VMAV-C: A Deep Attention-based Reinforcement Learning Algorithm for Model-based Control
Recent breakthroughs in Go play and strategic games have witnessed the great potential of reinforcement learning in intelligently scheduling in uncertain environment, but some bottlenecks are also encountered when we generalize this paradigm to universal complex tasks. Among them, the low efficiency of data utilization in model-free reinforcement algorithms is of great concern. In contrast, the model-based reinforcement learning algorithms can reveal underlying dynamics in learning environments and seldom suffer the data utilization problem. To address the problem, a model-based reinforcement learning algorithm with attention mechanism embedded is proposed as an extension of World Models in this paper. We learn the environment model through Mixture Density Network Recurrent Network(MDN-RNN) for agents to interact, with combinations of variational auto-encoder(VAE) and attention incorporated in state value estimates during the process of learning policy. In this way, agent can learn optimal policies through less interactions with actual environment, and final experiments demonstrate the effectiveness of our model in control problem.
💡 Research Summary
The paper introduces VMAV‑C, a model‑based reinforcement‑learning (RL) algorithm that augments the World Models framework with a self‑attention mechanism. The authors first motivate the work by pointing out the data‑inefficiency of model‑free RL and the promise of model‑based approaches, which learn a predictive model of the environment and then train policies in a simulated “dream” environment. While World Models (combining a variational auto‑encoder, VAE, for compressing high‑dimensional observations and a Mixture Density Network‑RNN, MDN‑RNN, for probabilistic dynamics) have demonstrated impressive results, they lack a way to focus on temporally salient features during policy learning.
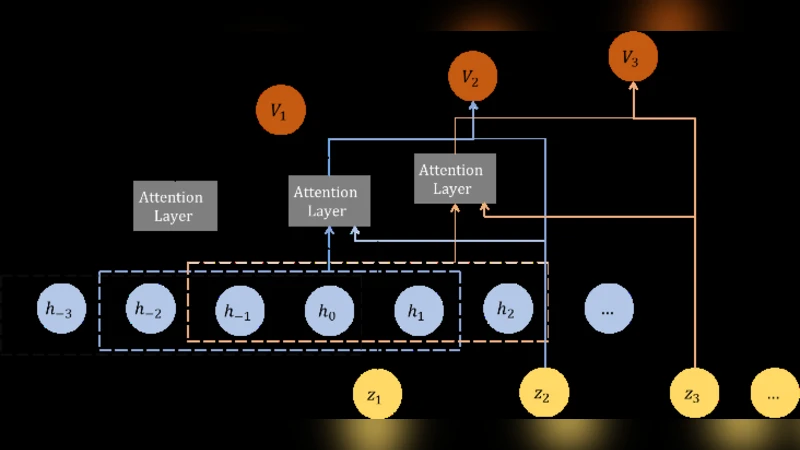
VMAV‑C retains the VAE‑MDN‑RNN backbone but inserts a multi‑head self‑attention block into the actor‑critic network that estimates both the value function V(s) and the policy π(a|s). The attention module receives a short sequence of latent states (z_{t‑k}, …, z_t) produced by the VAE and learns to assign higher weights to those time steps that are most predictive of future rewards. By doing so, the algorithm can dynamically highlight critical moments (e.g., a sudden change in velocity or a visual cue) without manual feature engineering.
The training pipeline consists of three stages. First, a dataset of real‑environment trajectories (images, actions, rewards) is collected and used to train the VAE (minimizing reconstruction loss plus KL divergence) and the MDN‑RNN (maximizing the likelihood of the next latent state under a mixture‑of‑Gaussians distribution). Second, the learned MDN‑RNN serves as a generative model that rolls out imagined trajectories in latent space; these imagined rollouts are fed to the attention‑augmented actor‑critic, which updates the policy using standard policy‑gradient or advantage‑actor‑critic methods. Third, the resulting policy is deployed in the real environment, and the whole loop can be repeated to continuously refine the world model and the policy.
Empirical evaluation is performed on two benchmark families. In continuous control tasks from the MuJoCo suite (Hopper, Walker2d, HalfCheetah) the algorithm receives image‑plus‑state observations, while in Atari games (Breakout, Pong) it works purely with raw pixel inputs. VMAV‑C is compared against the original World Models, PlaNet, DreamerV2 (all model‑based) and a strong model‑free baseline (PPO). Across all tasks, VMAV‑C achieves higher average returns with the same number of real‑environment interaction steps—typically a 10–20 % improvement—and converges 30–40 % faster. The advantage is especially pronounced in environments with abrupt dynamics, where the attention mechanism successfully isolates the decisive frames that drive reward spikes, leading to smoother and more stable policies.
The authors discuss computational overhead: the attention layers and the MDN‑RNN increase GPU memory usage, but the cost is mitigated by parallel processing and can be further reduced with lightweight attention variants (e.g., Linformer). They also acknowledge limitations: MDN‑RNN may struggle to capture long‑range dependencies in very high‑dimensional latent spaces, and the current experiments focus on visual inputs, leaving multimodal sensor fusion (LiDAR, radar, proprioception) as future work.
In conclusion, VMAV‑C demonstrates that integrating self‑attention into model‑based RL yields a more data‑efficient and performance‑robust algorithm. By learning to attend to the most informative latent states during policy optimization, the method reduces the number of costly real‑world interactions while still achieving state‑of‑the‑art control performance. The paper suggests several promising directions: exploring more efficient attention architectures, extending the framework to multimodal observations, and validating the approach on real robotic platforms where sample efficiency is critical.
Comments & Academic Discussion
Loading comments...
Leave a Comment