Orthonormal Embedding-based Deep Clustering for Single-channel Speech Separation
Deep clustering is a deep neural network-based speech separation algorithm that first trains the mixed component of signals with high-dimensional embeddings, and then uses a clustering algorithm to separate each mixture of sources. In this paper, we extend the baseline criterion of deep clustering with an additional regularization term to further improve the overall performance. This term plays a role in assigning a condition to the embeddings such that it gives less correlation to each embedding dimension, leading to better decomposition of the spectral bins. The regularization term helps to mitigate the unavoidable permutation problem in the conventional deep clustering method, which enables to bring better clustering through the formation of optimal embeddings. We evaluate the results by varying embedding dimension, signal-to-interference ratio (SIR), and gender dependency. The performance comparison with the source separation measurement metric, i.e. signal-to-distortion ratio (SDR), confirms that the proposed method outperforms the conventional deep clustering method.
💡 Research Summary
The paper addresses the limitations of the original Deep Clustering (DC) approach for single‑channel speech separation by introducing an orthonormality regularization term that forces the embedding vectors to become mutually orthogonal and unit‑norm. In the standard DC framework, a neural network maps each time‑frequency (T‑F) bin of a mixed signal into a K‑dimensional embedding space; training minimizes the Frobenius distance between the embedding affinity matrix V Vᵀ and the target affinity matrix Y Yᵀ (Eq. 1‑2). Although this encourages embeddings to reflect speaker dominance, it does not explicitly discourage correlation among different embedding dimensions, which can lead to ambiguous clustering and residual permutation errors during inference.
To remedy this, the authors add a penalization term P = ‖VᵀV − I‖²_F (Eq. 3), where I is the K × K identity matrix. This term pushes VᵀV toward the identity, ensuring that each embedding vector is orthogonal to the others and has unit length. The overall loss becomes the sum of the original DC loss and the orthonormality penalty (Eq. 5). By making the embeddings more independent, the subsequent K‑means clustering can separate the T‑F bins more cleanly, reducing the permutation problem that often contaminates the binary masks derived from the clusters.
The network architecture consists of two bidirectional LSTM layers (512 hidden units each) followed by a fully connected layer that outputs the K‑dimensional embeddings. Hyper‑parameters include a tanh activation, dropout of 0.5, Adam optimizer with a learning rate of 1e‑4, and training on ideal binary masks (IBMs) derived from the WSJ0/WSJ1 corpora. Experiments vary the embedding dimension K (20, 30, 40), signal‑to‑interference ratios (SIR) from 3 dB to 15 dB, and speaker gender combinations (same‑gender vs. mixed‑gender).
Results show consistent SDR improvements when the orthonormality penalty is applied. For K = 20, average SDR increased by 0.47 dB; for K = 40, the gain was 0.44 dB. The benefit grows with larger embedding dimensions and higher SIRs, indicating that richer, more orthogonal embeddings are especially helpful when the mixture is less noisy. Mixed‑gender mixtures exhibit larger gains than same‑gender mixtures, likely because gender differences already provide some natural decorrelation, which the penalty further amplifies. Conversely, at very low SIR (3 dB) and small K, the penalty can hurt performance because forcing strict orthogonality may discard useful correlated information needed to separate heavily overlapped speech.
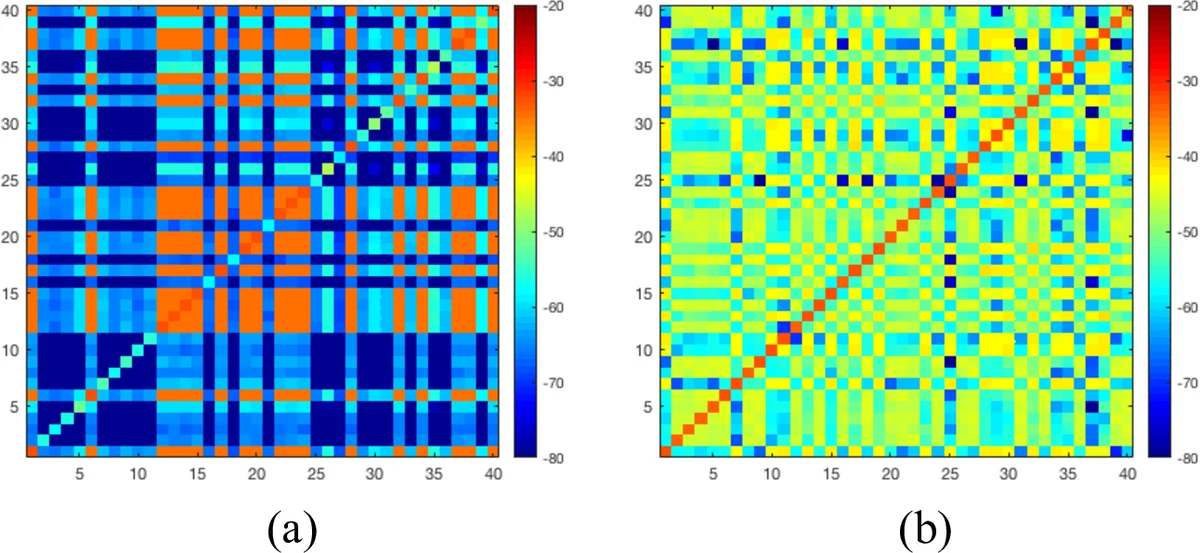
Visualization of the embedding covariance matrices confirms that the baseline DC concentrates variance in a few dimensions, whereas the proposed method distributes variance evenly across all dimensions, reflecting the intended decorrelation. Additional metrics—Improved Normalized Projection Alignment (NPA) and relative error rate—demonstrate that mask quality improves, directly translating to reduced permutation errors.
In summary, the paper presents a straightforward yet effective regularization strategy that enhances deep‑clustering‑based speech separation by encouraging orthonormal embeddings. The approach is validated across multiple experimental conditions and shows particular promise for high‑dimensional embeddings, high SIR scenarios, and gender‑diverse speaker mixtures. Future work will explore applying the same penalty to other embedding‑based separation models such as Deep Attractor Networks, and will investigate adaptive weighting of the penalty to balance orthogonality against necessary correlation in challenging acoustic environments.
Comments & Academic Discussion
Loading comments...
Leave a Comment