Empirical Evaluation of Speaker Adaptation on DNN based Acoustic Model
Speaker adaptation aims to estimate a speaker specific acoustic model from a speaker independent one to minimize the mismatch between the training and testing conditions arisen from speaker variabilities. A variety of neural network adaptation method…
Authors: Ke Wang, Junbo Zhang, Yujun Wang
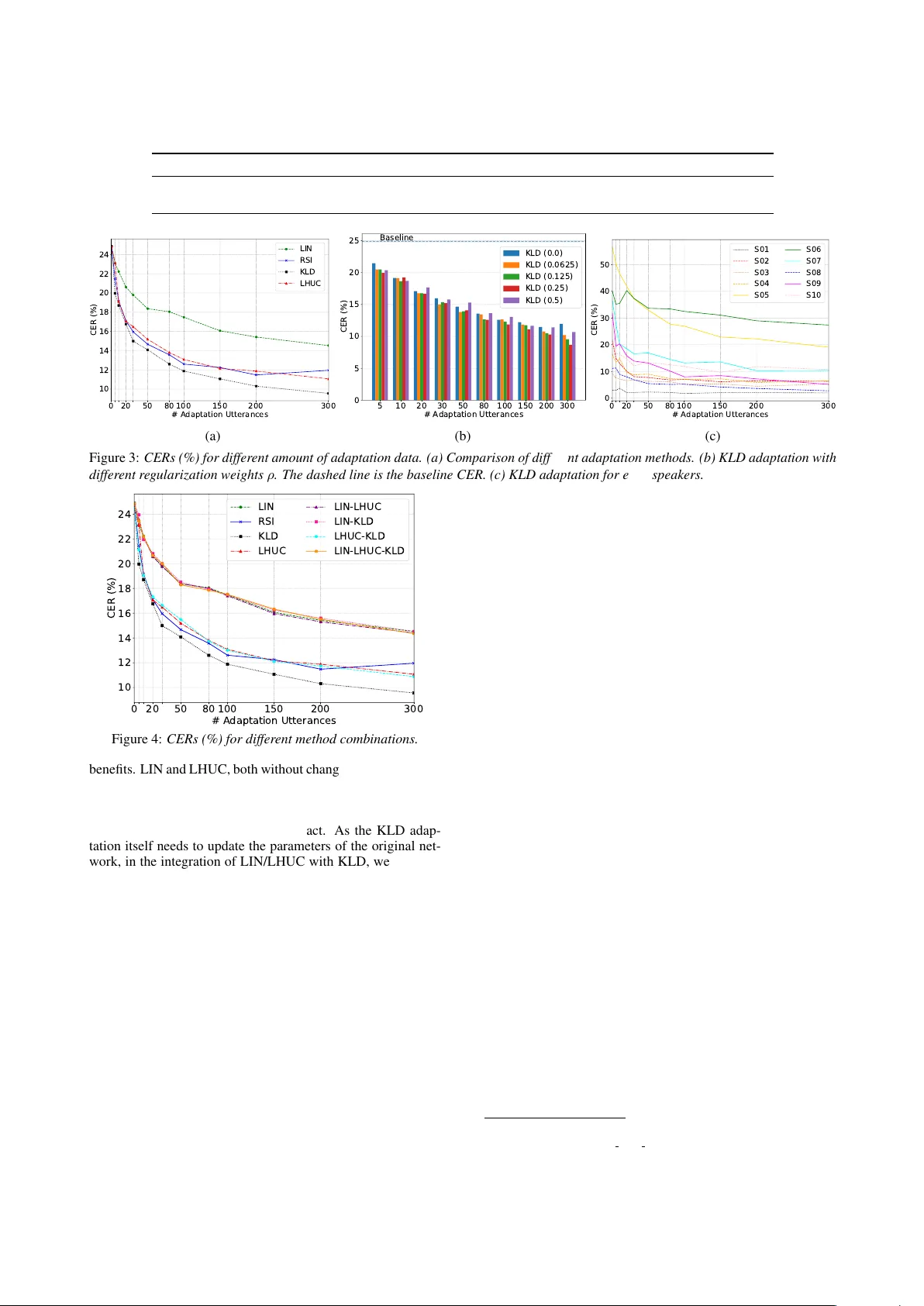
Empirical Evaluation of Speak er Adaptation on DNN based Acoustic Model K e W ang 1 , 2 , J unbo Zhang 2 , Y ujun W ang 2 , Lei Xie 1 ∗ 1 Shaanxi Provincial K e y Laboratory of Speech and Image Information Processing, School of Computer Science, Northwestern Polytechnical Uni versity , Xi’an, China 2 Xiaomi, Beijing, China { kewang, lxie } @nwpu-aslp.org, { zhangjunbo, wangyujun } @xiaomi.com Abstract Speaker adaptation aims to estimate a speaker specific acoustic model from a speaker independent one to minimize the mis- match between the training and testing conditions arisen from speaker v ariabilities. A variety of neural network adaptation methods hav e been proposed since deep learning models have become the main stream. But there still lacks an experimental comparison between different methods, especially when DNN- based acoustic models hav e been advanced greatly . In this pa- per , we aim to close this gap by providing an empirical ev alu- ation of three typical speaker adaptation methods: LIN, LHUC and KLD. Adaptation experiments, with different size of adap- tation data, are conducted on a strong TDNN-LSTM acoustic model. More challengingly , here, the source and target we are concerned with are standard Mandarin speaker model and ac- cented Mandarin speaker model. W e compare the performances of different methods and their combinations. Speaker adapta- tion performance is also examined by speaker’ s accent de gree. Index T erms : Speaker adaptation, deep neural networks, LIN, KLD, LHUC 1. Introduction Speech recognition accuracy has been significantly improved since the use of deep learning models (DLMs), or more specif- ically , deep neural networks (DNNs) [1, 2]. V arious models, such as con volutional neural networks (CNNs) [3, 4], time- delay neural networks (TDNNs) [5], long short-term memory (LSTM) recurrent neural netw orks (RNNs) [6, 7] and their v ari- ants [8, 9] and combinations [10], have been dev eloped to fur- ther improve the performance. Howev er, the accuracy of an automatic speech recognition (ASR) system in real applications still lags behind that in controlled testing conditions. This raises the old and unsolved problem called training-testing mismatch , i.e., the training set cannot match the new acoustic conditions or fails to generalize to new speakers. Thus a v ariety of acous- tic model compensation and adaptation methods ha ve been pro- posed, to better deal with unseen speakers and mismatched acoustic conditions. This study specifically focuses on speaker adaptation , i.e., modifying a general model, commonly a speaker-independent acoustic model (SI AM), to work better for a specific new speaker , though the same adaptation technique can be applied to other mismatched conditions. The history of acoustic model speaker adaptation can be traced back to the GMM-HMM era [11, 12, 13, 14, 15, 16, 17, 18], while the focus has been shifted to neural networks since the rise of DLMs. V arious approaches have been de veloped for neural network acoustic model adaptation [19, 20, 21, 22, 23, 24, 25, 26, 27, 28] and they can be roughly categorized into three classes: speaker-adapted layer insertion, subspace method and direct model adapting. *Corresponding author In the category of speaker -adapted layer insertion, linear transformation, which augments the original network with cer- tain speaker-specific linear layer(s), is a simple-but-effecti ve approach. Common methods include linear input network (LIN) [19, 20], linear hidden network (LHN) [21], and linear output network (LOH) [20], just to name a few . Among them, LIN is the most popular one. Learning hidden unit contribution (LHUC) [22] is another type of speaker -adapted layer insertion method that makes the SI network parameters to be speaker- specific by inserting special layers to control the amplitude of the hidden layers. Another category , subspace method, aims to find a low di- mensional speaker subspace that is used for adaptation. The most straightforward application is to use subspace-based fea- tures, e.g., i-vectors [23, 24], as a supplement of acoustic fea- tures in the neural network for acoustic model training, or speaker adaptive training (SA T). Another approach, serving the same purpose with auxiliary features, is called speaker codes [25]. A specific set of network units for each speaker is connected and optimized with the original SI network. Note that i-vector based SA T has become a standard in the training of deep neural network acoustic models [5, 24, 27, 29, 30, 31] as this simple trick can bring small-but-consistent impro vement. A straightforward idea is to use new speaker’ s data to adapt the DNN parameters directly . Retraining/fine-tuning the SI model using the new data is the simplest way , which is also called retrained speaker independent (RSI) adaptation [19]. T o av oid over -fitting, conservativ e training, such as Kullback- Leibler diver gence (KLD) regularization [26] is further intro- duced. This approach tries to force the posterior distribution of the adapted model to be closer to that estimated from the SI model, by adding a KLD regularization term to the original cross entropy cost function to update the network parameters. Although quite effecti ve, this approach results in an individual neural network for each speaker . T o the best of our knowledge, there still lacks a thor - ough e xperimental comparison between dif ferent speaker adap- tation methods in the literature, especially when the DNN- based acoustic models (AMs) hav e been advanced greatly since the introduction of these adaptation techniques. In this paper , we aim to close this gap by providing an empirical ev alua- tion of three typical speaker adaptation methods: LIN, LHUC and KLD. Adaptation experiments are conducted on a strong TDNN-LSTM acoustic model (well trained i-vector based SA T - DNN acoustic model with cMLLR [13, 15]) tested with differ - ent size of adaptation data. More challengingly , here, the source and target we are concerned with are standard Mandarin speaker model and accented Mandarin speaker model. W e compare the performance of dif ferent methods and their combinations. The speaker adaptation performance is also examined by speaker’ s accent degree. In a word, we w ould like to pro vide readers a big picture on the selection of speaker adaptation techniques. The rest of this paper is organized as follo ws. In Section 2, we briefly introduce LIN, KLD, LHUC and giv e a discussion A c o u s t i c F e at u r e s P o s t e r i o r s In p u t T r an s f o r m Figure 1: Linear input network. on their abilities. Next, we describe a series of e xperiments and report the results in Section 3. Finally , some conclusions are drawn in Section 4. 2. Speaker adaptation algorithms 2.1. LIN Linear input network (LIN) [19, 20] is a classical input trans- formation approach for neural network adaptation. As shown in Figure 1, LIN assumes that the mismatch between training and testing can be captured in the feature space by employ- ing a trainable linear input layer which maps speak er dependent speech to speaker independent network (i.e., acoustic model). The inserted layer usually has the same dimension as the orig- inal input layer and is initialized to an identity weight matrix and 0 bias. Unlike other layers of the neural network, linear activ ation function f ( x ) = x is used for this additional layer . During adaptation, standard error back-propagation (BP) is used to update the LIN’ s parameters while keeping all other net- work parameters fixed, by minimizing the loss function (e.g., cross entropy , mean square error) of the original AM. After adaptation, each speaker -specific LIN captures the relations be- tween the speaker and the training space. Finally , for each test- ing speaker , the corresponding LIN is selected to do feature transformation and the transformed vector is directly fed to the original unadapted AM for speech recognition. 2.2. KLD Regularization As a popular conservati ve training adaptation technique, Kullback-Leibler div ergence (KLD) [26] regularization tries to force the posterior distrib ution of the adapted model to be closer to that estimated from the SI model. By contrast, the L 2 regu- larization aims to keep the parameters of adapted model to be closer to those of the SI model. For acoustic model training, it is typical to minimize the cross entropy (CE) F C E = − 1 N N X t =1 S X y =1 ˜ p ( y | x t ) log p ( y | x t ) , (1) where N is the number of training samples, S is the total num- ber of states, ˜ p ( y | x t ) is the target probability and p ( y | x t ) is neural network’ s output posteriors. W e usually use a hard align- ment from an existing ASR system as the training labels and set ˜ p ( y | x t ) = δ ( y = s t ) , where δ is the Kronecker delta function and s t is the label of t -th sample. By adding the KLD term to Eq. (1) we get the following optimization criterion: b F C E = (1 − ρ ) F C E − ρ 1 N N X t =1 S X y =1 p S I ( y | x t ) log p ( y | x t ) = − 1 N N X t =1 S X y =1 h (1 − ρ ) ˜ p ( y | x t ) + ρp S I ( y | x t ) i log p ( y | x t ) = − 1 N N X t =1 S X y =1 ˆ p ( y | x t ) log p ( y | x t ) , (2) A c o u s t i c F e at u r e s P o s t e r i o r s 𝑟 1 1 𝑟 2 1 𝑟 𝑛 1 𝑟 𝑛 − 1 1 𝑟 1 2 𝑟 2 2 𝑟 3 2 𝑟 𝑚 − 2 2 𝑟 𝑚 − 1 2 𝑟 𝑚 2 𝑟 1 𝐿 𝑟 2 𝐿 𝑟 3 𝐿 𝑟 𝑘 − 2 𝐿 𝑟 𝑘 − 1 𝐿 𝑟 𝑘 𝐿 Figure 2: Learning hidden unit contribution. where ρ is regularization weight and we ha ve defined ˆ p ( y | x t ) , (1 − ρ ) ˜ p ( y | x t ) + ρp S I ( y | x t ) . (3) By comparing Eq. (1) and Eq. (2), we can find that apply- ing KLD is equiv alent to changing the target distribution in the con ventional BP algorithm. When ρ = 0 , we can regard this configuration as RSI, i.e., retraining the SI model directly using the traditional CE loss. 2.3. LHUC As shown in Figure 2, learning hidden unit contrib ution (LHUC) [22] modifies the SI model by defining a set of speaker dependent parameters θ for a specific speaker , where θ = r 1 , · · · , r L and r l is the v ector of speak er dependent param- eters for l -th hidden layer . Then the element-wise function a ( · ) is adopted to constrain the range of r l and the speaker depen- dent hidden layer output can be defined as the following func- tion: h l = a ( r l ) ◦ φ l ( W l > h l − 1 ) , (4) where ◦ is an element-wise multiplication and a ( · ) is typically defined as a sigmoid with amplitude 2, i.e., a ( r l ) , 2 1 + exp( − r l ) , (5) to constrain the range of r ’ s elements to [0 , 2] . LHUC, given adaptation data, actually rescales the contri- butions (amplitudes) of the hidden units in the model without actually modifying their feature receptors. At the training stage, θ is optimized with the standard BP algorithm while keeping all the other parameters fixed for a specific speaker . During the testing stage, the corresponding θ is chosen to constrain the am- plitudes of hidden units in order to get more accurate posterior probability for the speaker . 2.4. Discussion and Combination W e compare the three speaker adaptation approaches in terms of adapted parameter size and modification on the AM. • Size of Adapted Parameters: LHUC has minimal adapted parameters, followed by LIN. For KLD regu- larization, since each speaker has a fully adapted neural network AM, it results in the largest size of adapted pa- rameters. • Modification on AM: In the KLD regularization based adaptation, we do not need to change the original AM network structure, while only changing the loss func- tion. By contrast, we need to adjust the network struc- ture, e.g., inserting layers in the use of LIN and LHUC. Howe ver , we need to take extra burden to find an appro- priate regularization weight ρ in the KLD regularization based adaptation, which is searched through the valida- tion set. The three approaches perform netw ork adaptation from dif- ferent aspects and thus can be integrated to expect some extra T able 1: CERs of each speaker on baseline TDNN-LSTM i-vector based acoustic model. “S”, “M” and “H” are short forms for “slight”, “medium” and “heavy” separately . Speaker S01 S02 S03 S04 S05 S06 S07 S08 S09 S10 A vg Accent S M S M H H H M H M - CER (%) 3 . 00 21 . 63 9 . 09 16 . 40 56 . 62 40 . 07 36 . 61 11 . 16 31 . 74 22 . 28 24 . 86 0 20 50 80 100 150 200 300 # Adaptation Utterances 10 12 14 16 18 20 22 24 CER (%) LIN RSI KLD LHUC (a) 5 10 20 30 50 80 100 150 200 300 # Adaptation Utterances 0 5 10 15 20 25 CER (%) Baseline KLD (0.0) KLD (0.0625) KLD (0.125) KLD (0.25) KLD (0.5) (b) 0 20 50 80 100 150 200 300 # Adaptation Utterances 0 10 20 30 40 50 CER (%) S01 S02 S03 S04 S05 S06 S07 S08 S09 S10 (c) Figure 3: CERs (%) for differ ent amount of adaptation data. (a) Comparison of differ ent adaptation methods. (b) KLD adaptation with differ ent re gularization weights ρ . The dashed line is the baseline CER. (c) KLD adaptation for each speakers. 0 20 50 80 100 150 200 300 # Adaptation Utterances 10 12 14 16 18 20 22 24 CER (%) LIN RSI KLD LHUC LIN-LHUC LIN-KLD LHUC-KLD LIN-LHUC-KLD Figure 4: CERs (%) for differ ent method combinations. benefits. LIN and LHUC, both without changing the parameters of the original SI network, can be directly integrated. In other words, LIN’ s parameters and the speaker dependent parameters θ are updated using the target speaker’ s data while keeping the parameters of the original network intact. As the KLD adap- tation itself needs to update the parameters of the original net- work, in the integration of LIN/LHUC with KLD, we only use Eq. (2) as the loss function to update LIN’ s parameters or/and the speaker dependent parameters θ while still keeping the orig- inal SI network parameters unchanged. 3. Experiments 3.1. Experimental setup In the experiments, we used a Mandarin corpus that consists of 3,000 speaker (about 1000hrs) with standard accent to build a baseline TDNN-LSTM AM. Before NN model training, the alignments were achiev ed from a GMM-HMM AM, combined with fMLLR, trained using the same dataset. Our speaker adap- tation dataset consists of 10 Mandarin speakers from Hubei Province of China and each speaker contributes 450 utterances (about 0.5hr/speaker). Note that the 10 speakers hav e dif ferent lev els of accents and we expect that a good speaker adaptation technique should handle different lev els of accents. W e ran- domly selected 50 utterances as the cross validation set, 100 utterances as the test set and the others as the training set. In the adaptation experiments, we v aried the number of training utter- ances from 5 to 300 to observe the performances of different data size. For the baseline SI acoustic model, 40-dimensional Mel filter-bank cepstral coefficients (MFCCs) spliced with 2 left, 2 right frames and 100-dimensional i-vector , further transformed to 300-dimension with linear discriminate analysis (LDA), were used as the network input. The output softmax layer has 5,795 units representing senones. Moreover , the TDNN-LSTM model has 6 TDNN layers (520 neurons) and 3 LSTMP layers [6] (520 cells with 130 recurrent nodes and 130 non-recurrent nodes). Network training started from an initial learning rate of 0.0003 1 . A trigram language model (LM) was used in ev al- uating both the baseline and the adapted models. Moreov er , all of our experiments were based on Kaldi [32]. 3.2. Results of Baseline Model T able 1 sho ws the character error rate (CER) for each speakers, tested with the baseline AM. W e can see that the baseline model performs differently for each speaker and the average CER is 24.86%. The CER has a wide range from 3% to 56.62%. W e manually checked the recordings from different speakers and found that speaker S05 had heavy accent and speaker S01 had slight Mandarin accent. This huge difference giv es the speaker adaptation methods a big challenge. W e will report the adapta- tion results in terms of accent lev els later in Section 3.5. 3.3. Comparison of LIN, RSI, KLD and LHUC W e inv estigated the adaptation ability of LIN, RSI, KLD and LHUC using different amount of adaptation data. Previous studies on LHUC [22] have demonstrated that adapting more layers in the network can get continuously better accuracy . Hence we inserted LHUC parameters after each hidden lay- ers. For LIN, models were adapted with a small learning rate of 0.00001, while 0.001 and 0.01 were used as an initial learn- ing rate for KLD and LHUC, respectiv ely . From the results shown in Figure 3a, we can see that KLD achie ves the best per - formance and is more stable than RSI on different amount of 1 More details about this architecture can be found in Kaldi: egs/wsj/s5/local/nnet3/run tdnn lstm.sh 0 20 50 80 100 150 200 300 # Adaptation Utterances 2.5 3.0 3.5 4.0 4.5 5.0 5.5 6.0 CER (%) LIN RSI KLD LHUC (a) Slight Accent 0 20 50 80 100 150 200 300 # Adaptation Utterances 6 8 10 12 14 16 18 CER (%) LIN RSI KLD LHUC (b) Medium Accent 0 20 50 80 100 150 200 300 # Adaptation Utterances 15 20 25 30 35 40 CER (%) LIN RSI KLD LHUC (c) Heavy Accent Figure 5: CERs (%) for differ ent methods on differ ent degr ees of accent. adaptation data for all speakers. LIN, as simple layer-insertion method, is also helpful, but its performance is not as good as the other two. For RSI and LHUC, their performances are com- parable in most cases, but o ver -fitting is occurred for RSI when the adaptation data size exceeds 200. Furthermore, similar with [26], we gav e a deep in vestiga- tion on KLD-based adaptation and results are shown in Fig- ure 3b. First, unlike the results in [26], where using small amount of data (5 or 10 utterances) for KLD adaptation is un- fortunately harmful, we still can obtain apparent CER reduction when the same size of data are used for adaptation. W e belie ve that this is because our testing speakers have noticeable accents, i.e., the difference between the SI data and the target speaker data is significant. The comparison of different ρ in the range of [0 . 0625 , 0 . 5] also indicates that reasonable CER reduction can be obtained ev en with a small ρ for different size of adaptation data. The figure also clearly shows that a medium regularization weight (e.g., 0.25) is preferred for larger and smaller adaptation sets and a smaller regularization weight (e.g., 0.0625) is bet- ter used for medium size of adaptation set. W e also compared the performances between dif ferent speakers. Results from Fig- ure 3c shows that KLD works for ev ery testing speaker and the speaker with highest CER on the SI model ( i.e., S5, with the heaviest accent) achiev es the largest CER reduction. But with the increase of adaptation data, the gain on each speaker be- comes smaller and smaller . 3.4. Combinations W e further experimented on method combinations and results are summarized in Figure 4. W e can see the combinations of different methods cannot bring salient improv ements and the best performance is achiev ed by KLD only . Even badly , any combination with LIN will drag the performance to LIN. Com- bining LHUC with KLD can obtain slightly better result than the vanilla LHUC for very small (less than 10) and large (more than 200) adaptation dataset. But for small adaptation data size (20 ∼ 80), LHUC itself performs better . 3.5. Different degr ees of accent As shown in T able 1 earlier , the baseline AM’ s performance varies on different speakers. It’ s necessary to compare different adaptation methods in terms of accent le vel. W e manually cate- gorized the 10 speakers into 3 accented groups: slight, medium and heavy according to their performances on the baseline AM in T able 1. According to the accent lev el, results are summa- rized in Figure 5a (slight), Figure 5b (medium) and Figure 5c (heavy). From Figure 5a, we can see that LHUC performs con- sistently the best for the adaptation on slight-accent speakers, while KLD and RSI are not stable. W e believe that this is be- cause the baseline model is trained using data mostly from Man- darin speakers with standard accent and the baseline model it- self is robust enough; in this case, direct update on the network parameters may be harmful. Observing Figure 5b, for medium- accent speakers, we can see that KLD and LHUC can get com- parable performances with much lower CER than LIN. RSI is still not stable and ov er-fitting happens when a lar ge adaptation data set is used. If memory footprint is a major consideration, we suggest to use LHUC as its has a small set of adapted param- eters for each speaker; otherwise LHUC and KLD can be both considered for medium-accent speakers. As shown in Figure 5c, for heavy-accent speakers, KLD can get absolutely the best per- formance among the three methods, followed by LHUC, while LIN still performs the worst. W e believe that KLD’ s superior performance is because the posterior distrib ution of the heavy- accent speech is far away from that of the unaccented speech; in this case, directly updating the network parameters or dragging the two distributions closer, is the most effectiv e means. This also clarifies why RSI is better than LHUC and why we cannot observe o ver -fitting in this condition. 4. Conclusions In this work, we have systematically compared the perfor- mance of three widely-used speaker adaptation methods on a challenging dataset with accented speakers. W e show that i- vector based SA T -DNN AM is already strong enough to slight- accent speakers but performs badly to medium- and heavy- accent speakers. By using LIN, KLD, LHUC, we can fur- ther improve the speech recognition performance not only for medium- and heavy-accent speakers, but also for slight-accent speakers. Moreover , the experimental results sho w that, in gen- eral, KLD and LHUC consistently outperform LIN and KLD demonstrates the best performance. The combination of differ- ent methods cannot bring salient improvements. For the adap- tation on slight-accent speakers, LHUC is preferred with con- sistent improvement, while KLD and RSI are not stable. For medium-accent speakers, KLD and LHUC can get compara- ble performances with much lo wer CER than LIN. For heavy- accent speakers, KLD can get absolutely the best performance, followed by LHUC, while LIN still performs the w orst. 5. Acknowledgements The authors would like to thank Jian Li, Mengfei W u and Y ongqing W ang for their supports on this work. The re- search work is supported by the National Key Research and Dev elopment Program of China (Grant No.2017YFB1002102) and the National Natural Science Foundation of China (Grant No.61571363). 6. References [1] G. E. Dahl, D. Y u, L. Deng, and A. Acero, “Context-dependent pre-trained deep neural networks for large-vocabulary speech recognition, ” IEEE T ransactions on audio, speech, and language pr ocessing , vol. 20, no. 1, pp. 30–42, 2012. [2] G. Hinton, L. Deng, D. Y u, G. E. Dahl, A. R. Mohamed, N. Jaitly , A. Senior, V . V anhoucke, P . Nguyen, T . N. Sainath et al. , “Deep neural netw orks for acoustic modeling in speech recognition: The shared views of four research groups, ” IEEE Signal Processing Magazine , vol. 29, no. 6, pp. 82–97, 2012. [3] O. Abdel-Hamid, A. R. Mohamed, H. Jiang, and G. Penn, “ Ap- plying con volutional neural networks concepts to hybrid nn-hmm model for speech recognition, ” in IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing , 2012, pp. 4277– 4280. [4] O. Abdel-Hamid, L. Deng, and D. Y u, “Exploring con volutional neural network structures and optimization techniques for speech recognition. ” in Interspeech , v ol. 2013, 2013, pp. 1173–5. [5] V . Peddinti, D. Povey , and S. Khudanpur, “ A time delay neural network architecture for efficient modeling of long temporal con- texts, ” in Sixteenth Annual Conference of the International Speech Communication Association , 2015. [6] H. Sak, A. Senior, and F . Beaufays, “Long short-term memory based recurrent neural network architectures for large vocabulary speech recognition, ” arXiv preprint , 2014. [7] H. Sak, A. Senior, K. Rao, and F . Beaufays, “Fast and accurate recurrent neural network acoustic models for speech recognition, ” arXiv preprint arXiv:1507.06947 , 2015. [8] Y . Zhang, G. Chen, D. Y u, K. Y aco, S. Khudanpur , and J. Glass, “Highway long short-term memory rnns for distant speech recog- nition, ” in Acoustics, Speech and Signal Processing (ICASSP), 2016 IEEE International Confer ence on . IEEE, 2016, pp. 5755– 5759. [9] S. Zhang, C. Liu, H. Jiang, S. W ei, L. Dai, and Y . Hu, “Feed- forward sequential memory networks: A new structure to learn long-term dependency , ” arXiv pr eprint arXiv:1512.08301 , 2015. [10] T . N. Sainath, O. V inyals, A. Senior, and H. Sak, “Conv olutional, long short-term memory , fully connected deep neural networks, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2015 IEEE International Conference on . IEEE, 2015, pp. 4580–4584. [11] P . C. W oodland, “Speaker adaptation for continuous density hmms: A re view , ” 2001. [12] J. L. Gauvain and C. H. Lee, “Maximum a posteriori estimation for multi variate gaussian mixture observations of marko v chains, ” IEEE T ransactions on Speech and Audio Processing , vol. 2, no. 2, pp. 291–298, 1994. [13] C. J. Legetter and P . C. W oodland, “Maximum likelihood linear regression speaker adaptation of continuous density hmms, ” Com- puter Speech and Language , 1995. [14] V . V . Digalakis, D. Rtischev , and L. G. Neumeyer , “Speaker adap- tation using constrained estimation of gaussian mixtures, ” IEEE T ransactions on Speech and A udio Pr ocessing , vol. 3, no. 5, pp. 357–366, 1995. [15] M. J. F . Gales, “Maximum likelihood linear transformations for hmm-based speech recognition, ” Computer Speech and Lan- guage , v ol. 12, no. 2, p. 7598, 1998. [16] ——, “Cluster adaptiv e training of hidden markov models, ” Speech and Audio Processing IEEE Tr ansactions on , vol. 8, no. 4, pp. 417–428, 2000. [17] R. Kuhn, J. C. Junqua, P . Nguyen, and N. Niedzielski, “Rapid speaker adaptation in eigen voice space, ” IEEE Tr ans Speech Au- dio Pr oc , vol. 8, no. 6, pp. 695–707, 2000. [18] L. F . Uebel and P . C. W oodland, “ An in vestigation into vocal tract length normalisation, ” in Eur opean Confer ence on Speech Com- munication and T echnolo gy , Eur ospeech 1999, Budapest, Hun- gary , September , 1999. [19] J. Neto, L. Almeida, M. Hochberg, C. Martins, L. Nunes, S. Re- nals, and T . Robinson, “Speaker-adaptation for hybrid hmm-ann continuous speech recognition system, ” in F ourth Eur opean Con- fer ence on Speech Communication and T echnology , 1995. [20] B. Li and K. C. Sim, “Comparison of discriminativ e input and out- put transformations for speaker adaptation in the hybrid nn/hmm systems, ” in Eleventh Annual Conference of the International Speech Communication Association , 2010. [21] R. Gemello, F . Mana, S. Scanzio, P . Laface, and R. De Mori, “Linear hidden transformations for adaptation of hybrid ann/hmm models, ” Speech Communication , v ol. 49, no. 10-11, pp. 827–835, 2007. [22] P . Swietojanski and S. Renals, “Learning hidden unit contri- butions for unsupervised speaker adaptation of neural network acoustic models, ” in Spoken Language T echnology W orkshop (SLT), 2014 IEEE . IEEE, 2014, pp. 171–176. [23] G. Saon, H. Soltau, D. Nahamoo, and M. Picheny , “Speaker adaptation of neural network acoustic models using i-vectors. ” in ASR U , 2013, pp. 55–59. [24] Y . Miao, H. Zhang, and F . Metze, “Speaker adaptiv e train- ing of deep neural network acoustic models using i-vectors, ” IEEE/ACM T ransactions on Audio, Speech and Language Pro- cessing (T ASLP) , vol. 23, no. 11, pp. 1938–1949, 2015. [25] O. Abdel-Hamid and H. Jiang, “Fast speaker adaptation of hy- brid nn/hmm model for speech recognition based on discrimina- tiv e learning of speaker code, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2013 IEEE International Conference on . IEEE, 2013, pp. 7942–7946. [26] D. Y u, K. Y ao, H. Su, G. Li, and F . Seide, “Kl-div ergence reg- ularized deep neural network adaptation for improved large vo- cabulary speech recognition, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2013 IEEE International Conference on . IEEE, 2013, pp. 7893–7897. [27] A. Senior and I. Lopez-Moreno, “Improving dnn speaker inde- pendence with i-vector inputs, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2014 IEEE International Conference on . IEEE, 2014, pp. 225–229. [28] Z. Huang, S. M. Siniscalchi, and C.-H. Lee, “Bayesian unsuper- vised batch and online speaker adaptation of activation function parameters in deep models for automatic speech recognition, ” IEEE/ACM T ransactions on Audio, Speech, and Language Pr o- cessing , vol. 25, no. 1, pp. 64–75, 2017. [29] G. Saon, H.-K. J. Kuo, S. Rennie, and M. Picheny , “The ibm 2015 english con versational telephone speech recognition sys- tem, ” arXiv preprint , 2015. [30] D. Pove y , V . Peddinti, D. Galvez, P . Ghahremani, V . Manohar , X. Na, Y . W ang, and S. Khudanpur , “Purely sequence-trained neu- ral networks for asr based on lattice-free mmi. ” in Interspeech , 2016, pp. 2751–2755. [31] W . Xiong, J. Droppo, X. Huang, F . Seide, M. Seltzer, A. Stolcke, D. Y u, and G. Zweig, “The microsoft 2016 conversational speech recognition system, ” in Acoustics, Speech and Signal Processing (ICASSP), 2017 IEEE International Conference on . IEEE, 2017, pp. 5255–5259. [32] D. Povey , A. Ghoshal, G. Boulianne, L. Burget, O. Glembek, N. Goel, M. Hannemann, P . Motlicek, Y . Qian, P . Schwarz et al. , “The kaldi speech recognition toolkit, ” in IEEE 2011 workshop on automatic speech recognition and understanding , no. EPFL- CONF-192584. IEEE Signal Processing Society , 2011.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment