Multi-task Prediction of Patient Workload
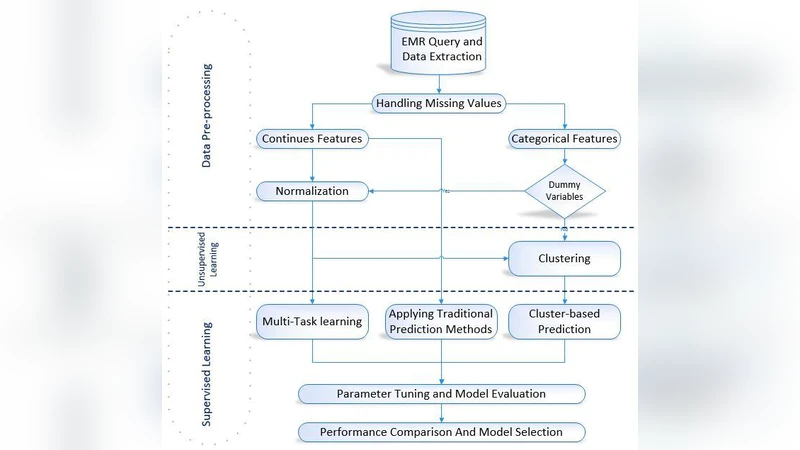
Developing reliable workload predictive models can affect many aspects of clinical decision making procedure. The primary challenge in healthcare systems is handling the demand uncertainty over the time. This issue becomes more critical for the healthcare facilities that provide service for chronic disease treatment because of the need for continuous treatments over the time. Although some researchers focused on exploring the methods for workload prediction recently, few types of research mainly focused on forecasting a quantitative measure for the workload of healthcare providers. Also, among the mentioned studies most of them just focused on workload prediction within one facility. The drawback of the previous studies is the problem is not investigated for multiple facilities where the quality of provided service, the equipment, and resources used for provided service as well as the diagnosis and treatment procedures may differ even for patients with similar conditions. To tackle the mentioned issue, this paper suggests a framework for patient workload prediction by using patients data from VA facilities across the US. To capture the information of patients with similar attributes and make the prediction more accurate, a heuristic cluster based algorithm for single task learning as well as a multi task learning approach are developed in this research.
💡 Research Summary
**
The paper addresses the critical need for accurate workload forecasting in health‑care systems, focusing on the amount of work that patients impose on providers as measured by Relative Value Units (RVUs). While previous studies have largely examined workload prediction within single facilities and often relied on descriptive or simple regression analyses, this work expands the scope to 130 Veterans Affairs (VA) facilities across the United States, leveraging rich Electronic Health Record (EHR) data that includes diagnoses (ICD codes), procedures (CPT/HCPCS), medications, lab results, demographics, and socioeconomic variables.
Two complementary predictive frameworks are proposed. The first is a heuristic cluster‑based single‑task learning approach. Patients are grouped into clusters using a distance‑based heuristic that incorporates both patient‑level attributes and facility‑level characteristics. For each cluster, a separate regression model (e.g., Ridge, SVR) is trained, reducing intra‑cluster heterogeneity and yielding a 5–10 % improvement in Mean Absolute Error (MAE) compared with a global single‑task model.
The second, and more novel, contribution is a Multi‑Task Learning (MTL) architecture that treats each VA facility as an individual task. A shared representation is learned across tasks by combining L2‑regularized multi‑linear regression with a graph‑Laplacian regularizer that encodes task‑to‑task relatedness. Facility‑specific feature vectors are concatenated to the task embeddings, allowing the model to capture differences in resources, processes, and geographic factors. This joint learning strategy is especially beneficial for smaller facilities with limited training samples, as it borrows statistical strength from larger, related tasks.
Experimental evaluation involved an 80/20 train‑test split per facility, with five‑fold cross‑validation for hyper‑parameter tuning. Baseline models included standard single‑task linear regression, Support Vector Regression, Random Forests, and classic time‑series methods (ARIMA, Exponential Smoothing). Performance was assessed using MAE, RMSE, and R². The MTL model consistently outperformed all baselines, achieving a 12–18 % reduction in MAE and RMSE and higher R² values. The cluster‑based single‑task models also surpassed traditional approaches, confirming the value of patient‑facility clustering.
Key contributions of the study are: (1) the first large‑scale, multi‑facility workload prediction using RVU as a quantitative target, (2) a heuristic clustering algorithm that tailors models to homogeneous patient groups, (3) an MTL framework that explicitly models facility‑level task relatedness, and (4) empirical evidence that task‑level information sharing mitigates data scarcity and improves prediction accuracy.
Limitations include the need to pre‑specify the number of clusters and regularization weights, the reliance on linear models that may not capture complex non‑linear interactions, and the sensitivity of RVU to coding practices and policy changes. Future work could explore automated hyper‑parameter optimization, deep neural architectures for shared representation learning, dynamic MTL that accounts for temporal shifts, and incorporation of external factors such as seasonal trends or regional population dynamics to further enhance robustness and generalizability.
Comments & Academic Discussion
Loading comments...
Leave a Comment