Graph Transformation Policy Network for Chemical Reaction Prediction
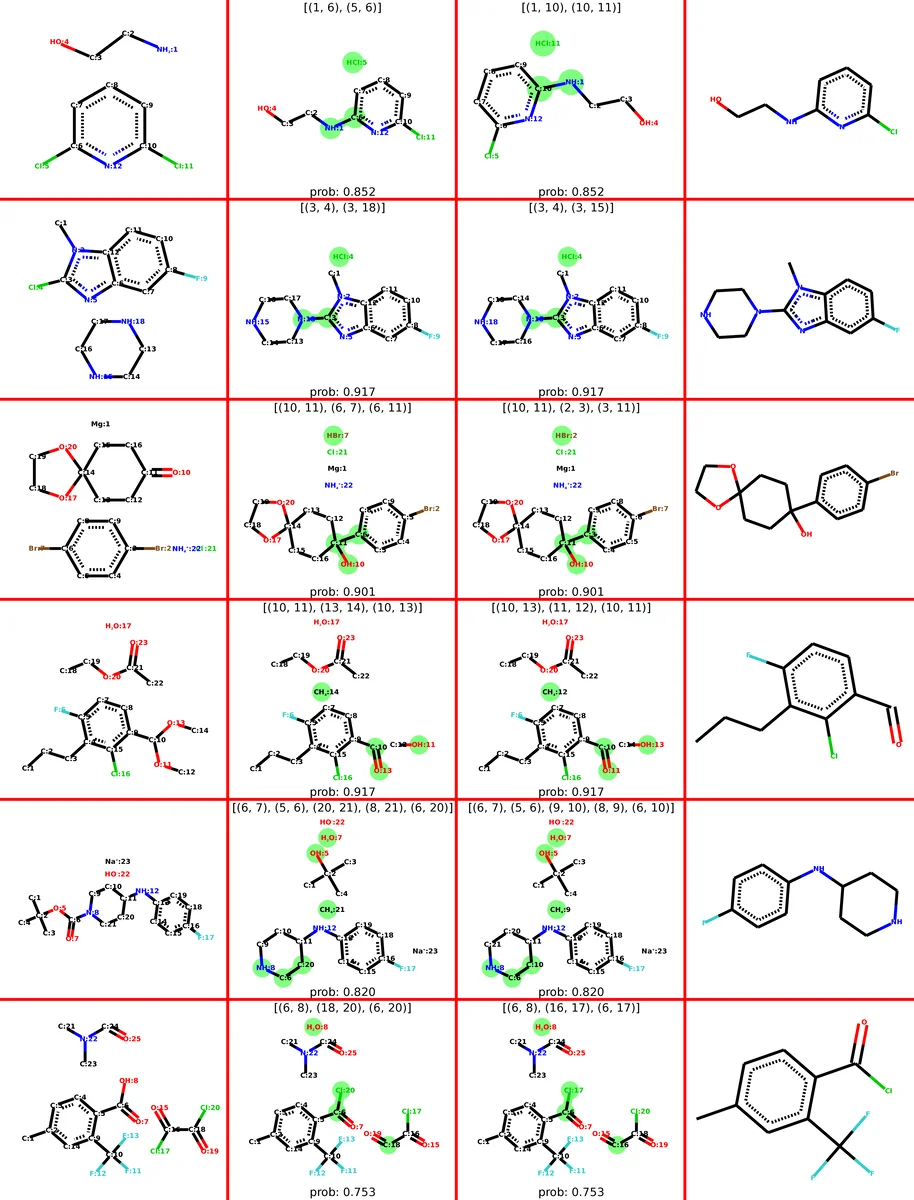
We address a fundamental problem in chemistry known as chemical reaction product prediction. Our main insight is that the input reactant and reagent molecules can be jointly represented as a graph, and the process of generating product molecules from reactant molecules can be formulated as a sequence of graph transformations. To this end, we propose Graph Transformation Policy Network (GTPN) – a novel generic method that combines the strengths of graph neural networks and reinforcement learning to learn the reactions directly from data with minimal chemical knowledge. Compared to previous methods, GTPN has some appealing properties such as: end-to-end learning, and making no assumption about the length or the order of graph transformations. In order to guide model search through the complex discrete space of sets of bond changes effectively, we extend the standard policy gradient loss by adding useful constraints. Evaluation results show that GTPN improves the top-1 accuracy over the current state-of-the-art method by about 3% on the large USPTO dataset. Our model’s performances and prediction errors are also analyzed carefully in the paper.
💡 Research Summary
The paper tackles the fundamental problem of predicting the products of organic chemical reactions, a task essential for synthesis planning and drug discovery. The authors’ central insight is to treat the set of reactant and reagent molecules as a single labeled graph and to view the formation of products as a sequence of graph transformations, each consisting of a “reaction triple” (atom pair (u, v) and a new bond type b). This formulation eliminates the need for handcrafted reaction rules or pre‑extracted templates, which have limited generalization in prior work.
To operationalize this idea, the authors introduce the Graph Transformation Policy Network (GTPN), a unified framework that combines Graph Neural Networks (GNNs) with Reinforcement Learning (RL). The model consists of three main components:
-
Graph Neural Network (GNN) – Performs message passing on the current intermediate graph at each step, producing updated atom embeddings that capture both local connectivity and global chemical context.
-
Node Pair Prediction Network (NPPN) – Scores all possible atom pairs for their likelihood of undergoing a bond change. Two scoring schemes are explored: a local network that uses only the pair’s features, and a global network that incorporates self‑attention across the whole molecule. The global version consistently outperforms the local one, and atom pairs involving reagent atoms are masked out because reagents never change.
-
Policy Network (PN) – Implements a three‑stage decision process for each transformation step:
- Predict a binary continuation signal ξ (continue or stop).
- Sample an atom pair (u, v) from the top‑K highest‑scoring pairs.
- Predict the new bond type b for the selected pair.
A recurrent neural network (RNN) maintains a hidden state across steps, providing temporal context to both NPPN and PN. The whole system is cast as a finite‑horizon Markov Decision Process (MDP) with deterministic state transitions (applying the predicted triple to the graph) and a reward structure that combines immediate sub‑action rewards (correct ξ, correct pair, correct bond) with a final reward for exact product match.
Training uses an Advantage Actor‑Critic (A2C) objective, augmented with several auxiliary losses: a value‑function loss, a binary loss for atom‑pair changes, a length penalty to discourage unnecessarily long sequences, and a top‑K ranking loss that forces the ground‑truth pair to appear among the K candidates. To mitigate the problem of cascading errors after a wrong prediction, the authors introduce a binary mask ζ that nullifies loss contributions after the first incorrect sub‑action, effectively focusing learning on the correct prefix of the action sequence.
Experiments are conducted on two public datasets derived from USPTO patents: a 15k‑reaction subset (USPTO‑15k) and the full USPTO collection (≈1 M reactions). GTPN achieves top‑1 accuracies of 82.39 % on USPTO‑15k and 83.20 % on the full set, outperforming the previous state‑of‑the‑art by roughly 3 percentage points. Detailed error analysis shows that most mistakes stem from (i) selecting the wrong atom pair, (ii) predicting an incorrect bond type, and (iii) generating overly long transformation sequences. The model’s generated triple sequences are interpretable, allowing chemists to trace the predicted reaction mechanism step‑by‑step.
Key strengths of GTPN include: (1) end‑to‑end learning without reliance on expert‑crafted templates; (2) flexibility to handle an arbitrary number of bond changes in any order; (3) the ability to update atom embeddings after each transformation, which is crucial for multi‑step reactions; and (4) a reinforcement‑learning‑driven exploration of a huge, discrete action space. Limitations are acknowledged: the current implementation does not enforce chemical valence constraints during intermediate states, the choice of K (the number of candidate pairs) influences both performance and computational cost, and scaling to very large molecules may become expensive.
In conclusion, the Graph Transformation Policy Network presents a novel, graph‑centric perspective on reaction prediction, demonstrating that reinforcement learning can effectively guide graph‑based models through complex chemical transformations. Future work suggested by the authors includes integrating explicit chemical validity checks into the transition function, developing more efficient candidate‑pair sampling strategies, and extending the framework to predict multiple products or alternative reaction pathways simultaneously.
Comments & Academic Discussion
Loading comments...
Leave a Comment