Machine Learning in Official Statistics
In the first half of 2018, the Federal Statistical Office of Germany (Destatis) carried out a “Proof of Concept Machine Learning” as part of its Digital Agenda. A major component of this was surveys on the use of machine learning methods in official statistics, which were conducted at selected national and international statistical institutions and among the divisions of Destatis. It was of particular interest to find out in which statistical areas and for which tasks machine learning is used and which methods are applied. This paper is intended to make the results of the surveys publicly accessible.
💡 Research Summary
The paper reports on the “Proof of Concept Machine Learning” project carried out by the Federal Statistical Office of Germany (Destatis) in the first half of 2018 as part of its Digital Agenda. The central aim was to assess the current use of machine‑learning (ML) techniques across national and international statistical institutions and within Destatis itself, in order to identify promising application areas, the methods and software employed, and the stages of the statistical production process where ML is applied.
Methodology
Two large‑scale surveys were designed. The first targeted the 14 German Länder statistical offices and 18 additional German authorities (ONAs). A structured Excel questionnaire asked for project name, brief description, statistical application (e.g., classification, regression, clustering), project status (productive, development, experiment, idea), ML method(s) used (Decision Tree, Random Forest, SVM, Neural Networks, etc.), software (R, Python, SAS, etc.) and any publicly available documentation. All 32 institutions responded.
The second survey was sent to statistical offices of the 27 EU member states, the four EFTA countries, six non‑European countries (Australia, Canada, Israel, Japan, New Zealand, United States) and to international organisations such as Eurostat, OECD and UNIDO. Only 21 institutions replied, providing a total of 36 international projects.
In addition, an internal “in‑house” questionnaire was distributed to all 29 divisions of Destatis on 9 May 2018; every division responded, yielding further information on internal ML initiatives.
Results – Scope and Status
Across all sources, 72 ML projects were identified (36 domestic, 36 international). Project status distribution was: 21 (≈29 %) already in productive use, 28 (≈39 %) in development for production, 61 (≈85 %) in experimental testing, and 26 (≈36 %) still at the idea stage. The high proportion of experimental projects indicates that ML is still largely exploratory in official statistics, yet a substantial number of applications have moved into operational use.
Methods and Software
Decision‑tree based techniques (Decision Tree, Random Forest, Gradient Boosting, etc.) were the most common, appearing in 31 of 59 method mentions (≈52 %). Neural networks and Support Vector Machines each accounted for 22 mentions (≈37 %). “Other” methods (k‑Nearest Neighbour, Bayesian approaches, etc.) were also reported. R and Python were the dominant programming environments; some offices also used SAS, SPSS or Stata.
Application Types
The most frequent application categories were classification (19 mentions) and identification (11 mentions), followed by clustering (6), text analysis (9) and regression (4). Classification and identification together represent more than half of all reported uses, reflecting the need for automated labeling in micro‑data linkage, labor‑market region classification, unemployment‑duration prediction, and similar tasks.
Statistical Domains
International responses showed that ML projects span virtually all statistical domains: labor market (26 projects), household statistics (15), business statistics (14), agricultural statistics (10), census (8), price statistics (5), traffic statistics (4) and many cross‑statistical (26) initiatives that can be reused across domains.
GSBPM Mapping
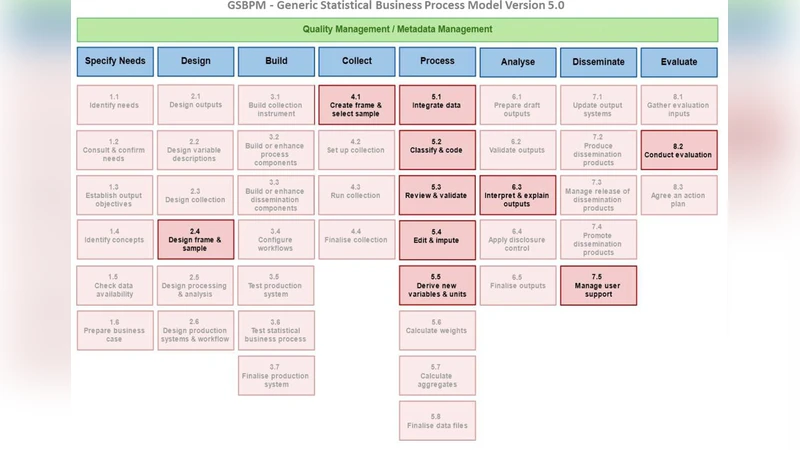
When mapped onto the Generic Statistical Business Process Model (GSBPM), ML activities were primarily located in the “Data Acquisition”, “Data Preparation” and “Result Analysis” sub‑processes. A smaller number of projects also touched “Statistical Conceptualisation”, “User Service” and “Evaluation”. This demonstrates that ML is not limited to post‑processing but can support the entire statistical production pipeline.
Country‑Specific Findings
Canada’s statistical agency reported the largest number of projects (36), followed by the Netherlands (16) and the U.S. Bureau of Labor Statistics (11). Within Germany, only five of the 36 domestic projects were in productive use; most focused on imputation of missing working‑time data, prediction of unemployment duration, and classification of labor‑market regions at the Institute for Employment Research (IAB). The German Central Bank contributed five projects, while the Federal Office for Migration and Refugees (BAMF), GESIS, the Robert Koch Institute (RKI) and the Centre for European Economic Research (ZEW) also reported multiple initiatives.
Key Insights and Limitations
- Algorithm Preference – Tree‑based methods dominate due to interpretability, ease of implementation, and scalability. Neural networks are preferred for high‑dimensional or unstructured data (e.g., text, images).
- Project Maturity – A large share of projects remain experimental; transitioning successful pilots to production requires dedicated resources, governance structures, and clear evaluation criteria.
- Data Privacy – Official statistics must safeguard personal data; the adoption of privacy‑preserving ML techniques (e.g., differential privacy, secure multiparty computation) and model explainability is essential.
- Documentation and Standardisation – The “Machine Learning Documentation Initiative” provides a framework for recording metadata, code, model performance and data flows, which is crucial for reproducibility and international collaboration.
- Survey Coverage – Low response rates from several international offices (e.g., Bulgaria, Greece, Malta) limit the completeness of the global picture. Moreover, the surveys focused on quantitative descriptors, leaving out detailed performance metrics and cost‑benefit analyses.
Conclusion
The study offers the first systematic overview of ML adoption in official statistics across a broad set of national and international agencies. It confirms that ML is increasingly embedded in statistical production, especially for classification, identification, imputation and clustering tasks, and that decision‑tree ensembles, neural networks and SVMs are the workhorses. To fully realise the potential of ML, statistical offices need to strengthen project management, invest in privacy‑preserving technologies, and adopt standardized documentation practices. Continued international cooperation will be pivotal for sharing best practices, harmonising methodologies, and ensuring that ML‑enhanced statistics remain transparent, reliable and fit for policy‑making.
Comments & Academic Discussion
Loading comments...
Leave a Comment