Frechet Audio Distance: A Metric for Evaluating Music Enhancement Algorithms
We propose the Fr'echet Audio Distance (FAD), a novel, reference-free evaluation metric for music enhancement algorithms. We demonstrate how typical evaluation metrics for speech enhancement and blind source separation can fail to accurately measure the perceived effect of a wide variety of distortions. As an alternative, we propose adapting the Fr'echet Inception Distance (FID) metric used to evaluate generative image models to the audio domain. FAD is validated using a wide variety of artificial distortions and is compared to the signal based metrics signal to distortion ratio (SDR), cosine distance and magnitude L2 distance. We show that, with a correlation coefficient of 0.52, FAD correlates more closely with human perception than either SDR, cosine distance or magnitude L2 distance, with correlation coefficients of 0.39, -0.15 and -0.01 respectively.
💡 Research Summary
The paper introduces Fréchet Audio Distance (FAD), a novel, reference‑free metric for evaluating music enhancement algorithms. Existing evaluation methods such as Signal‑to‑Distortion Ratio (SDR), Signal‑to‑Interference Ratio (SIR), cosine distance, and L2 distance are full‑reference metrics that compare an enhanced signal directly to a clean studio recording. While useful for measuring signal fidelity, these metrics often fail to align with human perception, especially for transformations that alter timing, pitch, or phase without significantly degrading perceived quality. Moreover, they require the original clean reference, which is unavailable in many real‑world scenarios (e.g., user‑generated recordings on social platforms).
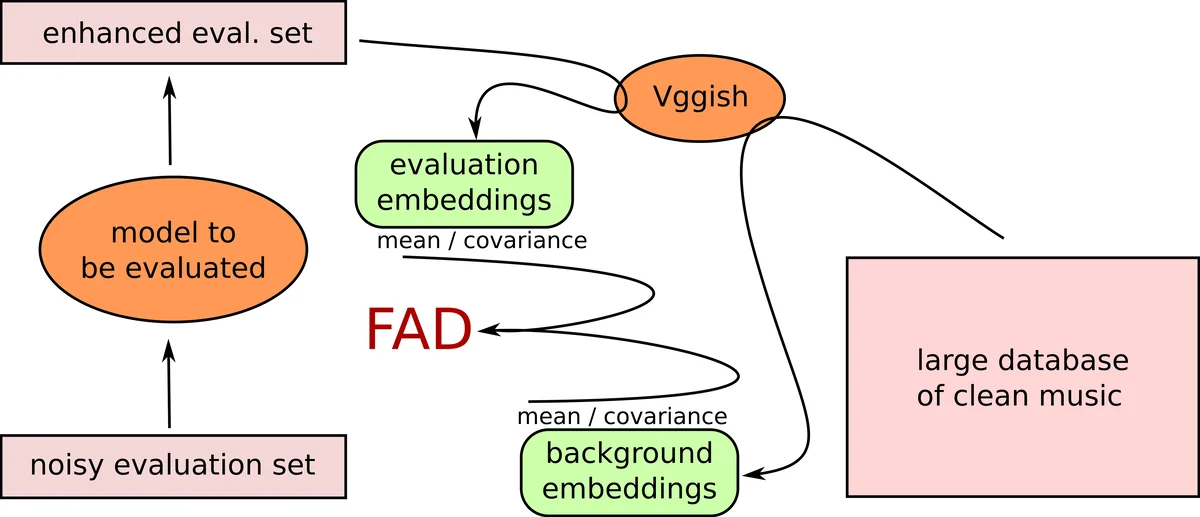
FAD adapts the Fréchet Inception Distance (FID) from image generation evaluation to the audio domain. Instead of pixel‑level features, it uses high‑level audio embeddings extracted from a pre‑trained VGGish model—a convolutional network originally trained on millions of YouTube videos for audio classification. VGGish processes 1‑second windows of log‑mel spectrograms and outputs 128‑dimensional embeddings that capture semantic characteristics of the audio. For a large background set of clean studio music (540 h from the MagnaTagATune dataset), the mean vector µ_b and covariance matrix Σ_b of these embeddings are computed. For any set of enhanced audio clips, the corresponding statistics µ_e and Σ_e are calculated. The Fréchet distance between the two multivariate Gaussians,
F(N_b, N_e) = ‖µ_b − µ_e‖² + tr(Σ_b + Σ_e − 2(Σ_b Σ_e)^{1/2}),
serves as the FAD score. Lower scores indicate that the enhanced audio distribution is statistically closer to the clean distribution. Because the background statistics are fixed, FAD can be applied without any reference to the original clean version of the specific test clips, making it truly reference‑free.
The authors evaluate FAD through two complementary experiments. First, they apply a suite of twelve artificial distortions—Gaussian noise, random POPs, high/low‑pass filtering, quantization, Griffin‑Lim phase reconstruction, mel‑scale filtering (narrow and wide), speed changes, pitch‑preserving speed changes, reverberation, and pitch shifting—to 60 h of test audio. Each distortion is varied across a range of parameters, producing a spectrum of degradation levels. FAD scores consistently increase with distortion severity, confirming that the metric is sensitive to perceptual degradation. Notably, subtle Gaussian noise (σ ≈ 0.03) yields FAD ≈ 0.3, comparable to the score for undistorted audio (≈ 0.2), reflecting the fact that such noise is barely audible. More severe manipulations—e.g., Griffin‑Lim with only five iterations—produce high FAD values (≈ 2.4), which decrease as iteration count rises, mirroring human judgments of phase quality.
Second, a large‑scale human listening test is conducted. Three hundred 5‑second clips are presented in random paired comparisons; listeners are asked which clip sounds “most like a studio‑recorded version.” The resulting preference scores are correlated with four objective metrics: FAD, SDR (negated to keep lower‑is‑better), cosine distance, and magnitude‑L2 distance. Pearson correlation coefficients reveal that FAD (r = 0.52) aligns best with human perception, outperforming SDR (0.39), cosine distance (‑0.15), and L2 (‑0.01). Visual analyses further show that while cosine distance and SDR cluster additive distortions together, they fail to discriminate time‑stretch or pitch‑preserving transformations, which all receive a cosine distance of 1 yet produce varied human ratings. FAD, by contrast, separates these groups, assigning higher distances to transformations that humans find more disruptive.
The paper also discusses limitations. VGGish embeddings are derived solely from log‑mel magnitude spectra, discarding phase information; consequently, certain phase‑only distortions may be under‑represented, as observed with Griffin‑Lim reconstructions. Additionally, VGGish’s training data (YouTube videos) may bias the embedding space toward popular genres and recording conditions, potentially affecting generalization to niche music styles. The authors suggest future work could replace or augment VGGish with embeddings that retain phase (e.g., wav2vec 2.0, YAMNet) or employ multi‑embedding ensembles to capture a broader range of acoustic attributes.
In conclusion, Fréchet Audio Distance provides a practical, reference‑free tool for objectively assessing music enhancement systems. Its strong correlation with human subjective quality, sensitivity to a wide array of distortions, and independence from ground‑truth references make it especially valuable for real‑world applications where clean studio recordings are unavailable, such as mobile recordings, user‑generated content platforms, and streaming services. By offering a metric that better reflects perceived audio quality, FAD can guide the development and benchmarking of future music enhancement algorithms.
Comments & Academic Discussion
Loading comments...
Leave a Comment