Bootstrapping Intrinsically Motivated Learning with Human Demonstrations
This paper studies the coupling of internally guided learning and social interaction, and more specifically the improvement owing to demonstrations of the learning by intrinsic motivation. We present Socially Guided Intrinsic Motivation by Demonstration (SGIM-D), an algorithm for learning in continuous, unbounded and non-preset environments. After introducing social learning and intrinsic motivation, we describe the design of our algorithm, before showing through a fishing experiment that SGIM-D efficiently combines the advantages of social learning and intrinsic motivation to gain a wide repertoire while being specialised in specific subspaces.
💡 Research Summary
The paper introduces SGIM‑D (Socially Guided Intrinsic Motivation by Demonstration), an algorithm that tightly couples human demonstration with intrinsic‑motivation‑driven autonomous exploration. The authors begin by contrasting two dominant learning paradigms in robotics: social learning, where a human teacher provides explicit demonstrations or instructions, and intrinsically motivated learning, where the robot self‑generates goals based on internal measures of learning progress. Social learning offers rapid acquisition of complex skills but suffers when demonstrations are unavailable or when the robot must adapt to novel conditions. Intrinsic motivation, on the other hand, enables open‑ended exploration in unstructured, continuous spaces, yet it typically incurs high sample complexity during early stages because the robot must discover useful goals from scratch.
SGIM‑D addresses these complementary weaknesses by arranging the learning process in two hierarchical layers. The upper layer receives a limited set of human demonstrations. These demonstrations are transformed into goal‑action pairs and used to initialize the policy parameters and to shape an initial probability distribution over the goal space. This “demo module” supplies informative samples that dramatically reduce the sparsity problem inherent in high‑dimensional continuous domains. The lower layer implements an intrinsic‑motivation module that continuously evaluates a learning‑progress (LP) signal—essentially the rate of reduction in prediction error for each subregion of the goal space. The algorithm partitions the goal space into multiple sub‑spaces, monitors LP within each, and preferentially selects goals from regions where LP is high (i.e., where learning is currently most fruitful). Consequently, SGIM‑D quickly moves beyond the regions already covered by demonstrations and focuses its self‑directed exploration on under‑explored, potentially difficult areas.
Technically, SGIM‑D employs a non‑linear function approximator (Gaussian process regression or deep neural networks) to model the mapping from goals to motor commands. When a new demonstration arrives, it is immediately incorporated into the model, updating both the policy and the LP estimates. The intrinsic‑motivation module then samples new goals according to a probability distribution weighted by LP, while also considering model uncertainty to balance exploitation and exploration. A goal‑selection policy reduces the frequency of sampling in well‑learned sub‑spaces, thereby allocating more trials to regions where the model’s performance is still improving.
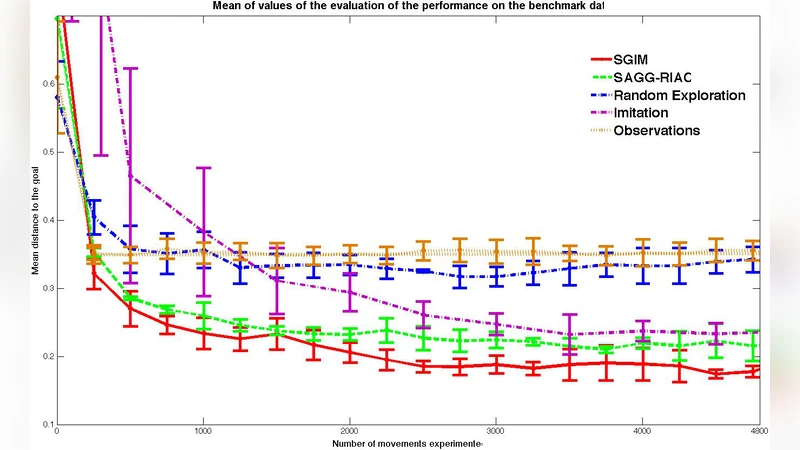
The authors validate SGIM‑D in a simulated fishing task. A robotic arm must learn to cast a lure by adjusting continuous parameters such as launch speed, angle, and applied force. Human demonstrations consist of a handful of successful casts, providing a seed for the policy. After the demo phase, SGIM‑D autonomously explores the full parameter space. Four conditions are compared: pure intrinsic‑motivation learning, pure demonstration learning, demonstration followed by random exploration, and the full SGIM‑D algorithm. Results show that SGIM‑D achieves the fastest convergence, the widest coverage of successful parameter combinations, and the highest final success rate. Notably, SGIM‑D also discovers high‑performance casts in “extreme” regions of the parameter space that were not covered by the demonstrations, whereas the pure intrinsic‑motivation baseline required many more trials to reach those regions.
Key contributions of the work include: (1) a dynamic switching mechanism that leverages human demonstrations for rapid initial skill acquisition and then hands control to an LP‑driven autonomous explorer; (2) a principled learning‑progress estimator that guides goal selection in continuous, unbounded environments; (3) empirical evidence that a modest number of demonstrations, when combined with intrinsic motivation, yields superior sample efficiency compared to either method alone; and (4) a framework that can be extended to real‑world human‑robot interaction scenarios where pre‑defining goals is infeasible.
The paper concludes with several avenues for future research: incorporating multiple teachers to increase demonstration diversity, developing methods to assess and correct noisy or incomplete demonstrations, transferring the approach to physical robots to handle real‑world sensor noise and actuation constraints, and integrating language‑based instructions to create a multimodal socially guided learning system. By unifying social guidance and self‑directed curiosity, SGIM‑D offers a promising pathway toward robots that can learn efficiently from limited human input while retaining the capacity for open‑ended, lifelong skill acquisition.
Comments & Academic Discussion
Loading comments...
Leave a Comment