Expanding the Reach of Federated Learning by Reducing Client Resource Requirements
Communication on heterogeneous edge networks is a fundamental bottleneck in Federated Learning (FL), restricting both model capacity and user participation. To address this issue, we introduce two novel strategies to reduce communication costs: (1) the use of lossy compression on the global model sent server-to-client; and (2) Federated Dropout, which allows users to efficiently train locally on smaller subsets of the global model and also provides a reduction in both client-to-server communication and local computation. We empirically show that these strategies, combined with existing compression approaches for client-to-server communication, collectively provide up to a $14\times$ reduction in server-to-client communication, a $1.7\times$ reduction in local computation, and a $28\times$ reduction in upload communication, all without degrading the quality of the final model. We thus comprehensively reduce FL’s impact on client device resources, allowing higher capacity models to be trained, and a more diverse set of users to be reached.
💡 Research Summary
Federated Learning (FL) enables training a global model across many edge devices without centralizing their private data, but its scalability is hampered by two intertwined system challenges: (1) the downlink (server‑to‑client) transmission of the global model, and (2) the uplink (client‑to‑server) transmission of local updates. While prior work has focused on compressing the uplink, the downlink remains a major bottleneck, especially for high‑capacity models with millions of parameters.
The paper introduces two complementary techniques to shrink the downlink payload and reduce local computation.
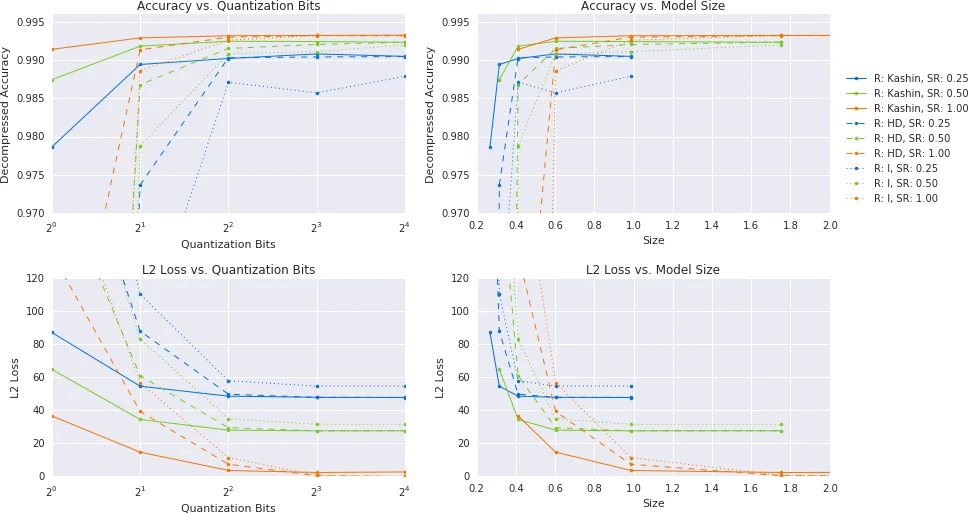
- Lossy compression of the global model – Each weight matrix is flattened into a vector, transformed by a basis (random Hadamard or the theoretically optimal Kashin representation), randomly subsampled, and then quantized (1‑bit or q‑bit uniform probabilistic quantization). The compressed vector is sent to the client, which reverses the transform to obtain a noisy but unbiased version of the original weights. Kashin’s representation spreads information uniformly across dimensions, thereby minimizing quantization error compared with the plain Hadamard transform.
- Federated Dropout – Inspired by dropout, but applied at the system level. The server selects a fixed fraction of activations (for fully‑connected layers) or filters (for convolutional layers) to drop, producing a smaller sub‑model that is sent to each client. Clients train only on this sub‑model; their updates are then mapped back onto the full model on the server. Because the sub‑model has fewer parameters, both the downlink model size and the uplink update size shrink, and the local training requires fewer FLOPs.
Both methods are orthogonal to existing client‑to‑server compression schemes (e.g., Konečný et al., 2016b) and can be combined seamlessly.
Experimental evaluation uses three standard FL benchmarks (MNIST, CIFAR‑10, EMNIST) with convolutional networks of roughly 1 M parameters. The authors vary compression ratios, dropout rates, and basis transforms. Results show up to a 14× reduction in server‑to‑client traffic, a 28× reduction in upload size, and a 1.7× reduction in local computation, all while preserving final test accuracy within a fraction of a percent of the uncompressed baseline. Convergence slows only modestly (a few extra communication rounds).
The significance of the work lies in demonstrating that high‑capacity models can be trained on heterogeneous, bandwidth‑constrained devices without excluding them from participation. Federated Dropout directly lowers memory and energy demands on the client, making FL viable for low‑end phones and regions with poor connectivity. The use of Kashin’s representation provides a principled way to control quantization error in downlink compression, an area previously unexplored.
Future directions suggested include adaptive dropout rates per client, support for heterogeneous model architectures, integration with privacy‑preserving mechanisms (e.g., differential privacy), and exploring the trade‑off between compression‑induced noise and model robustness. Overall, the paper offers a practical, well‑validated toolkit for expanding the reach of federated learning to a broader set of devices and network conditions.
Comments & Academic Discussion
Loading comments...
Leave a Comment