Unveiling Exception Handling Guidelines Adopted by Java Developers
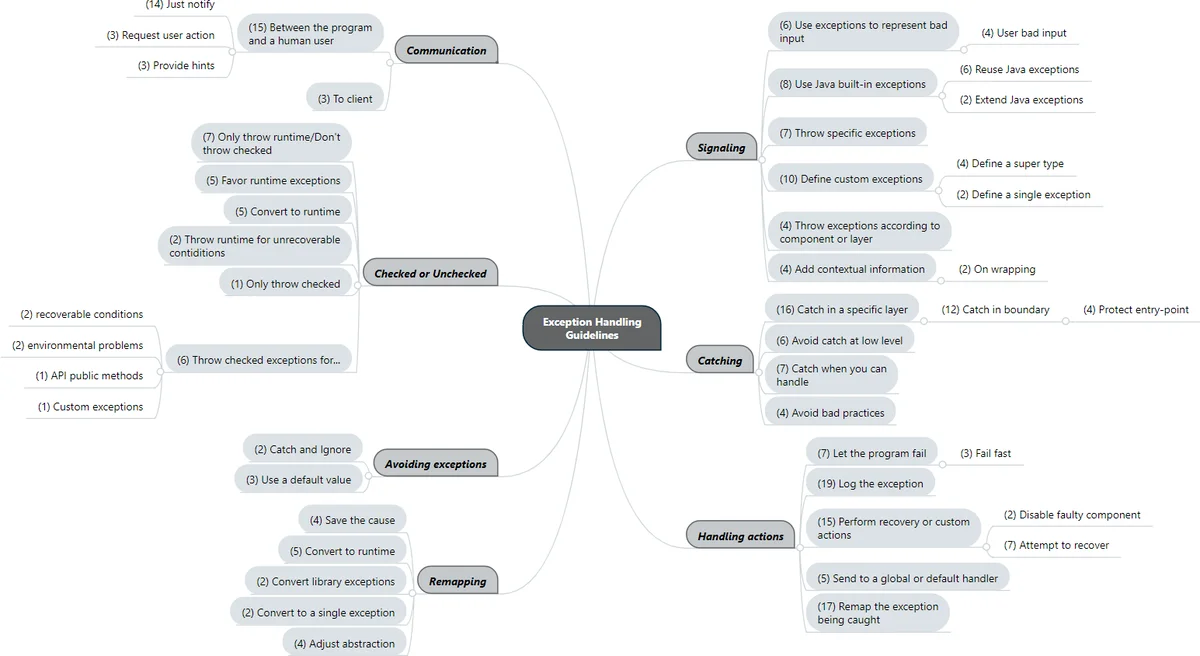
Despite being an old language feature, Java exception handling code is one of the least understood parts of many systems. Several studies have analyzed the characteristics of exception handling code, trying to identify common practices or even link such practices to software bugs. Few works, however, have investigated exception handling issues from the point of view of developers. None of the works have focused on discovering exception handling guidelines adopted by current systems – which are likely to be a driver of common practices. In this work, we conducted a qualitative study based on semi-structured interviews and a survey whose goal was to investigate the guidelines that are (or should be) followed by developers in their projects. Initially, we conducted semi-structured interviews with seven experienced developers, which were used to inform the design of a survey targeting a broader group of Java developers (i.e., a group of active Java developers from top-starred projects on GitHub). We emailed 863 developers and received 98 valid answers. The study shows that exception handling guidelines usually exist (70%) and are usually implicit and undocumented (54%). Our study identifies 48 exception handling guidelines related to seven different categories. We also investigated how such guidelines are disseminated to the project team and how compliance between code and guidelines is verified; we could observe that according to more than half of respondents the guidelines are both disseminated and verified through code inspection or code review. Our findings provide software development teams with a means to improve exception handling guidelines based on insights from the state of practice of 87 software projects.
💡 Research Summary
This paper presents a mixed‑methods investigation into the state of exception‑handling guidelines used by Java developers in real‑world projects. The authors first conducted semi‑structured interviews with seven experienced developers to gather preliminary insights about the existence, form, and dissemination of exception‑handling rules. These insights informed the design of a broader survey targeting active Java contributors on GitHub.
Using the GitHub API, the researchers filtered repositories by star count (minimum 24 stars), creation date (before 01‑Jan‑2018), recent activity (last commit within 30 days), and non‑Android status, yielding 4 449 repositories. From these they identified 863 developers who had made at least five commits in the previous month and whose email addresses were publicly available. All 863 were invited to participate; 98 valid responses were received (≈11 % response rate), representing 87 distinct projects.
The questionnaire comprised ten items, mixing Likert‑scale, multiple‑choice, and open‑ended questions. It asked participants to indicate whether their projects had rules governing (1) exception signaling, (2) exception catching, and (3) post‑catch handling actions, and if so, whether those rules were explicit (documented) or implicit (known but undocumented). Follow‑up questions collected concrete examples of the rules. Additional items probed how the rules are disseminated (e.g., via team leads, wikis, code comments) and how compliance is verified (e.g., code review, static analysis, CI checks).
Demographically, respondents were seasoned: 72 % had six or more years of software‑development experience, and 77 % agreed that they regularly spend time reading, writing, or thinking about exception handling while coding.
Key quantitative findings:
- Existence of rules – 70 % reported having signaling rules, 51 % catching rules, and 59 % handling‑action rules.
- Explicit vs. implicit – Among projects with rules, the majority were implicit (54 % signaling, 40 % catching, 39 % handling). Explicit, documented rules were a minority (16 % signaling, 12 % catching, 19 % handling).
- Dissemination – The most common channels were verbal communication from senior developers/team leads (45 %), repository wikis/README files (31 %), and code comments (24 %).
- Compliance verification – Code review was the dominant mechanism (53 %), followed by static‑analysis tools (38 %) and CI‑pipeline checks (22 %). Many teams used a combination of these methods.
For the qualitative component, the authors applied Grounded Theory techniques. Open coding of the 155 textual responses (from the three open‑ended questions) produced 189 initial codes. Axial coding refined these into 48 distinct guidelines, which were grouped into seven high‑level categories:
- Signaling – When and how to throw exceptions (e.g., prefer custom checked exceptions over generic RuntimeException, avoid throwing NPE directly).
- Catching – Where in the architecture exceptions should be caught (e.g., catch at service layer, let lower layers propagate).
- Handling actions – What to do after catching (e.g., always log, perform retry if recoverable, translate to user‑friendly messages).
- Checked vs. unchecked – Guidance on choosing between checked and unchecked exceptions (e.g., external‑system failures as checked, programming errors as unchecked).
- Communication – How to expose exception information to callers or external APIs (e.g., standardized JSON error payloads for REST services).
- Logging & monitoring – Log level conventions, structured logging, integration with APM tools.
- Testability – Strategies for testing exceptional paths (e.g., JUnit ExpectedException, AssertJ assertThatThrownBy).
Each guideline is accompanied by a memo describing its rationale and any observed tensions (e.g., differing opinions on the overuse of checked exceptions).
The authors argue that prior work has largely focused on static characteristics of exception‑handling code (e.g., bug patterns, anti‑patterns) whereas this study uncovers the human and process dimensions: the prevalence of undocumented conventions, reliance on peer review, and the need for better documentation. The findings suggest several practical implications:
- Documentation need – Organizations should formalize implicit conventions to reduce knowledge loss and onboarding friction.
- Tool support – Enhancing code‑review checklists and extending static‑analysis rules to capture project‑specific guidelines can improve compliance.
- Education – Training curricula should cover the nuanced decisions between checked and unchecked exceptions, and the recommended handling patterns identified in the study.
- Policy baseline – The 48 extracted guidelines can serve as a starting point for teams crafting their own exception‑handling policies.
Limitations include the focus on open‑source, high‑star GitHub projects (potentially biasing toward more mature or well‑maintained codebases) and the modest response rate, which may affect generalizability to private or smaller projects. Future work could broaden the sample, conduct longitudinal studies to measure the impact of guideline adoption on defect density, and develop automated tooling that enforces the identified best‑practice patterns.
In summary, the paper provides a comprehensive, empirically grounded view of how Java developers currently manage exception handling, revealing a landscape dominated by implicit, peer‑review‑driven practices and offering a concrete set of 48 guidelines that can inform both research and industry efforts to improve software robustness.
Comments & Academic Discussion
Loading comments...
Leave a Comment