Detecting the Trend in Musical Taste over the Decade -- A Novel Feature Extraction Algorithm to Classify Musical Content with Simple Features
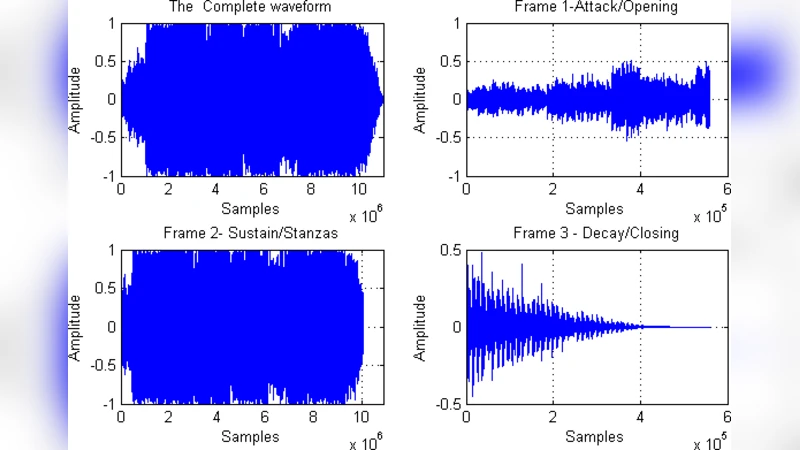
This work proposes a novel feature selection algorithm to classify Songs into different groups. Classification of musical content is often a non-trivial job and still relatively less explored area. The main idea conveyed in this article is to come up with a new feature selection scheme that does the classification job elegantly and with high accuracy but with simpler but wisely chosen small number of features thus being less prone to over-fitting. This uses a very basic general idea about the structure of the audio signal which is generally in the shape of a trapezium. So, using this general idea of the Musical Community we propose three frames to be considered and analyzed for feature extraction for each of the audio signal – opening, stanzas and closing – and it has been established with the help of a lot of experiments that this scheme leads to much efficient classification with less complex features in a low dimensional feature space thus is also a computationally less expensive method. Step by step analysis of feature extraction, feature ranking, dimensionality reduction using PCA has been carried in this article. Sequential Forward selection (SFS) algorithm is used to explore the most significant features both with the raw Fisher Discriminant Ratio (FDR) and also with the significant eigen-values after PCA. Also during classification extensive validation and cross validation has been done in a monte-carlo manner to ensure validity of the claims.
💡 Research Summary
The paper proposes a novel yet conceptually simple feature‑selection pipeline for music classification. It starts from the observation that the amplitude envelope of most songs roughly follows a trapezoidal shape, consisting of three perceptually meaningful sections: an opening (attack), a sustained middle (stanzas), and a closing (decay). The authors therefore segment every audio file into three fixed‑percentage frames (first 5 % as opening, middle 90 % as stanzas, last 5 % as closing) and extract from each frame eight elementary statistical descriptors: mean, variance, skewness, kurtosis, hyper‑skewness, hyper‑flatness, Fano factor, and power spectral density. This yields a total of 24 candidate features per song.
To reduce redundancy and identify the most discriminative descriptors, the authors first compute the raw Fisher Discriminant Ratio (FDR) for each feature, then perform Principal Component Analysis (PCA) and retain the eigen‑vectors with the largest eigen‑values. Both the raw‑FDR and the PCA‑based feature sets are fed into a Sequential Forward Selection (SFS) algorithm, which iteratively builds a compact subset that maximizes classification performance.
The experimental domain is Indian popular music. The authors collect roughly 350 songs from two eras—1985‑1999 (old hits) and 2000‑2014 (contemporary hits)—selected purely on chart popularity, thereby ensuring substantial overlap between the two classes. The dataset is deliberately challenging: the musical styles of the two decades blend heavily, making the classification task non‑trivial.
A battery of twelve supervised classifiers is evaluated: Linear Discriminant Analysis (LDA), Quadratic Discriminant Analysis (QDA), Naïve Bayes, several K‑Nearest Neighbor variants (Euclidean, City‑Block, Cosine, Correlation distances), and Support Vector Machines with linear, polynomial, quadratic, and RBF kernels. For each classifier the authors conduct 500‑fold Monte‑Carlo cross‑validation, reporting accuracy, precision, recall, and F1‑score. The best results are achieved by SVM with an RBF kernel and by LDA, both exceeding 85 % accuracy and approaching 90 % in some configurations. The authors interpret these numbers as evidence that simple statistical features, when extracted from the three envelope‑based frames, are sufficient to capture the evolution of listener taste over a decade.
Strengths of the work include (1) a clear motivation to keep feature extraction computationally cheap, (2) an original framing of the signal into three perceptual sections, (3) thorough use of statistical feature‑ranking (FDR) and dimensionality reduction (PCA) combined with SFS, and (4) extensive validation through large‑scale Monte‑Carlo cross‑validation across many classifiers.
However, several limitations temper the impact. The trapezoidal envelope assumption is only qualitatively illustrated; no quantitative analysis confirms its prevalence across genres or validates the fixed 5 %/90 %/5 % split. The dataset is modest (≈350 tracks) and confined to Indian popular music, raising questions about generalizability to other cultures or larger corpora. The paper does not benchmark against standard audio descriptors such as MFCCs, chroma, or rhythm‑based features, so the claimed superiority of simple statistics remains unproven in a broader context. Moreover, the selected features are not linked to musical semantics, limiting interpretability. Finally, the manuscript suffers from numerous typographical errors and inconsistent terminology, which could hinder reproducibility.
In summary, the study introduces an intriguing “simple statistics + envelope‑based framing” approach that achieves surprisingly high classification performance on a challenging, era‑based Indian music dataset. While the results are promising, future work should (i) rigorously test the envelope hypothesis across diverse music, (ii) compare against established acoustic feature sets, (iii) expand the dataset both in size and genre diversity, and (iv) provide clearer methodological details to facilitate replication.
Comments & Academic Discussion
Loading comments...
Leave a Comment