From Monolith to Microservices: A Classification of Refactoring Approaches
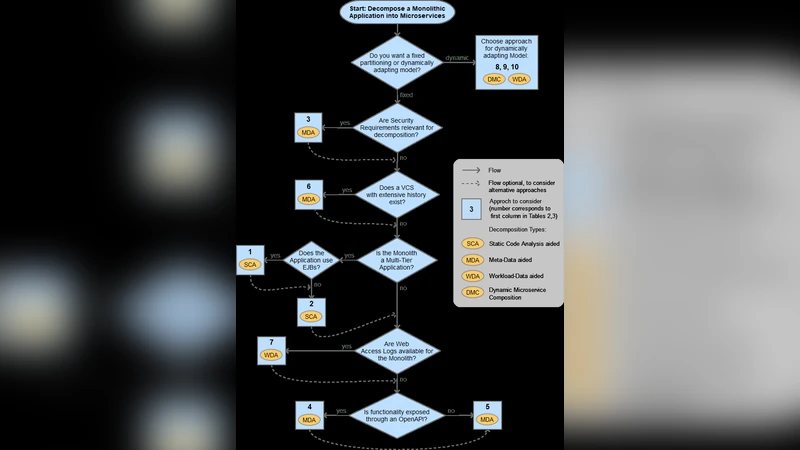
While the recently emerged Microservices architectural style is widely discussed in literature, it is difficult to find clear guidance on the process of refactoring legacy applications. The importance of the topic is underpinned by high costs and effort of a refactoring process which has several other implications, e.g. overall processes (DevOps) and team structure. Software architects facing this challenge are in need of selecting an appropriate strategy and refactoring technique. One of the most discussed aspects in this context is finding the right service granularity to fully leverage the advantages of a Microservices architecture. This study first discusses the notion of architectural refactoring and subsequently compares 10 existing refactoring approaches recently proposed in academic literature. The approaches are classified by the underlying decomposition technique and visually presented in the form of a decision guide for quick reference. The review yielded a variety of strategies to break down a monolithic application into independent services. With one exception, most approaches are only applicable under certain conditions. Further concerns are the significant amount of input data some approaches require as well as limited or prototypical tool support.
💡 Research Summary
The paper addresses the pressing challenge of refactoring legacy monolithic applications into a microservices architecture, a transition that promises benefits such as independent deployment, scalability, and team autonomy but also entails substantial cost, effort, and architectural risk. After defining “architectural refactoring” and distinguishing it from traditional code‑level refactoring, the authors systematically review ten recent academic proposals that describe concrete strategies for breaking a monolith into services.
The core contribution is a taxonomy that classifies these approaches according to the underlying decomposition technique. Four primary categories emerge:
-
Domain‑Driven Decomposition – approaches that rely on explicit domain models or bounded contexts (e.g., extracting bounded contexts, clustering domain events). These methods achieve high granularity accuracy when a well‑documented domain model exists, but they become impractical for legacy systems lacking such models, requiring extensive upfront modeling effort.
-
Functional/Use‑Case Decomposition – techniques that analyze functional requirements, use‑case diagrams, or transaction flows to derive service boundaries (e.g., use‑case driven partitioning, feature‑tree clustering). Their success depends on the availability of detailed functional specifications and on the ability to quantify inter‑feature dependencies.
-
Data‑Centric Decomposition – strategies that focus on database schemas, data ownership, and access patterns (e.g., table‑centric partitioning, data‑ownership mapping). While they make data consistency concerns explicit, they risk over‑fragmentation when business logic is tightly coupled with data, potentially leading to excessive data duplication across services.
-
Runtime/Operational Decomposition – methods that exploit runtime artifacts such as logs, traces, or monitoring metrics (e.g., trace‑driven clustering, runtime interaction analysis). These are attractive because they can be applied with minimal changes to the existing system, but they are highly sensitive to the quality and completeness of the collected operational data and may miss hidden business rules.
A fifth “Hybrid” group combines two or more of the above perspectives, attempting to balance their strengths. However, hybrid approaches typically demand a larger set of heterogeneous inputs and involve complex weighting schemes, making them difficult to adopt without sophisticated tooling.
For each of the ten approaches, the authors document: (a) required input data (source‑code metadata, execution logs, business documentation, schema information, etc.), (b) preconditions for applicability, (c) expected service granularity, (d) level of tool support, and (e) evidence from case studies or experiments. The analysis reveals that nine of the ten methods are conditional—effective only when specific artifacts are available—while only one approach claims broader applicability.
To aid practitioners, the paper presents a visual decision guide. The guide maps an organization’s current assets (code, documentation, operational data) and strategic goals (deployment frequency, team size, desired independence) to the set of suitable decomposition techniques. Although the guide offers quick reference, it lacks quantitative thresholds, meaning that expert judgment remains essential for interpreting the results.
The study also highlights the current scarcity of mature tooling. Most proposals are accompanied by prototype implementations (often open‑source scripts or research‑grade analysis frameworks), and commercial solutions are virtually absent. This tooling gap implies that organizations must invest additional development effort to operationalize the selected approach, potentially eroding the anticipated cost savings of a microservices migration.
In the discussion of limitations, the authors note three major gaps: (1) insufficient sensitivity analysis regarding input‑data quality, (2) limited treatment of post‑decomposition concerns such as data consistency and distributed transaction management, and (3) a lack of empirical research linking refactoring strategies to organizational outcomes like DevOps maturity or team restructuring.
Future research directions proposed include: (i) building integrated, production‑grade toolchains that automate data collection, analysis, and service‑boundary suggestion; (ii) developing hybrid models with empirically validated weighting schemes; and (iii) conducting longitudinal case studies that measure the business impact of different refactoring strategies over time.
In summary, the paper delivers a valuable comparative framework for architects facing monolith‑to‑microservices migrations. It clarifies the landscape of academic proposals, outlines their practical constraints, and supplies a decision‑making aid. At the same time, it candidly exposes the real‑world obstacles—data dependencies, conditional applicability, and limited tooling—that must be addressed before these scholarly approaches can be reliably translated into successful industrial transformations.
Comments & Academic Discussion
Loading comments...
Leave a Comment