Actions Speak Louder Than (Pass)words: Passive Authentication of Smartphone Users via Deep Temporal Features
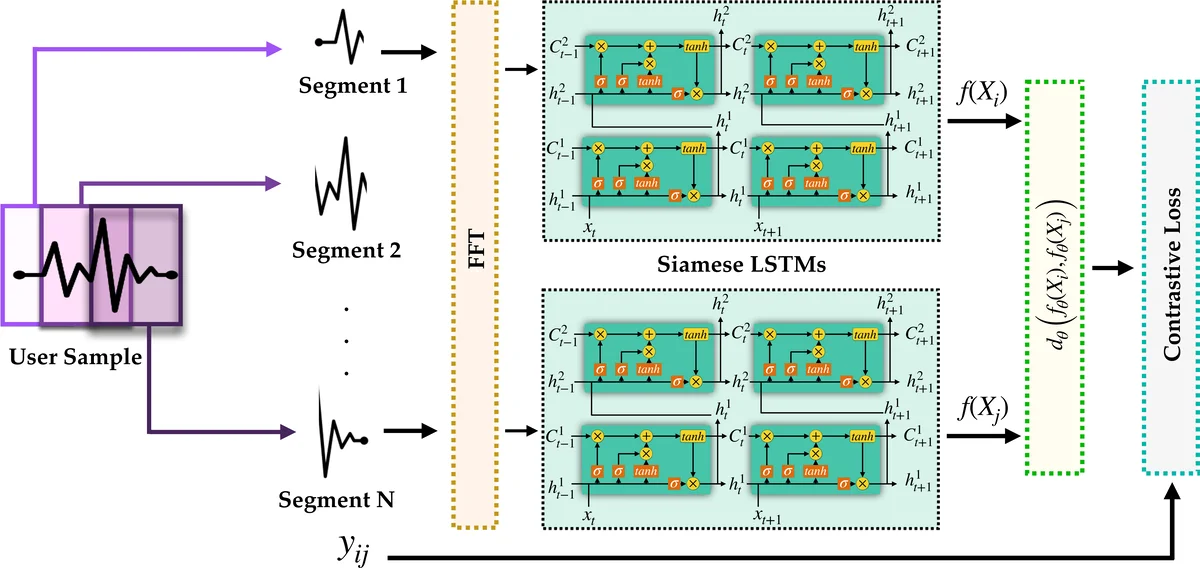
Prevailing user authentication schemes on smartphones rely on explicit user interaction, where a user types in a passcode or presents a biometric cue such as face, fingerprint, or iris. In addition to being cumbersome and obtrusive to the users, such authentication mechanisms pose security and privacy concerns. Passive authentication systems can tackle these challenges by frequently and unobtrusively monitoring the user’s interaction with the device. In this paper, we propose a Siamese Long Short-Term Memory network architecture for passive authentication, where users can be verified without requiring any explicit authentication step. We acquired a dataset comprising of measurements from 30 smartphone sensor modalities for 37 users. We evaluate our approach on 8 dominant modalities, namely, keystroke dynamics, GPS location, accelerometer, gyroscope, magnetometer, linear accelerometer, gravity, and rotation sensors. Experimental results find that, within 3 seconds, a genuine user can be correctly verified 97.15% of the time at a false accept rate of 0.1%.
💡 Research Summary
The paper addresses the growing need for unobtrusive, continuous authentication on smartphones, where traditional explicit methods (passwords, PINs, or one‑time biometrics) are both cumbersome for users and insufficient for detecting post‑login intrusions. The authors propose a passive authentication framework that leverages the rich set of sensors already embedded in modern smartphones. Specifically, they focus on eight dominant modalities—keystroke dynamics, GPS location, accelerometer, gyroscope, magnetometer, linear accelerometer, gravity sensor, and rotation sensor—selected from an overall pool of thirty sensors.
To evaluate their approach, the researchers built a large‑scale dataset by recruiting 37 participants from diverse geographic regions. Over a 15‑day period each participant’s device continuously logged sensor data, resulting in roughly 6.7 million records. The data collection was truly passive: a custom Android app ran in the background, automatically recording sensor streams without requiring any explicit user interaction, except for a soft‑keyboard that captured non‑identifying keystroke timing, pressure, and area information. This dataset is notable for its breadth (30 sensors), depth (multiple weeks per user), and realism (data captured during everyday phone use).
The core of the authentication system is a Siamese Long Short‑Term Memory (LSTM) network trained separately for each modality. During training, pairs of time‑windowed samples are fed into twin LSTM branches that share weights. The network learns to map each sample into a compact embedding space where genuine pairs (same user) are pulled together and impostor pairs (different users) are pushed apart, using a contrastive loss function. By modeling temporal dependencies, the LSTM captures subtle patterns such as typing rhythm, movement micro‑vibrations, and location transition habits that static feature extractors would miss.
At inference time, a sliding window (e.g., 3 seconds) extracts a fresh feature sequence from each sensor stream, passes it through the corresponding Siamese LSTM, and computes a similarity score against the enrolled template for the claimed user. Scores from the eight modalities are then fused by simple summation—a score‑level fusion strategy shown in prior multimodal biometric work to be robust and easy to implement. The summed score is compared against a threshold calibrated to a false accept rate (FAR) of 0.1 %.
Experimental results demonstrate that the proposed system achieves a true accept rate (TAR) of 97.15 % within a 3‑second authentication window at the stringent 0.1 % FAR. Extending the window to 5 seconds raises TAR to 99.80 %, illustrating the trade‑off between latency and accuracy. Moreover, the authors conduct ablation studies that reveal a monotonic improvement in performance as more modalities are fused, confirming the complementary nature of the selected sensors. Compared with prior work—such as Touchalytics (EER ≈ 4 % with touchscreen data), HMOG (EER ≈ 7 % with motion and tap data), and DeepAuth (LSTM on three motion sensors with limited session length)—the presented approach offers superior accuracy, faster decision times, and a more comprehensive multimodal foundation.
The paper also discusses several limitations. The participant pool, while diverse, remains modest (37 users), raising questions about scalability to larger populations. All motion sensors were sampled at 1 Hz, which may miss high‑frequency dynamics that could further improve discrimination. The computational cost of running multiple LSTM networks on a mobile device is not quantified, leaving open the issue of battery impact and real‑time feasibility. Finally, although the system stores only embeddings after enrollment, the initial data collection still involves raw sensor streams, which could raise privacy concerns if not handled correctly.
Future research directions suggested include expanding the dataset to thousands of users across iOS and Android platforms, optimizing the Siamese architecture for on‑device inference (e.g., model pruning, quantization, or using lightweight recurrent cells), integrating privacy‑preserving techniques such as differential privacy or homomorphic encryption for embedding transmission, and evaluating the system under varied real‑world conditions (e.g., while walking, driving, or in noisy environments).
In summary, this work introduces a novel, multimodal, Siamese‑LSTM based passive authentication framework that achieves high security (97 % TAR at 0.1 % FAR) within a user‑acceptable latency (3 seconds). By exploiting temporal patterns across a broad sensor suite and demonstrating the benefits of score‑level fusion, the paper makes a significant contribution toward continuous, unobtrusive smartphone security.
Comments & Academic Discussion
Loading comments...
Leave a Comment