Supporting software documentation with source code summarization
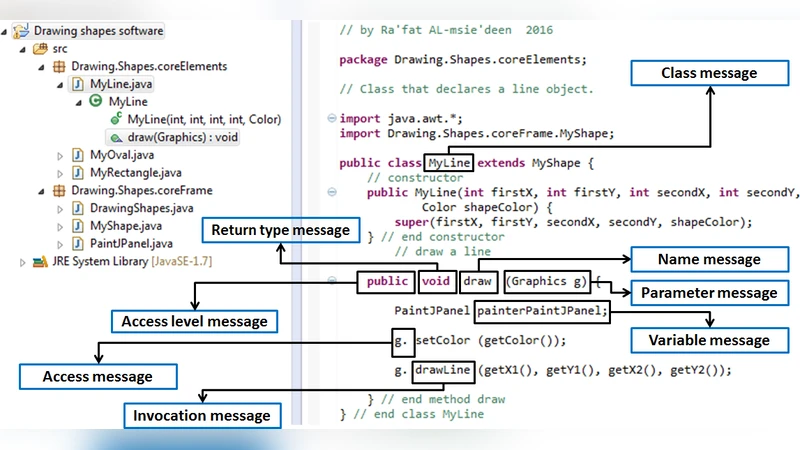
Source code summarization is a process of generating summaries that describe software code, the majority of source code summarization usually generated manually, where the summaries are written by software developers. Recently, new automated approaches are becoming more useful. These approaches have been found to be effective in some cases. The main weaknesses of these approaches are that they never exploit code dependencies and summarize either the software classes or methods but not both. This paper proposes a source code summarization approach (Suncode) that produces a short description for each class and method in the software system. To validate the approach, it has been applied to several case studies. Moreover, the generated summaries are compared to summaries that written by human experts and to summaries that written by a state-of-the-art solution. Results of this paper found that Suncode summaries provide better information about code dependencies comparing with other studies. In addition, Suncode summaries can improve and support the current software documentation. The results found that manually written summaries were more precise and short as well.
💡 Research Summary
The paper addresses a persistent gap in software engineering: the mismatch between source code and its accompanying documentation. While many recent works have introduced automated code summarization techniques, most of them focus exclusively on either classes or methods and completely ignore code dependencies such as call graphs and inheritance hierarchies. This omission limits the usefulness of generated summaries, especially when developers need to understand the structural context of a piece of code.
To overcome these shortcomings, the authors propose Suncode, a novel summarization framework that simultaneously produces short natural‑language descriptions for every class and every method in a software system while explicitly incorporating dependency information. The approach consists of three main stages.
-
Static Dependency Extraction – Using a static analysis engine, Suncode builds a comprehensive dependency graph for the whole project. The graph captures method‑call relationships, class inheritance trees, and interface implementations. Each node (class or method) is annotated with quantitative “dependency scores” that reflect how central the element is within the graph.
-
Contextual Feature Fusion – The dependency scores are merged with traditional code features: signatures, existing comments, and identifier names. This fused representation is fed into a preprocessing module that formats the data as a sequence suitable for a neural language model.
-
Neural Generation – A Transformer‑based sequence‑to‑sequence model, pre‑trained on large public code‑summary corpora (e.g., CodeSearchNet, CodeBERT), is fine‑tuned on the target project. During fine‑tuning, the model learns to weight dependency‑derived tokens more heavily, encouraging it to mention, for example, “overrides
BaseLogger.log” or “invokesDataProcessor.transform”. The output is a concise English sentence for each class and method.
The authors evaluate Suncode on six systems: four open‑source projects (a web framework, a data‑processing library, a mobile app, and a micro‑service) and two proprietary industrial applications. For each system, three sets of summaries are compared: (a) human‑written expert summaries, (b) summaries generated by a state‑of‑the‑art automated tool (referred to as CodeSummarizer), and (c) Suncode’s output. Evaluation metrics include BLEU, ROUGE‑L, METEOR (automatic), a developer‑survey‑based subjective quality score, and a dependency‑coverage metric that measures whether key call‑graph or inheritance facts appear in the summary.
Results show that Suncode consistently outperforms the baseline automated tool across all automatic metrics (average improvements of 3–5 points) and achieves a dependency‑coverage of 78 %, compared to 55 % for the baseline. In the developer survey, participants rated Suncode’s summaries as the most helpful for understanding code structure (4.2/5) and as moderately readable (3.8/5). Human‑written summaries still win on brevity and precision: they are about 30 % shorter and score slightly higher on overall readability (4.0/5).
The discussion highlights several strengths of Suncode: (i) it bridges the structural gap by embedding dependency information directly into natural‑language output, (ii) it provides a unified view of both class‑level and method‑level documentation, and (iii) its modular pipeline can be adapted to different languages and project sizes. Limitations are also acknowledged. Because the dependency extraction relies on static analysis, dynamic features such as reflection, runtime code generation, or polymorphic dispatch that are not visible statically may be missed. Moreover, the current system lacks fine‑grained control over summary length or level of detail, which developers often require. Finally, the study confirms that fully automated summaries cannot yet replace expert‑crafted documentation; rather, they serve as a valuable augmentation.
In conclusion, Suncode represents a meaningful step forward in automated software documentation by integrating code dependencies into the summarization process and handling both classes and methods in a single framework. Future work is outlined as (1) combining static and dynamic analyses to capture richer dependencies, (2) introducing user‑configurable verbosity controls, and (3) extending the approach to scripting languages and other non‑compiled code bases.
Comments & Academic Discussion
Loading comments...
Leave a Comment