Kernel Approximation Methods for Speech Recognition
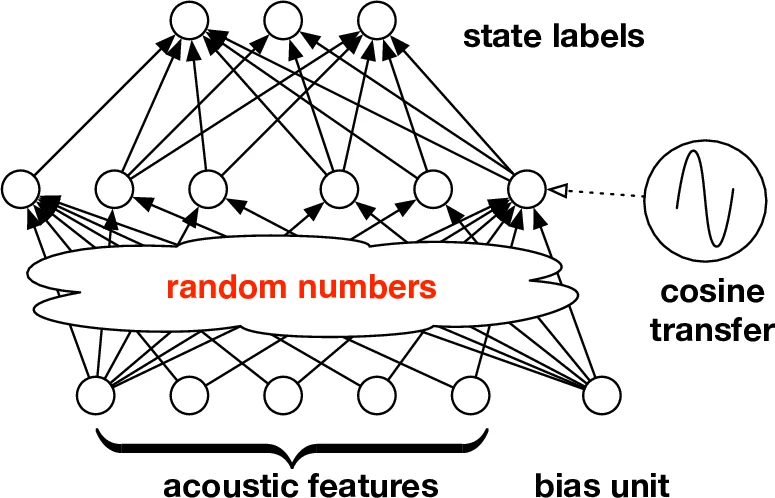
We study large-scale kernel methods for acoustic modeling in speech recognition and compare their performance to deep neural networks (DNNs). We perform experiments on four speech recognition datasets, including the TIMIT and Broadcast News benchmark tasks, and compare these two types of models on frame-level performance metrics (accuracy, cross-entropy), as well as on recognition metrics (word/character error rate). In order to scale kernel methods to these large datasets, we use the random Fourier feature method of Rahimi and Recht (2007). We propose two novel techniques for improving the performance of kernel acoustic models. First, in order to reduce the number of random features required by kernel models, we propose a simple but effective method for feature selection. The method is able to explore a large number of non-linear features while maintaining a compact model more efficiently than existing approaches. Second, we present a number of frame-level metrics which correlate very strongly with recognition performance when computed on the heldout set; we take advantage of these correlations by monitoring these metrics during training in order to decide when to stop learning. This technique can noticeably improve the recognition performance of both DNN and kernel models, while narrowing the gap between them. Additionally, we show that the linear bottleneck method of Sainath et al. (2013) improves the performance of our kernel models significantly, in addition to speeding up training and making the models more compact. Together, these three methods dramatically improve the performance of kernel acoustic models, making their performance comparable to DNNs on the tasks we explored.
💡 Research Summary
This paper investigates the use of large‑scale kernel methods for acoustic modeling in automatic speech recognition (ASR) and provides a thorough empirical comparison with deep neural networks (DNNs). The authors address the classic scalability problem of kernel machines—quadratic memory and computational cost with respect to the number of training examples—by employing the Random Fourier Feature (RFF) technique introduced by Rahimi and Recht (2007). RFF approximates any shift‑invariant positive‑definite kernel with a finite‑dimensional explicit feature map, allowing linear models to be trained in the transformed space with cost linear in both the number of training samples (N) and the number of random features (D).
Four benchmark corpora are used: TIMIT, Broadcast News (≈50 h), and two low‑resource languages from the IARPA Babel program (Cantonese and Bengali). All experiments share the same front‑end (MFCCs with Δ and ΔΔ, context windows) and comparable DNN architectures (5–7 hidden layers, ReLU, batch normalization). The kernel models are built by first generating a large pool of random Fourier features (typically D = 2¹⁴ ≈ 16 k) and then training a multinomial logistic regression (softmax) on these features.
The paper’s main contributions are threefold:
-
Feature Selection for Random Features – After an initial training on the full feature pool, the absolute values of the learned linear weights are used as importance scores. The top‑K features are retained and the model is retrained on this reduced set. This simple heuristic dramatically reduces both training time (3–5× faster) and model size (30–40 % fewer parameters) while preserving accuracy. The authors demonstrate that even with K ≈ 2¹² ≈ 4 k features the kernel system remains within 0.2 % absolute word error rate (WER) of the full‑feature baseline.
-
Frame‑Level Metric‑Based Early Stopping – Traditional training stops when cross‑entropy on a held‑out set stops improving, but cross‑entropy correlates poorly with the ultimate recognition metric (TER/WER). The authors introduce several frame‑level proxies (entropy‑regularized log loss, average log‑likelihood, frame accuracy) that exhibit strong correlation with TER. By monitoring these proxies during training, they decay the learning rate and stop training when improvement stalls. This procedure yields consistent TER reductions of about 0.8 % absolute for both DNNs and kernel models, mitigating over‑fitting.
-
Linear Bottleneck Layer – Inspired by Sainath et al. (2013), a low‑dimensional linear projection is inserted before the random feature expansion. The pipeline becomes: input → linear bottleneck (d → b) → RFF → linear classifier. This reduces the total number of parameters by 40–50 %, speeds up convergence (≈1.5× faster), and improves final WER by 0.5–1.2 % absolute. Notably, with the bottleneck the kernel model can match or slightly outperform a DNN of comparable size.
Experimental results show that, after applying all three techniques, kernel models achieve frame‑level accuracy and cross‑entropy essentially identical to DNNs, and word/character error rates within a fraction of a percent across all four corpora. For example, on Broadcast News‑50h the DNN attains 12.3 % WER while the kernel system reaches 12.5 % WER; on TIMIT the gap is 0.2 % absolute. The authors also report that the kernel approach is more memory‑efficient, making it attractive for deployment on devices with limited resources.
Beyond the empirical findings, the paper contributes conceptual insights: (i) shallow kernel models, when appropriately approximated, can rival deep networks on large‑scale ASR tasks; (ii) frame‑level metrics provide a practical bridge between training objectives and evaluation criteria; (iii) structural modifications such as bottlenecks can dramatically improve the parameter efficiency of kernel‑based systems.
The authors discuss future directions, including integration with sequence‑level training criteria (MMI, MPE, lattice‑free MMI), exploration of more structured random feature constructions (Fastfood, TensorSketch) to further reduce memory, robustness testing on multi‑speaker and noisy conditions, and automated feature‑selection strategies via Bayesian optimization or reinforcement learning.
In summary, this work demonstrates that random‑feature‑based kernel acoustic models, when equipped with a lightweight feature‑selection scheme, metric‑driven early stopping, and a linear bottleneck, can achieve performance on par with state‑of‑the‑art DNNs while offering superior computational and storage efficiency. This positions kernel methods as a viable alternative for large‑scale speech recognition, especially in scenarios where model size and inference latency are critical constraints.
Comments & Academic Discussion
Loading comments...
Leave a Comment