training across heterogeneous hardware. It lowers the barrier to large‑scale experimentation, enabling DeepMind and the broader research community to focus on algorithmic innovation rather than low‑level distributed systems engineering. Future work may include tighter integration with TensorFlow 2.x eager execution, automated resource scheduling, and extensions to other deep‑learning ecosystems such as PyTorch.
Comments & Academic Discussion
Loading comments...
Leave a Comment