Development of Mobile-Interfaced Machine Learning-Based Predictive Models for Improving Students Performance in Programming Courses
Student performance modelling (SPM) is a critical step to assessing and improving students performances in their learning discourse. However, most existing SPM are based on statistical approaches, which on one hand are based on probability, depicting that results are based on estimation; and on the other hand, actual influences of hidden factors that are peculiar to students, lecturers, learning environment and the family, together with their overall effect on student performance have not been exhaustively investigated. In this paper, Student Performance Models (SPM) for improving students performance in programming courses were developed using M5P Decision Tree (MDT) and Linear Regression Classifier (LRC). The data used was gathered using a structured questionnaire from 295 students in 200 and 300 levels of study who offered Web programming, C or JAVA at Federal University, Oye-Ekiti, Nigeria between 2012 and 2016. Hidden factors that are significant to students performance in programming were identified. The relevant data gathered, normalized, coded and prepared as variable and factor datasets, and fed into the MDT algorithm and LRC to develop the predictive models. The evaluation results obtained indicate that the variable-based LRC produced the best model in terms of MAE, RMSE, RAE and the RRSE having yielded the least values in all the evaluations conducted. Further results obtained established the strong significance of attitude of students and lecturers, fearful perception of students, erratic power supply, university facilities, student health and students attendance to the performance of students in programming courses. The variable-based LRC model presented in this paper could provide baseline information about students performance thereby offering better decision making towards improving teaching/learning outcomes in programming courses.
💡 Research Summary
The paper addresses the problem of predicting student performance in university programming courses by developing machine‑learning models and deploying them in a mobile application. The authors note that most existing student performance models rely on statistical, probability‑based methods that estimate outcomes but often fail to capture hidden, context‑specific factors influencing learners. To overcome this limitation, the study collects primary data from 295 undergraduate students (levels 200 and 300) who took Web programming, C, or Java at Federal University, Oye‑Ekiti, Nigeria between 2012 and 2016. A structured questionnaire, informed by literature review, interviews, and field observations, elicits responses on a wide range of variables such as student and lecturer attitudes, study habits, fear of programming, power‑supply reliability, campus facilities, health status, and attendance. The responses are normalized, coded, and organized into two datasets: a variable‑based set (individual questionnaire items) and a factor‑based set (aggregated latent constructs).
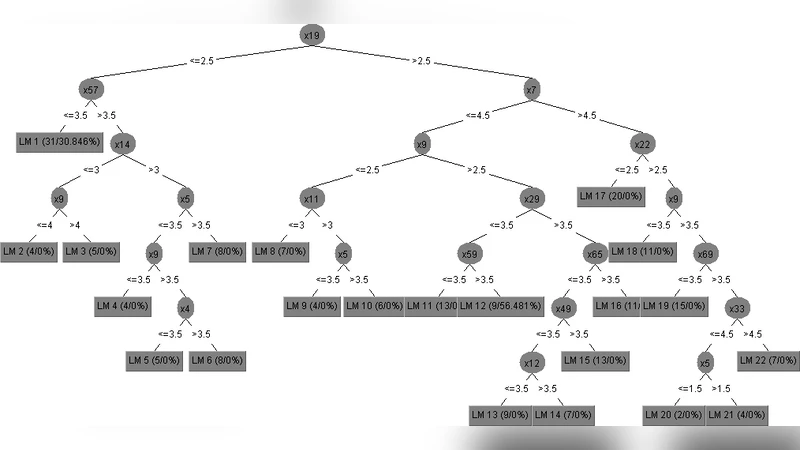
Two widely used machine‑learning algorithms are employed: the M5P decision tree (a regression‑tree learner that uses mean‑squared‑error as its impurity measure and applies error‑based pruning) and a Linear Regression Classifier (LRC) that fits a linear model to the data using ordinary least squares. Both algorithms are implemented in the WEKA environment, and model building time and testing time are recorded for comparative purposes.
Model performance is evaluated using four error metrics: Mean Absolute Error (MAE), Root Mean Squared Error (RMSE), Relative Absolute Error (RAE), and Root Relative Squared Error (RRSE). Across all metrics, the variable‑based LRC consistently yields the lowest values, indicating superior predictive accuracy and robustness compared with the M5P tree. The authors attribute this advantage to the strong linear relationships present among the identified variables (e.g., attitudes, attendance) and the tendency of the decision tree to over‑fit when handling many correlated attributes.
A factor analysis of the questionnaire data reveals six hidden factors that significantly affect programming course outcomes: (1) student attitude, (2) lecturer attitude, (3) student fear or anxiety, (4) erratic power supply, (5) university facilities, (6) student health and attendance. Regression coefficients show that attitudes and fear have the largest absolute impact, underscoring the importance of affective and psychological dimensions in programming education.
To make the predictive models accessible to stakeholders, the authors develop an Android 1.0.1 application using XML for the graphical user interface and Java for the underlying logic. Users input the values of the relevant variables, and the app instantly returns a predicted performance score, enabling students to gauge their risk of failure and allowing lecturers or administrators to intervene proactively. The mobile interface enhances ubiquity, allowing real‑time decision support in the classroom or at home.
The paper’s contributions are threefold: (1) systematic identification and coding of hidden, context‑specific factors beyond traditional statistical models; (2) empirical comparison of M5P decision trees and linear regression classifiers, demonstrating that a simple linear model can outperform a more complex tree when variables exhibit linear dependencies; (3) implementation of the best‑performing model in a mobile app, bridging the gap between predictive analytics and practical educational interventions.
Limitations include the single‑institution sample, which may restrict external validity, and reliance on self‑reported questionnaire data, which can introduce bias. Future work is suggested to collect multi‑institution datasets, explore deep‑learning architectures capable of capturing non‑linear interactions, and integrate longitudinal data to improve model generalizability and predictive power.
Comments & Academic Discussion
Loading comments...
Leave a Comment